

Data Scientists and their Business Stakeholders: How to reduce the risk of conflict

Today I am excited to present to you a special guest post by Fariborz, Nanne, and Max who wrote a piece on how to reduce conflict between data scientists and their business stakeholders while they worked at the ING Bank. At the time, Fariborz and Nanne were data scientists and Max was their chapter lead.
Building a successful AI product needs all hands on deck. Especially, the data science (DS) team and the business side have to collaborate well. Many times AI products fail simply due to conflicts between these two stakeholders.
We believe that the risk of conflict is highest when beginning a project. This is when uncertainty is at its highest. We refer to this stage of data science workflow as disruptive research.
To mitigate this risk, we propose a two-fold solution:
Educating business stakeholders about disruptive research and its uncertainties.
Nurturing trust between the DS team and their business stakeholders.

Motivation
Let us assume the following scenario: the goal is to develop a churn prediction algorithm for a payment product. The data science (DS) team breaks down the work into the following parts: data understanding, data preparation, modeling, evaluation, deployment, and business understanding (“Managing Data Science“). The DS team adheres to the SCRUM way of working. They plan to understand and prepare the data in the next two weeks. Two weeks have passed, and the DS task is not complete. The data are complex, and the team had a wrong estimation of how long it would take to prepare it. For the next sprint, they make another estimation to finish the same task. Two more weeks passed, and the task is still not done; unforeseen problems showed up in the data collection. The business stakeholders (and possibly the PM) are non-technical people and not intimately familiar with how data is processed, or algorithms are developed. The project is delayed and the expected results are not delivered. Business stakeholders become anxious. And this is when the risk of conflict is highest.
Is the DS team bad at time estimation, or are they set up for failure? We believe that the leading cause of this conflict is something more profound. This contribution identifies two root causes:
Misconceptions about the DS work, and
Lack of trust between the DS team and their business stakeholders.
To address these issues, we first establish the nature of the DS work and identify at which stage conflicts can arise. Then we discuss how to grow and nurture trust.
The nature of data science work
In the previous example, the DS team was set up for failure. The task of understanding and preparing the data is so uncertain that it was impossible to estimate when it will be done. But that begs the question, are all aspects of the DS work highly uncertain to the extent that they are unplannable? To answer this question, let us dissect the DS work. Generally speaking, the lifecycle of the DS work has three stages: disruptive research, productionalization, and incremental research — see Figure 1. In this section, we introduce each stage. And we identify the one in which conflicts usually arise. We skip the productionalization stage as it is discussed in literature such as “Putting Machine Learning Models into Production“. This stage is about taking a minimum viable algorithm and deploying it to production.
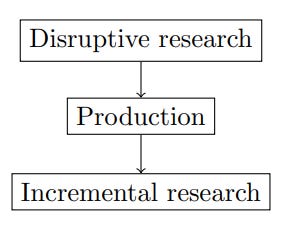
Two research stages
We argue that DS research is about developing algorithms to solve specific business problems (Appendix A). We divide this endeavor into two parts: incremental and disruptive research. Incremental research improves existing algorithms, while disruptive research develops new ones.
Incremental research
Incremental research usually improves an existing algorithm. Therefore, it starts with a solid background: a well-defined problem, a fair understanding of the data, and a strong baseline. For this reason, scrum usually works well when doing incremental research. We make reference to available literature, such as “Don't Just Track Your ML Experiments, Version Them“.
Disruptive research
In contrast to incremental research, disruptive research usually starts with nothing but a business idea. At the start, the problem is not well-defined. It is not clear which data to use and which metric to optimize. As a result, disruptive research is a highly uncertain endeavor; therefore, it is hardly plannable. A new DS project can be like mapping out unknown land: One does not know what lies ahead.
The concept that we refer to as disruptive research is implicitly mentioned in the literature. For instance, Godsey (“Are we there yet?“) mentions: “the need to acknowledge which parts of your project have the most uncertainty and to make plans to mitigate it.”. He later discusses the need to modify execution plans in process in “Think Like a Data Scientist“.
Why conflicts arise during disruptive research
Circling back to the example of the motivation section, the task of understanding and preparing the data is a part of disruptive research. That is why the DS team consistently failed to promise a good estimation for its completion.
Most of the conflicts arise during this stage. As discussed in the previous section, disruptive research is highly uncertain. The source of this uncertainty has three dimensions:
