

AdalFlow: A PyTorch-Like Framework to Auto-Optimizing Prompt for your LLM agent

AI Agent frameworks are becoming just as important as model training itself! I am excited to introduce you to Li Yin. She is the CEO of SylphAI and the founder of AdalFlow, a PyTorch-like open-source library on GitHub that enables developers to build and auto-optimize any Language Model (LM) workflows.
In this guest post, Aria Shi, the Developer Relations lead at SylphAI, walks you through how AdalFlow empowers AI Agent development, highlighting a hands-on example with a LinkedIn Reachout Agent.

Say goodbye to manual prompt engineering. AdalFlow is the all-in-one, auto-differentiative solution for optimizing prompts, whether you’re using zero-shot or few-shot learning. Backed by our state-of-the-art research (LLM-AutoDiff and Learn-to-Reason), our framework achieves the highest accuracy among all automatic prompt optimization libraries.
The rise of large language models has completely changed the way we build applications—whether it’s chatbots, RAG systems, or fully autonomous agents. But as an AI engineer, trying to bring these models into production often feels like stitching together a bunch of experiments, rather than building a stable and reliable system.
We introduce AdalFlow: a PyTorch-like library designed to bring structure, clarity, and optimization to the world of LLM application development. Built as a community-driven project, AdalFlow is uniting AI research and production engineering into a single ecosystem.
Why We Built AdalFlow
Modern AI development faces a paradox. On one hand, researchers push the boundaries of model capabilities with new techniques in prompting, evaluation, and optimization. On the other hand, production teams need reproducibility, scalability, and a way to iterate safely on real-world data.
Most libraries excel at one side of the equation but leave the other underserved. AdalFlow was born to bridge this gap. With 100% control and clarity of source code, it empowers researchers to experiment freely while giving product engineers the tools to build and ship with confidence.
Why AdalFlow Matters
By treating prompts as first-class citizens and introducing LLM-AutoDiff, AdalFlow provides what’s been missing in the LLM ecosystem:
For researchers: A familiar PyTorch-like environment to prototype new prompting and training methods.
For engineers: Production-ready workflows that are debuggable, reproducible, and optimizable.
For teams: A shared framework that unites research and production into one healthy ecosystem.
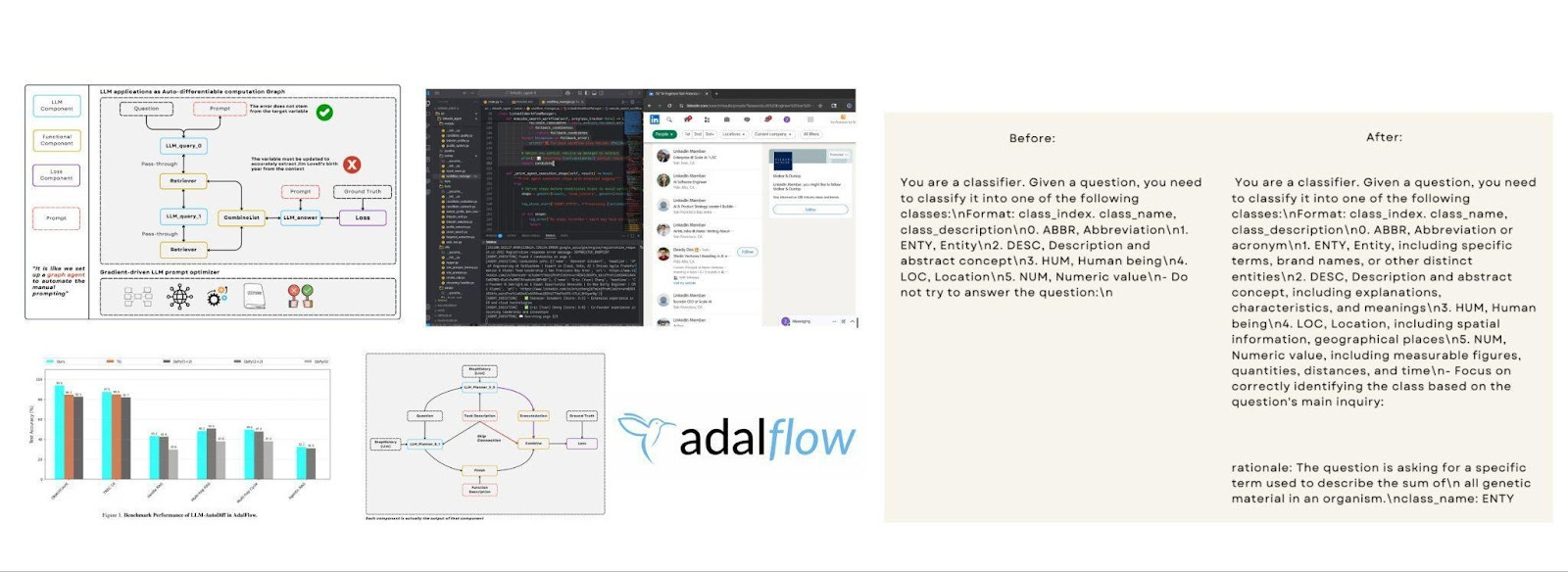
Core Philosophy: Prompt Is the New Programming Language
If PyTorch turned tensors into the lingua franca of deep learning, AdalFlow treats prompts as the new programming primitives.
