

3 Ways to Deploy an LLM Endpoint With HuggingFace

If you trained or fine-tuned an LLM, chances are that you now need to deploy it. Deploying an LLM is not as easy as deploying other machine learning models. If the model is set up for text generation, there are a few things that you need to handle:
How is the model generating text: there are a few strategies to try to obtain the “best“ output sequence. We can inject randomness with the multinomial search by setting a temperature. We decode with the beam search strategy to find the best output sequence instead of the best next token. We can use the contrastive search generative to penalize for repetitiveness.
Multiple input requests: The decoding process to generate text can induce a lot of latency when providing a response to the user. When multiple requests pile up, it becomes difficult to handle them separately. An LLM endpoint needs to be able to handle continuous batching to handle decoding multiple requests at once.
Minimizing the decoding time: computing the hidden states within an attention layer can take up to quadratic time complexity ~O(N), but the typical strategy used to minimize latency is to cache the internal keys and queries generated within the attention layers. This is called KV caching. This, along with handling multiple requests and beam search strategies, requires efficient implementation of the KV cache.
Streaming endpoints: the full decoding process can take seconds, and it is often good for the user experience to return the intermediary tokens as the sequence is being decoded instead of waiting for the full process to finish. This implies setting up the endpoint with Server-Sent Events (SSE) instead of simple HTTP requests.
Implementing those capabilities is not a trivial process, and it is often better to make use of the tools already providing those. When it comes to cloud services, there are two broad categories of services that can allow us to deploy an endpoint:
A fully managed endpoint that already implements some of the functionalities described above.
Services that allow us to deploy custom applications.
HuggingFace Endpoints, AWS Bedrock, and Replicate are examples of fully managed endpoint services. It is easy to deploy with them, but they don’t provide a lot of flexibility, can require dependency on third-party providers, and make it more difficult to build multi-service applications.
Deploying a custom application allows more flexibility around the way we deploy it. We can more easily use other services like databases or queues. We can utilize orchestrated services like Kubernetes or AWS ECS. We can use applications-specific services like AWS Elastic Beanstalk or GCP App Engine. However, we still need to find a way to provide all the functionalities described above.
We are going to deploy an LLM in three manners:
Deploying a fully managed dedicated endpoint with HuggingFace
Deploying a custom application with vLLM on HuggingFace Spaces
Deploying an OpenAI-compatible server with vLLM on HuggingFace Spaces
Deploying a fully managed dedicated endpoint with HuggingFace
The Deployment
Deploying a fully managed dedicated endpoint is the easiest way to deploy an LLM, but it doesn't provide a lot of flexibility and can require dependency on a third-party provider. Let's try to do it with HuggingFace! Let's assume that we have trained or fine-tuned a model and want to expose an endpoint. As an example, let's use Microsoft's Phi-3-mini-4k-instruct model. We could do the same thing with our own private model.
If we go to that model's page, we can click on "Deploy," and choose "Inference Endpoints (dedicated)".

This brings us to the HuggingFace Endpoints website. From there, we can choose our model repository, our cloud services, and our machine.
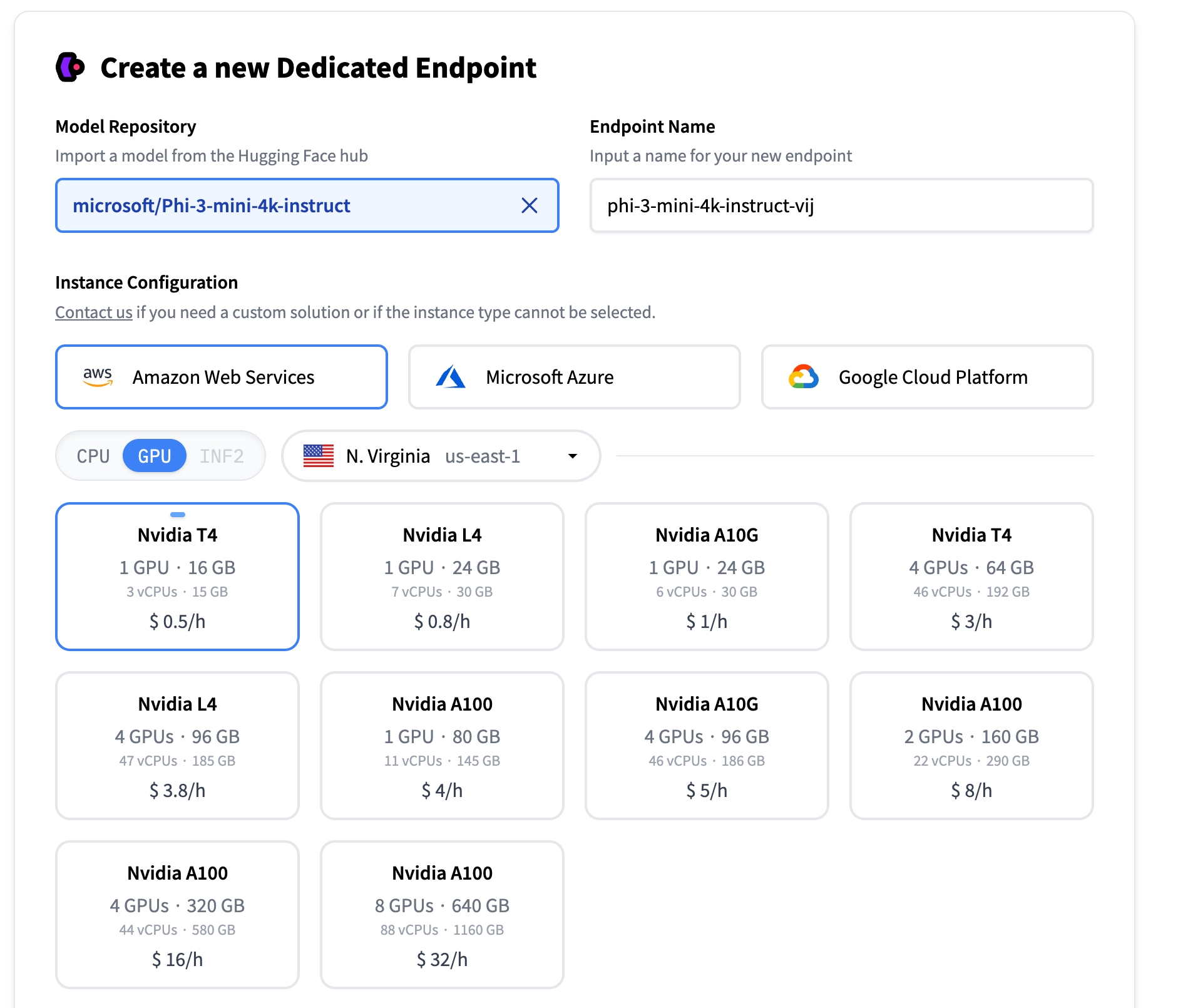
Personally, I made sure to scale to 0 after 15 minutes of inactivity to avoid paying if I forget to spin down the machine. Also, I selected a protected endpoint because it should not be publicly accessible. In real production, we are more likely to need to choose a private endpoint as we are unlikely to need access beyond a VPC.