Feasibility (data and modeling),
Desirability, and
Viability.
Feasibility: At the early stages of disruptive research, we have little understanding of data availability and completeness. As a result, it is difficult to choose an adequate modeling technique.
Desirability: At this stage desirability is also unknown. Are users actually willing to use the proposed solution?
Viability: And finally, the viability is not certain. It highly depends on the solution and its desirability.
During disruptive research, feasibility, desirability, and viability are highly uncertain. For this reason, it is usually impossible to estimate how long or how much effort it will take to deliver the final results.
Scrum, the de facto framework for managing uncertain processes, requires the estimation of results one can achieve in a sprint (usually two weeks). However, we argue that this becomes impossible when there is so much uncertainty. One can make plans of which experiments to perform but cannot guarantee the outcome. This can be especially problematic in a high-pressure working environment. Sticking to scrum in a very literal way results in making unkeepable promises. In doing so, scrum can become a source of conflict rather than a solution.
A two-fold solution
To develop a healthy relationship between the DS team and its business stakeholders, we must first establish a common understanding of the disruptive research process.
Part 1: Disruptive research process
Developing an algorithm can be seen as a three-stage process, as depicted in Figure 2. The first stage is to check if the outcome is probably feasible, desirable, and viable. The second stage is to set up a research environment. And the last one is to develop the algorithm. In the following sections, we demonstrate this process in more detail.
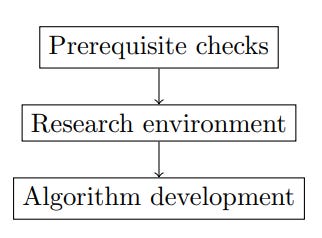
Meeting feasibility, desirability and viability prerequisites
Making DS products can take several months. Hence, before any commitment, it is imperative to check if the project has a fair chance of success.
Doing so is not trivial. However, checking if we can fail early is straightforward. This is done through some initial checks: desirability, feasibility, and viability checks.
Desirability: Interviewing end-users is an excellent way to assess if a product is desirable. For instance, during an interview, one can show end users a mock-up user interface that shows the algorithm’s results. If the end-user is confident that such results are useless, then there is little point in going down this path.
Feasibility: To check if an idea is (un)feasible, the DS team can check if the simplified version of the problem is solvable by hand. For instance, suppose the DS team wants to predict stock prices one week in advance. They can take one stock and see if they could have predicted its today’s price one week ago. They probably fail to make an accurate prediction. Therefore this task is unfeasible.
Viability: The viability of an algorithm covers many topics. For instance, an algorithm should perform within legal, ethical, and compliance constraints. Or, using a user’s geolocation data without their consent is unethical and illegal. Or, if important stakeholders are not on board, the project is probably not viable. Another issue may be: are the right people available for the job?
By doing these checks, we ensure that we know the stakeholders, understand end-user pain points, assess the availability and the quality of data, and educate ourselves regarding the subject matter. This helps failing early. It also helps when building a research environment.
Building a research environment
Algorithm development has a set of requirements:
A business-aware problem statement,
Business-aware evaluation metrics,
Access to the right subject matter experts, and
Access to a data warehouse that contains curated data and a computing environment for modeling.
We refer to the collection of these requirements as the research environment. Before developing an algorithm, the DS team builds this environment. And in the future, if need be, they enrich it.
At the beginning, when there is little understanding of the problem, the team has to deal with the issue of a cold start. For instance, it is unclear how comprehensive the problem statement is, which data to use, and how to build and evaluate the algorithm. Initially, the DS team should build a baseline algorithm to deal with this cold start. The goodness of this algorithm is unimportant. The goal is to produce a simple end-to-end algorithm, i.e., from the data to the metrics.
Building this algorithm creates an initial version of the research environment. Specifically, the DS team consults stakeholders to devise an initial version of the problem statement and evaluation metric. Then, the DS team (quite possibly with the help of engineers) builds a database containing the datasets they initially perceive as required and starts a computing cluster. The DS team can develop a more advanced algorithm using this environment. And enrich it if need be.
Algorithm development process
Developing an algorithm is an iterative procedure that resembles the scientific method. Broadly speaking, the procedure is as depicted in Figure 3.