Every LLM application boils down to structured prompts and their transformations. AdalFlow embraces this reality by making prompt engineering explicit and optimizable. Behind the scenes, it uses the Jinja2 templating engine to let developers define composable prompt structures, ensuring that LLM apps are both modular and debuggable.
Components: The Building Blocks of LLM Workflows
At the heart of AdalFlow lies the Component abstraction. Just as nn.Module became the foundation for PyTorch models, Components unify every stage of an LLM pipeline.
Component: The base class for all workflows. Handles both training (forward) and inference (call) modes, with bicall bridging the two.
GradComponent: Components capable of backpropagation (e.g., Generators, Retrievers).
DataComponent: Lightweight components for formatting and parsing data (e.g., DataClassParser).
LossComponent: Wraps evaluation metrics and enables gradient-like feedback for text optimization.
Example 1: Q&A with Object Counting (Component + DataComponent)
template = r"""<START_OF_SYSTEM_PROMPT>
{{system_prompt}}
<END_OF_SYSTEM_PROMPT>
<START_OF_USER>
{{input_str}}
<END_OF_USER>"""
@adal.func_to_data_component
def parse_integer_answer(answer: str):
numbers = re.findall(r"\d+", answer)
return int(numbers[-1])What’s happening here?
parse_integer_answeris wrapped with@adal.func_to_data_component.This turns a plain Python function into a
DataComponent, which handles structured output parsing.In this case, it ensures the model’s answer ends with a numerical value.
Next, we define a full pipeline:
class ObjectCountTaskPipeline(adal.Component):
def __init__(
self, model_client: adal.ModelClient, model_kwargs: Dict
):
super().__init__()
system_prompt = adal.Parameter(
data="You will answer a reasoning question. Think step by step. The last line should be 'Answer: $VALUE'.",
role_desc="Task instruction for the model",
requires_opt=True,
param_type=ParameterType.PROMPT,
)
self.llm_counter = adal.Generator(
model_client=model_client,
model_kwargs=model_kwargs,
template=template,
prompt_kwargs={"system_prompt": system_prompt},
output_processors=parse_integer_answer,
)
def bicall(self, question: str, id: str = None):
return self.llm_counter(
prompt_kwargs={"input_str": question}, id=id
)ObjectCountTaskPipeline subclasses Component. Inside it, we define:
A Parameter of type
PROMPT, which AdalFlow can later auto-optimize.A Generator (a
GradComponent) that executes the prompt, then passes the raw LLM output through ourparse_integer_answerDataComponent.
The workflow is:
Prompt → LLM Generation → Structured Output Parsing → Final Numerical Answer.
Example 2: Classification with Structured Output (Component + DataClass)
Classification tasks are a perfect showcase of AdalFlow’s DataClass feature.
@dataclass
class TRECExtendedData(adal.DataClass):
question: str = field(
metadata={"desc": "The question to be classified"}
)
rationale: str = field(
metadata={"desc": "Step-by-step reasoning"}, default=None
)
class_name: Literal[
"ABBR", "ENTY", "DESC", "HUM", "LOC", "NUM"
] = field(
metadata={"desc": "The class name"}, default=None
)
__input_fields__ = ["question"]
__output_fields__ = ["rationale", "class_name"]TRECExtendedDataextendsDataClass, which (like Pydantic) gives us schema enforcement.Input: a question.
Output: a rationale (reasoning trace) and a
class_name(final label).
Now let’s plug it into a pipeline:
class TRECClassifierStructuredOutput(adal.Component):
def __init__(
self, model_client: adal.ModelClient, model_kwargs: Dict
):
super().__init__()
# Task description prompt
task_desc_str = adal.Prompt(
template=task_desc_template,
prompt_kwargs={
"classes": [
{"label": l, "desc": d}
for l, d
in zip(_COARSE_LABELS, _COARSE_LABELS_DESC)
]
}
)()
parser = adal.DataClassParser(
data_class=TRECExtendedData,
return_data_class=True,
format_type="yaml"
)
prompt_kwargs = {
"system_prompt": adal.Parameter(
data=task_desc_str,
role_desc="Task description",
requires_opt=True,
param_type=adal.ParameterType.PROMPT,
),
"output_format_str": parser.get_output_format_str(),
}
self.llm = adal.Generator(
model_client=model_client,
model_kwargs=model_kwargs,
prompt_kwargs=prompt_kwargs,
template=template,
output_processors=parser,
)
def bicall(self, question: str, id: Optional[str] = None):
return self.llm(prompt_kwargs={"input_str": question}, id=id)The Prompt defines the system instruction with class definitions.
DataClassParserenforces structured YAML output that matchesTRECExtendedData.Generator (a GradComponent) runs the LLM with prompt + parser.
Output is guaranteed to follow the schema: rationale + class name.
This ensures the model never drifts into free-form answers—it always returns structured classification results.
Example 3: Training With LossComponent
Finally, how do we train or optimize these components? That’s where LossComponent comes in:
eval_fn = AnswerMatchAcc(type="exact_match").compute_single_item
loss_fn = adal.EvalFnToTextLoss(
eval_fn=eval_fn,
eval_fn_desc="exact_match: 1 if str(y) == str(y_gt) else 0"
)AnswerMatchAccis the evaluation metric.EvalFnToTextLosswraps it as aLossComponent, enabling LLM-AutoDiff to optimize prompts automatically during training.
By attaching this to your pipeline, you get a full training loop:
Forward pass → Eval metric → Backward engine → Prompt optimization.
Agents: Reasoning Meets Action
AdalFlow embraces the ReAct paradigm—combining reasoning (plan) with acting (tool use)—to build autonomous, auditable AI systems. An agent reasons about the task, selects tools, executes them, observes results, and iterates until it can deliver a final answer.
Architecture at a Glance
Agent (planner + tool manager)
Handles planning and decision-making via a Generator-based planner, and knows what tools are available and how to call them.Runner (executor + conversation loop)
Orchestrates multi-step execution, tool calling, observation handling, timeouts, and final answer synthesis.
This separation lets you swap or customize planning vs. execution independently.
Execution Flow (ReAct Loop Recap)
Planning – The Agent (Generator planner) analyzes input and proposes the next action.
Tool Selection – Chooses a tool from the registered set.
Tool Execution – The Runner invokes the tool with arguments.
Observation – The result is fed back to the planner.
Iteration – Repeat 1–4 up to max_steps or until confident.
Final Answer – The planner synthesizes the answer (optionally into a structured type).
Minimal, End-to-End Example
1) Define a Tool (callable or FunctionTool)
# Tool: a plain Python callable works, or wrap with FunctionTool for extras.
def calculator(expression: str) -> str:
"""Evaluate a mathematical expression."""
try:
result = eval(expression)
return f"Result: {result}"
except Exception as e:
return f"Error: {e}"2) Build the Agent (Planner + Tools)
from adalflow import Agent, Runner
from adalflow.components.model_client.openai_client import OpenAIClient
agent = Agent(
name="CalculatorAgent", # Agent identifier
tools=[calculator], # List of tools (callables or FunctionTool)
# LLM client used by the planner (Generator-based)
model_client=OpenAIClient(),
model_kwargs={"model": "gpt-4o", "temperature": 0.3},
max_steps=6, # Upper bound for ReAct loops
)What this maps to:
Planner: An internal Generator that decides the next step (think: “reasoning trace”).