We can also change the advanced configuration to customize further the endpoint:

Let’s click "create the endpoint". After initialization, the endpoint should be running and we can get the endpoint URL from there:
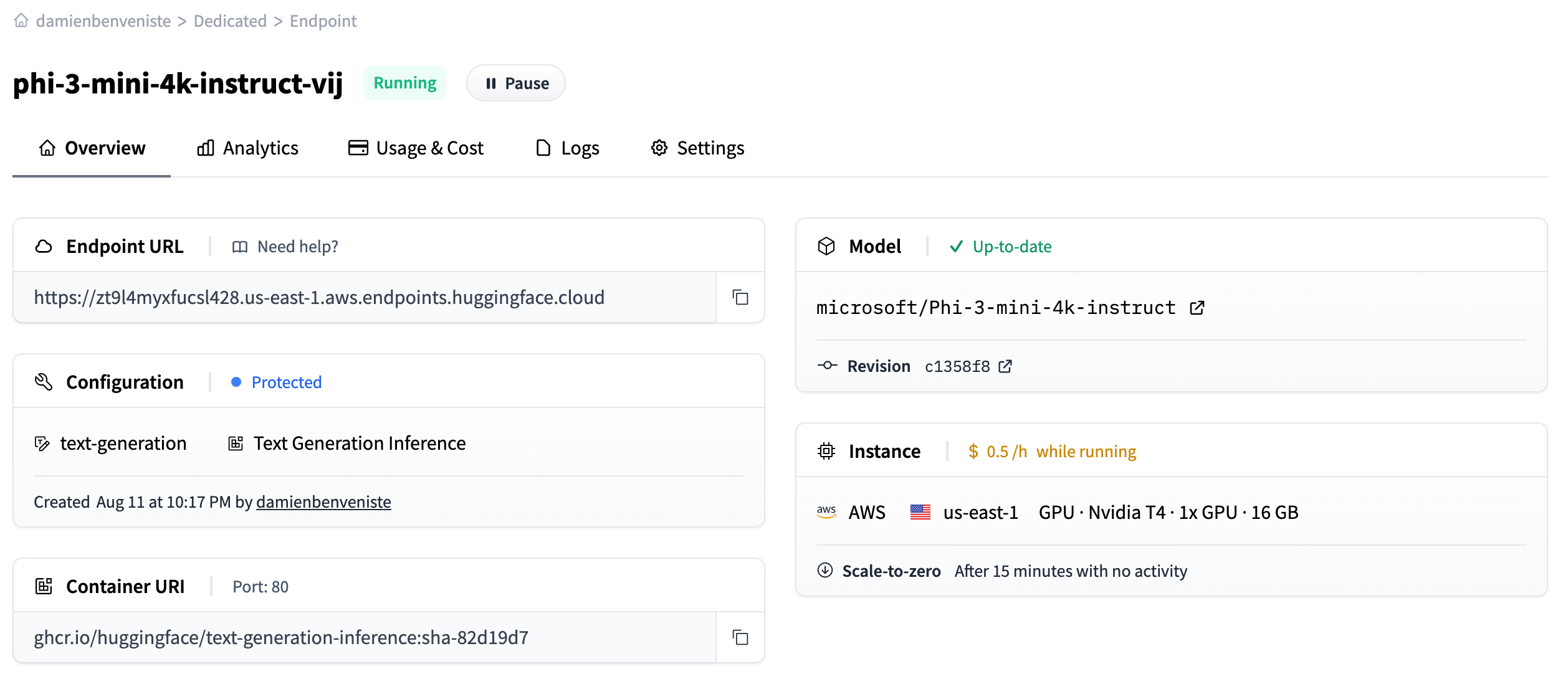
Querying the Endpoint with an HTTP request
We can now hit this API by using the requests package.
import requests
API_URL = "[YOUR ENDPOINT URL]"
headers = {
"Accept" : "application/json",
"Authorization": "Bearer [YOUR HUGGING FACE TOKEN]",
"Content-Type": "application/json"
}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
text = "How are you?"
output = query({
"inputs": text,
"parameters": {}
})
outputHere is an example of a response:
