

AutoML Taken to the Next Level!

“Finding” the right model for a specific learning task consists of searching for the right model type, optimizing for the right hyperparameters, and learning the model parameters. Effectively we have to search the model space, the hyperparameter space, and the parameter space. Optimizing the parameter space is referred to as “learning“, “statistical learning“, or “training“. The automation of searching the model and the hyperparameter spaces is often referred to “AutoML”. There are many optimization techniques related to AutoML. Today we dive into some of the hottest research fields in AutoML: Meta-Learning and Neural Architecture Search! We cover:
Meta-Learning
Neural Architecture Search: SuperNets
Download the Automated Machine Learning book
Learn more about AutoML

Meta-Learning
Do we need to train a model to understand how good it would be? Can't we "guess" its potential predictive power just based on its architecture or training parameters? That's the idea behind Meta-Learning: learn the patterns that make a model better than another one for some learning task!
The concepts are simple: featurize the learning meta-data, train a model to predict performance metrics with those features, and use that meta-model to search the optimization space when tuning another model.
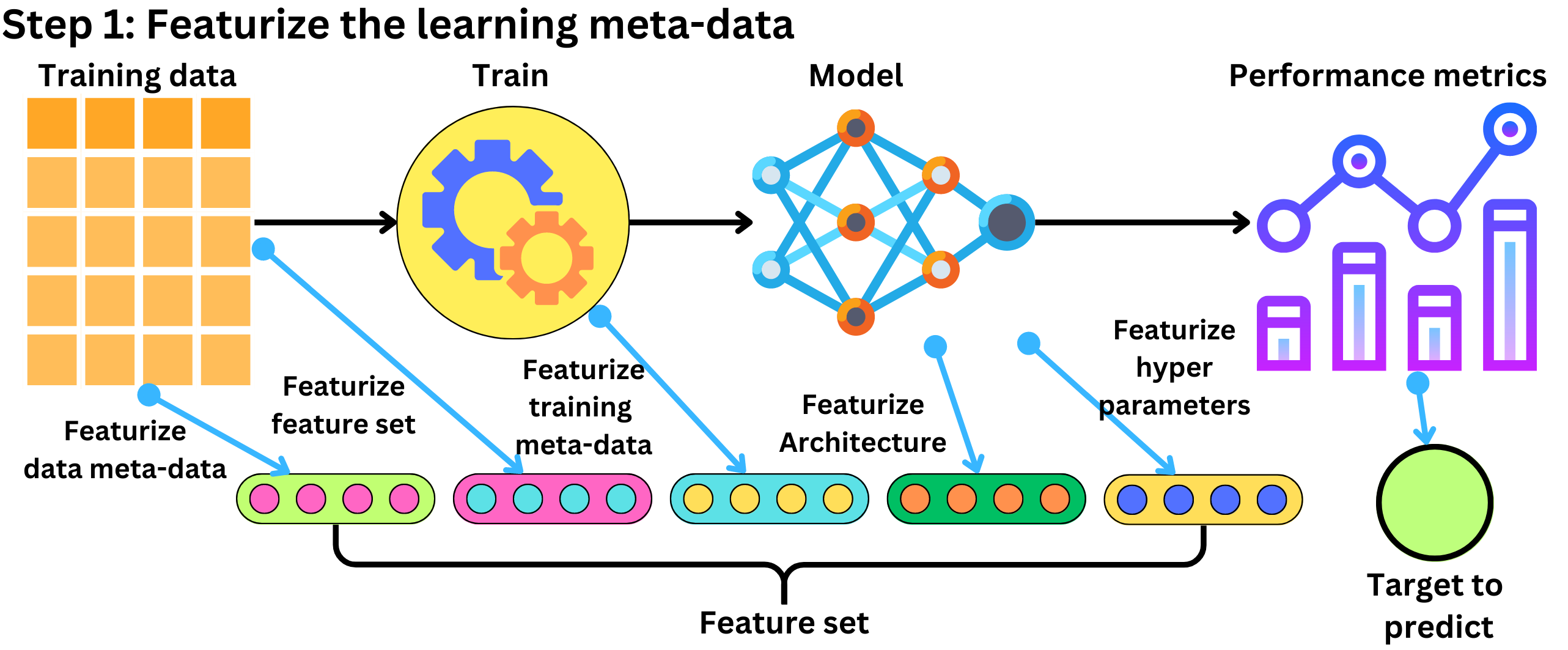
Featurizing the learning meta-data means that we create features from the training settings. We can capture the architecture of a network as a one-hot encoded feature vector. We can capture the different hyperparameter values and the training parameters such as the number of epochs or the hardware (CPU / GPT). We can extend the meta-feature space to the dataset used for training. For example, we can include a one-hot encoded representation of the features used and the number of samples that were used (this will allow you to perform feature selection as well). We could capture anything that could influence the learning and the resulting performance metrics. The more meta-features you include, the greater the space you will able to optimize over, but also the more difficult it will be to learn the target variable correctly.

Now that you can featurize training experiments, you can train a meta-learner to learn the relationship between the training parameters and a performance metric. Because you will most likely have very few samples, your meta-learner should be a simple model such as a linear regression or a shallow neural network. You could even make the meta-learner agnostic to the specific training data by comparing 2 models instead. Let's say you have 2 models L1 and L2 with performance metrics p1 and p2 measured on the same validation set. You can train a meta-learner M that learns to predict the relative improvement from model L1 to model L2:
Instead of
This tends to be a better approach as it mitigates the variation of measured performance metrics on different validation sets.

Now that you have a model that understands the relationship between the learning meta-data and the performance metrics, you can search for the learning meta-data that maximizes the performance metric. Because you have a model, you can quickly assess billions of different learning meta-data in seconds and converge to the optimal meta-features. The typical approach is to use Reinforcement Learning or supervised fine-tuning. Fine-tuning means that if you have specific training data or if you want to focus on a subset of the search space, you can train a couple of new models on that data and get the resulting performance metrics. This will allow you to fine-tune the meta-learner to get a more optimal optimization search.
This is a good read to get started on the subject: "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks".
Neural Architecture Search: SuperNets
What is the difference between the model parameters and the model hyperparameters? The hyperparameters are the parameters we cannot co-train with the other parameters through the statistical learning optimization used to learn from the data. So we need to alternate between learning the parameters through minimizing the loss function and tuning the hyperparameters through different optimization techniques. And that can be computationally very expensive! Neural Architecture Search is about tuning the network architecture as hyperparameters and the search space dimension can be as big as 1040!