ToolManager: The agent’s registry of permitted tools.max_steps: Safety rail to prevent runaway loops.
Model Configuration (Swap Backends Easily)
# OpenAI
from adalflow.components.model_client.openai_client import OpenAIClient
agent = Agent(
model_client=OpenAIClient(),
model_kwargs={"model": "gpt-4o"}
)
# Anthropic
from adalflow.components.model_client.anthropic_client import (
AnthropicAPIClient
)
agent = Agent(
model_client=AnthropicAPIClient(),
model_kwargs={"model": "claude-3-sonnet-20240229"}
)3) Execute with the Runner (Multi-step Orchestration)
# Manages turns, tool calls, observations, and finalization
runner = Runner(agent=agent)
result = runner.call(
prompt_kwargs={"input_str": "Invoke the calculator tool and calculate 15 * 7 + 23"}
)
print(result.answer)
# -> "The result of 15 * 7 + 23 is 128."RunnerResult schema (returned by Runner.call)
# result has:
# - result.step_history: [StepOutput(...)] # Each step’s action + observation
# - result.answer: str | structured type # Final synthesized answer
# - result.error: None | Exception info # Error if something failed
# - result.ctx: dict | None # Optional execution metadataThis is the full ReAct loop in action:
Plan → Select Tool → Execute → Observe → Iterate → Answer.
Advanced Features (Production-Ready)
1) Streaming Execution (Real-Time Updates)
# Pseudocode: actual API may differ slightly in your version.
stream = runner.stream(
prompt_kwargs={"input_str": "Compute 42 * 73 and explain."}
)
for update in stream:
# update contains partial thoughts, tool calls, observations, etc.
print(update)Use streaming to surface live reasoning/tool progress in UIs.
2) Human-in-the-Loop (Permission Management)
from adalflow.permissions import PermissionManager
class MyPerms(PermissionManager):
def approve(self, tool_name: str, args: dict) -> bool:
# Example policy: only allow calculator; prompt user otherwise
return tool_name == "calculator"
agent = Agent(
name="GuardedAgent",
tools=[calculator, search_tool],
model_client=OpenAIClient(),
model_kwargs={"model": "gpt-4o"},
permission_manager=MyPerms(), # <- Every tool call can be inspected/approved)Great for tools that hit external systems (files, emails, APIs).
3) Custom System Templates (Planner Behavior)
custom_role_desc = """
You are a careful, step-by-step data analyst.
When you use a tool, explain why and what you expect to get.
"""
agent = Agent(
name="DataAnalyst",
# Custom planner persona and guardrails
role_desc=custom_role_desc,
model_client=OpenAIClient(),
model_kwargs={"model": "gpt-4o", "temperature": 0.2},
)4) Tracing (Observability)
# Configure tracing once (destination: console, file, or tracing backend)
from adalflow.tracing import enable_tracing
enable_tracing(project="adalflow-agents-demo")
result = runner.call(prompt_kwargs={
"input_str": "Use the calculator for 88*19."
})
# Inspect step_history, tool IO, latency, errors, etc.Agent Summary:
Agent = Reasoning + Tool selection (Generator-based planner + ToolManager)
Runner = Controlled execution loop (steps, tools, observations, final answer)
Tools = Safe, permissioned extensions to the agent’s capabilities
Production = Streaming, human approvals, tracing, structured outputs
Real-World Use Case: LinkedIn Recruitment Agent with AdalFlow
Hiring top talent is one of the most resource-intensive parts of building a company. Recruiters spend hours scrolling LinkedIn, opening profiles, copying notes, and crafting outreach messages.
What if we could automate that entire workflow—turning hours of manual searching into minutes of AI-assisted sourcing?
That’s exactly what we built using AdalFlow’s Agent + Runner architecture combined with browser automation via Chrome DevTools Protocol (CDP).
✨ Before vs. After
Traditional Recruiting Workflow (Manual)
❌ BEFORE: 2–3 hours per role
1. Navigate to LinkedIn people search
2. Type in “Product Manager, San Francisco”
3. Scroll endlessly, click into profiles
4. Skim experience, education, skills
5. Take notes in spreadsheets
6. Write & send DMs manually
Automated Workflow with AdalFlow (Agentic)
✅ AFTER: 10 minutes per role
1. Run: linkedin-agent --query “Product Manager” --limit 10
2. Agent plans and executes:
- Smart search strategy
- Extract profiles via browser automation
- Evaluate candidates with scoring models
- Draft personalized outreach messages
3. Get structured output: JSON/CSV with names, titles, LinkedIn URLs, evaluation scores, outreach drafts. Recruiters get to focus on talking to people, not copy-pasting data.