Here we go through these steps with a detailed example of forecasting sales. Devising a hypothesis is about coming up with conjectures through endeavors such as consultation with subject matter experts, literature study, explanatory data analysis, and getting intuitions from outcomes of previous experiments.
For example, through consultation with subject matter experts, the DS team uncover that promotion campaigns impact sales. The literature study informs them that autoregressive models are suitable for time series forecasting. The explanatory data analysis suggests that the sales data is quarterly seasonal. With these conjectures, the DS team forms a hypothesis, essentially the blueprint for an algorithm.
The DS team then operationalizes the hypothesis by implementing the new algorithm and testing it. For instance, they might develop an autoregressive model that leverages sales seasonality. And they backtest it using an out-of-time validation scheme. While backtesting might suffice here, in other scenarios, one might need to run an online controlled experiment (e.g., A/B testing). In terms of metrics, the DS team could strive to optimize one metric (e.g., number of sales) while ensuring others do not cross a given threshold.
The algorithm is deployed to production if the minimum business requirements are met. Otherwise, the DS team draws conclusions from their experiments and iterates. These conclusions, together with the previous conjectures, help the DS team devise a new hypothesis. For instance, the DS team could realize that the autoregressive model fails to address outliers. So they could decide to use another type of model. Developing another model, ideally, takes only a couple of days. For this reason, we refer to these iterations as short-term, as depicted in Figure 3.
An iteration can also take a long time. These are the ones that require updating the research environment. For instance, the DS team could realize that while the algorithm forecasts an increase in sales, sales drop. When investigating the reason, the DS team figures out that the shops ran out of stock. For this reason, they conclude that they need warehouse data as well. Acquiring, understanding, cleaning, and processing warehouse data could lead to weeks of work. For this reason, we refer to these iterations as long-term, as depicted in Figure 3. Before committing to these long-term iterations, having a go/no-go session is a good idea. In this session, the effort to do the iteration is compared against the value of the potential outcome. If the return on investment is (too) low, the project can be stopped.
Once the algorithm satisfies the basic requirements of the business, it is deployed to production. And this marks the end of disruptive research.
Part 2: Nurturing trust between the DS team and its business stakeholders
Let’s say the DS team and its business stakeholders are playing a game. In this game, each player has two moves. The DS team can either do incremental research or disruptive research. And its business stakeholders can either ask for time-boxed delivery of results (similar to the SCRUM way of working) or an update on the research progress.
Conflict is at its highest when the DS team is doing disruptive research and its business stakeholders ask to time-box results delivery. And constructive collaboration happens only in two scenarios:
The DS team is doing incremental research and its business stakeholders ask to time-box delivery of results
The DS team is doing disruptive research and its business stakeholders ask for research updates
The second scenario requires trust. The business stakeholders should trust that the DS team does its best to make the disruptive research successful or stop it as soon as possible. Nurturing trust is a well-studied field. As suggested by Trust Edge (“The 8 Pillars of Trust”), trust has eight pillars. Here we translate some of these pillars into the data science world. For each pillar, we suggest several best practices. These are mainly based on our own experience.

Delivery of (intermediate) results
Delivering working algorithms that solve business problems is the ultimate means of establishing trust. However, as discussed in Section above, the development of such algorithms is not a linear process. As depicted in Figure 3, at the end of each iteration, there are three possibilities. Aside from the algorithm being adequate, two other scenarios could happen.
First, the DS team could conclude that its attempts are futile and suggest stopping the project. In this case, the DS team should make this decision as soon as possible and avoid going down rabbit holes. Quickly stopping impractical projects is a valuable result. It reduces costs. It also allows the DS team to tackle other problems that might be more feasible. Nevertheless, the DS team should help business stakeholders understand the logic behind this decision.
Second, the DS team concludes that they need another round of iteration. At this point, the DS team might be tempted to quickly start the next iteration hoping that in this round, they will manage to develop a working algorithm. Based on our experience, it is best to first document and present (intermediate) findings and results.
In both scenarios, documenting and presenting findings helps establish trust. In addition, such documents serve as reference points for stakeholders and the DS team.
Transparency of research
People trust what they can understand. Therefore, the research progress should be made as transparent as possible. Transparency comes with documenting and presenting findings. There are several ways to document the research progress. Documentation could be in the form of a formal report, a curated Jupyter notebook containing analysis results, presentation slides, or a mind map that summarizes the status of analysis results. We refer to this mind map as the analysis tree.
Let us illustrate the analysis tree using Figure 5. The DS team starts with the orange node in the center which contains the ultimate goal. Each node represents an analysis and can branch out into several other nodes. Some parts of the tree have deep branches which are analyses that the DS team deep-dived into, while others have a conclusion as their leaf which are the analyses that are concluded.