How It Works — Global State Architecture
We structured the solution around a global state shared between tools. Each tool contributes partial data (search results, profiles, evaluations, outreach drafts), which the Agent combines into a full pipeline. Agent combines into a full pipeline.
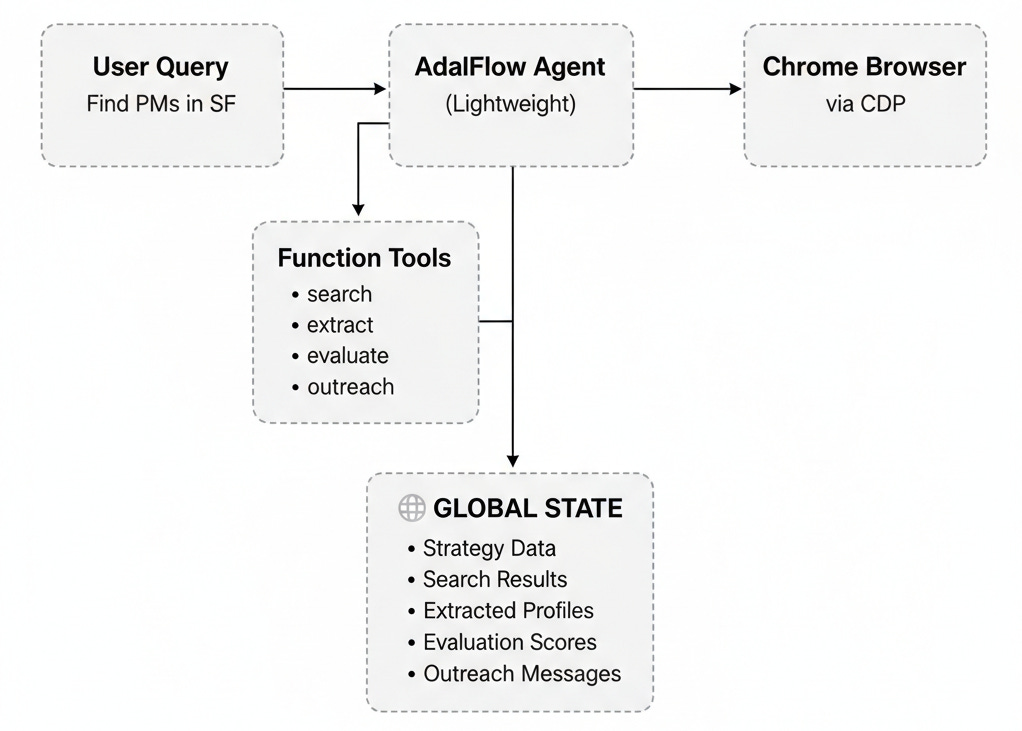
Implementation with AdalFlow
We implemented the LinkedInAgent by encapsulating:
Agent → Planner + Tools (search, extract, evaluate, outreach)
Runner → Execution loop with error handling and logging
class LinkedInAgent:
"""
LinkedIn recruitment agent powered by AdalFlow.
- Encapsulates Agent + Runner
- Provides default recruitment tools
- Supports both sync call() and async acall()
"""
def __init__(
self,
model_client: Optional[OpenAIClient] = None,
model_kwargs: Optional[Dict[str, Any]] = None,
max_steps: Optional[int] = None,
role_desc: Optional[str] = None,
**kwargs,
):
# Defaults
model_client = model_client or OpenAIClient()
model_kwargs = model_kwargs or {
"model": "gpt-4o", “temperature”: 0.3
}
max_steps = max_steps or 6
# Recruitment workflow tools
self.tools = [
# 1. Search LinkedIn via CDP
SmartCandidateSearchTool,
# 2. Extract structured profile data
ExtractCandidateProfilesTool,
# 3. Score candidates
CandidateEvaluationTool,
# 4. Draft personalized outreach
CandidateOutreachGenerationTool,
# 5. Persist results
SaveOutreachResultsTool,
]
# Agent role description (personality / instructions)
role_desc = role_desc or "You are a recruitment assistant that sources and evaluates LinkedIn candidates."
# Initialize Agent + Runner
self.agent = Agent(
name="LinkedInRecruiter",
tools=self.tools,
model_client=model_client,
model_kwargs=model_kwargs,
max_steps=max_steps,
role_desc=role_desc,
**kwargs,
)
self.runner = Runner(agent=self.agent, max_steps=max_steps)
def call(
self, query: str, context: Optional[Dict[str, Any]] = None
):
return self.runner.call(prompt_kwargs={"input_str": query})
async def acall(
self, query: str, context: Optional[Dict[str, Any]] = None
):
return await self.runner.acall(
prompt_kwargs={"input_str": query}
)Full Workflow Execution
Here’s how we stitch the agent into a production workflow:
def execute_search_workflow(
self, progress_tracker=None) -> List[Dict[str, Any]]:
logger = get_logger()
logger.set_workflow_context("workflow_main", "initialization")
log_phase_start("WORKFLOW_START", f"Target: {self.limit} candidates for {self.query} in {self.location}")
candidates = []
try:
log_info("🤖 Initializing LinkedIn agent...")
agent, user_query = self.initialize_agent()
if progress_tracker:
progress_tracker.start_workflow()
# Run full pipeline
result = agent.call(query=user_query)
self._print_agent_execution_steps(result)
# Collect data from global state
from ..core.workflow_state import get_complete_workflow_data
workflow_data = get_complete_workflow_data()
candidates = self._build_complete_candidate_data(workflow_data)
log_info(f"✅ Found {len(candidates)} candidates")
return candidates
except Exception as e:
log_error(f"❌ Workflow failed: {e}")
return candidatesExample Output
After running:
linkedin-agent --query “Product Manager San Francisco” --limit 10We get structured results like:
[
{
“name”: “Alex Chen”,
“title”: “Senior Product Manager @ Stripe”,
“location”: “San Francisco Bay Area”,
“profile_url”: “https://linkedin.com/in/alexchen”,
“score”: 0.92,
“outreach_message”: “Hi Alex, I came across your experience at Stripe...”
},
{
“name”: “Maria Lopez”,
“title”: “PM, Growth @ Airbnb”,
“location”: “San Francisco Bay Area”,
“profile_url”: “https://linkedin.com/in/marialopez”,
“score”: 0.88,
“outreach_message”: “Hi Maria, your background in growth product design really stood out...”
}
]
============================================================
WORKFLOW COMPLETION SUMMARY
============================================================
Success: ✅ Yes
Total Candidates: 2
Duration: 68.8 seconds
Session: 20250909_220617
Log Files:
• Main: logs/workflow_20250909_220617.log
• Debug: logs/debug_20250909_220617.log
• Agent Steps: logs/agent_steps_20250909_220617.log
• Errors: logs/errors_20250909_220617.log
============================================================
🏁 MAIN ✅ COMPLETED - Processed 2 candidates
[RESULTS] ✅ Recruitment workflow completed!
[RESULTS] 📊 Final result: Successfully processed 2 candidates

Looking Ahead
As the LLM landscape evolves, frameworks like AdalFlow will become the backbone of application development. Just as PyTorch accelerated deep learning, AdalFlow has the potential to democratize LLM app building—from chatbots to agents to beyond.
If you’re excited about shaping the future of AI workflows, the project is open-source and community-driven. Whether you’re an AI researcher, product engineer, or just curious about building smarter applications, now’s the time to get involved.
🚀 AdalFlow isn’t just another library. It’s a paradigm shift in how we think about programming with language models.
This is totally true. I think 2026 is going to see us go full agentic. Agentic frameworks and workflows. Hopefully more tooling like MCP als gets a security upgrade!
A great overview of AdalFlow.
However since AdalFlow is one of a number of excellent frameworks and methods for tackling Optimization including GEPA and Prompt-MII I’m wondering if you’d be willing to compare and contrast it with these other methods.
Specifically why should I choose AdalFlow over GEPA (which I’ve been using) and Prompt-MII (which I’m investigating)? Where does it shine? Where is it lacking? Etc.
Thank you,
Christopher