Research plan and its execution
“The implications and recommendations should be logical, warranted by the findings, and explained thoroughly, with appropriate caveats” (“Standards for High-Quality and Objective Research and Analysis”).
Unclear research methodology and execution diminish trust. The DS team should therefore develop a research methodology upfront. Developing research methodologies is a well-understood field. The DS team can write this methodology in the format of an analysis tree or a formal report that contains a planned analysis. To avoid verbosity, we refer to “What is research methodology?“.
Execution of disruptive research is mostly about the correctness of the computer code and proper analysis of findings (see Wikipedia). Software engineers write unit tests to validate the correctness of computer code (“3 ways of achieving code correctness“). However, proper analysis of findings is more needed compared to code correctness. For example, let us assume that the DS team is developing a fraud detection algorithm. Among fraudsters, the model has an accuracy of 98%. Among others, the model makes mistakes once per hundred clients. There is one fraudster among a hundred clients. In this scenario, if the model identifies a client as a fraudster, there is only a 50% chance of it being correct (“Bayes’ Theorem, Clearly Explained with Visualization“). Analysis, as such, ensures the quality of disruptive research execution.
Regular updates
“Trust is consistency over time”, according to Jeff Weiner. We suggest regular analysis updates to become more consistent over an extended period. We divide these updates into two categories:
(Bi-)weekly informal updates where the DS team presents their research progress to their business stakeholders. These sessions are strictly informative. Since the information at this stage is tentative, we advise against making impactful decisions based on these presentations or attempting to (strongly) influence the direction of the research at this point. This ensures that the DS team has ample autonomy during an iteration of disruptive research.
Go/no-go sessions with stakeholders at the end of each iteration, according to Figure 3, or at most every quarter. In these sessions, the DS team and their stakeholders decide to stop the project or to continue (e.g., allocate more research time or put the model in production). Stopping a project is not a failure but logical conclusions of the results obtained.
The DS team should note that the primary audience of these updates is not data scientists. For this reason, the DS team should adjust the presentation accordingly.
Communication
“If there is no communication, there can be no trust”, Simon Sinek.
The communication between the DS team and their business stakeholders is a two-way street. The DS team educates them regarding the DS way of working and the uncertainties involved. This allows them to understand that the path to developing a working algorithm is nonlinear and highly uncertain. As a result, (s)he can level her expectations and that of the stakeholders. In turn, they educate the DS team regarding business requirements and their limitations.
Developing an effective communication line is never a straightforward endeavor. We have found that regular retrospective sessions go a long way in the betterment of nurturing and tuning it.
Conclusion
We have identified that the root cause of conflict between the PM and the DS team is a misconception regarding DS work and a lack of trust. To address the first issue, we have discussed the nature of the DS work, particularly the inherent forms of uncertainty and how these affect algorithm development. And to address the latter, we have discussed ways to nurture trust.
We, however, did not propose a way of working framework. Making such a framework remains for future work.
About the authors
Fariborz Ghavamian

He is currently a data science team lead at Digikala. He formerly worked as a data scientist at ING Bank and holds a PhD from the Delft University of Technology. LinkedIn
Nanne Aben
His background is a mix between computer science (BSc & MSc @ Delft University of Technology), machine learning in cancer research (PhD @ Netherlands Cancer Institute), and building data products (data scientist @ ING and machine learning engineer @ Kaiko).
Great article!
Really great stuff, I'll share it on Twitter next week; useful takeaways for all