

Deep Dive: How to Build the TikTok Recommender System End-to-End!
Machine Learning System Design

The TikTok recommender system is widely regarded as one of the best in the world at the scale it operates at. It can recommend videos or ads and even the other big tech companies could not compete. Recommending on a platform like TikTok is tough because the training data is non-stationary as a user's interest can change in a matter of minutes and the number of users, videos, and ads keeps changing. In this deep dive, we cover the following:
The overall architecture
The candidate generation stage
The Deep Retrieval model
Beam search for inference
How to rank
Training the model
Fine ranking stage
Multi-gate Mixture of Expert
Correcting selection bias
Collisionless hashing
The Cuckoo Hashmap
Dynamic size embeddings
Sampling the data for offline training
Sampling paradigm
Correcting the probabilities
Real-time streaming engine for online training
The typical recurrent training process
The TikTok online training process
Streaming engine architecture

The overall architecture
The recommender system follows a typical multi-stage process but distinguishes itself by how each component is approached.
The process is as follows:
A user is on the TikTok application and needs its video feed populated.
The request is sent to the TikTok service.
The TikTok service requests a feed ranking from the recommendation engine.
A first stage will select a set of relevant video candidates for that user. TikTok has hundreds of millions of videos and that stage will select ~100 out of those. This candidate generation stage is composed of a Deep Retrieval model and a simple linear model.
The second stage is a fine ranking of the resulting candidates such that the most interesting videos are at the top of the list.
The resulting list is sent to the user.

Typically, candidate generation needs to be very fast considering the number of existing videos, while fine ranking is slower but deals with fewer candidates.
Candidate generation stage
The Deep Retrieval model
Model overview
A typical approach to candidate generation in recommender systems is to find features for users that relate to the features of the items. For example, in a case of a search engine, a user that lives in New York and that is looking for restaurant is most likely looking for those in New York. So we could potentially discard websites that relate to restaurants in other countries filtering searches beyond New York. We could look at a latent representation of the user and find item latent representations that are close using approximate nearest neighbor search algorithms. These approaches require us to iterate over all the possible items which can be computationally expensive. TikTok has hundreds of millions of videos to choose from.
TikTok does things slightly differently. What about if we had a model that takes as input a user and returns candidates for that user?
As a result, this approach is potentially much faster than searching over all possible videos. The process can be summarized as follows:
A user ID is converted into its latent representation from an embedding table.
The Deep Retrieval model learns the latent representations of related items.
The item representations are mapped back to the items themselves.

How does the Deep Retrieval model generate those vector representations? The Deep Retrieval model is a matrix of D columns each having K nodes. Each path from left to right in that matrix can be indexed by the indices of the nodes in each column. So in the path [2, 3, 1] for example, we start at node 1 of the first column, we move to node 3 of the second column and finish at node 1 of the third and last column.
How to encode items
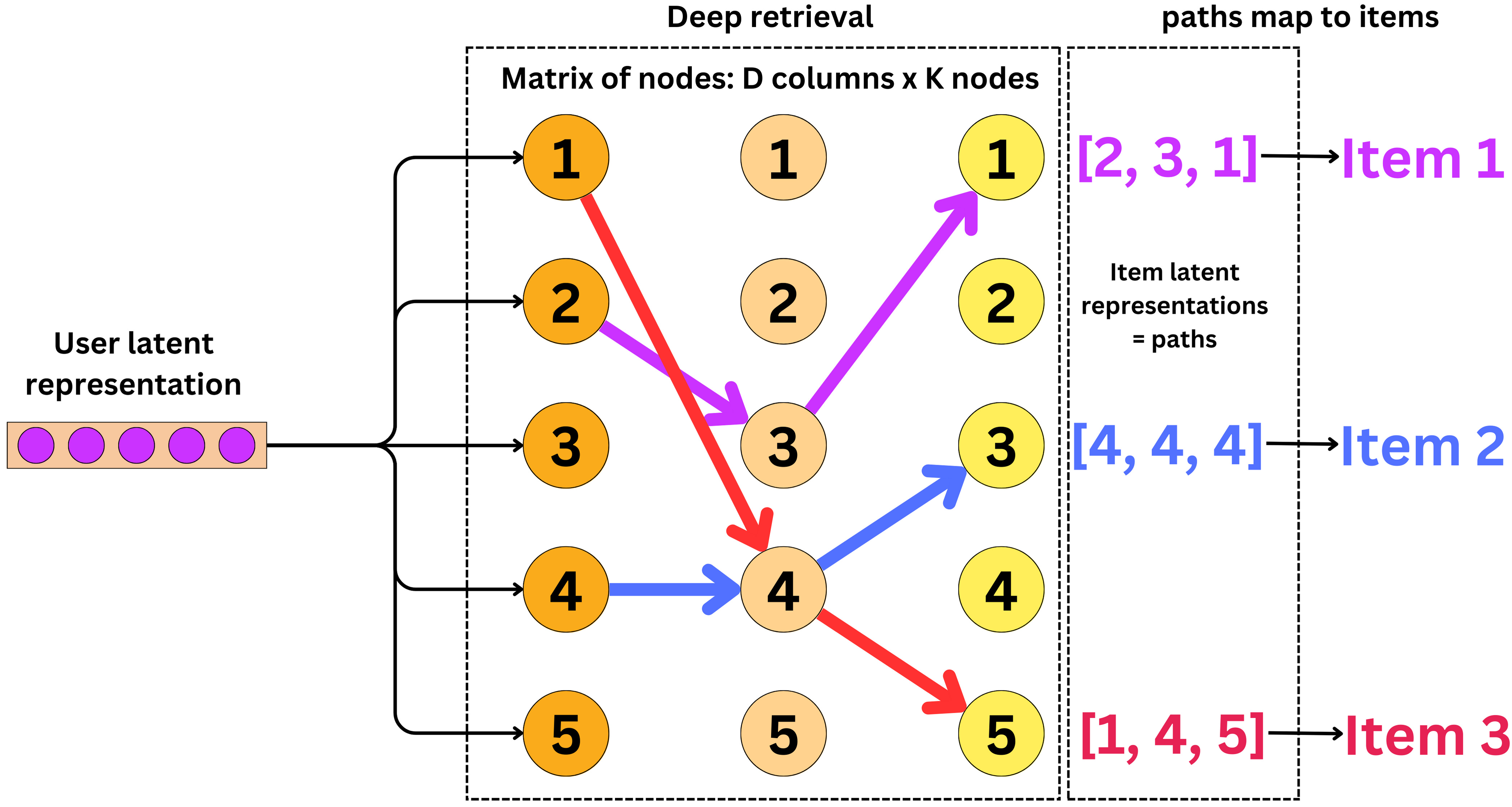
The idea is that a specific path maps to an unique item and can be used as a vector representation of an item. With K rows and D columns, we have KD possible paths, so we just need to make sure that K and D are large enough to encode all the videos available.
From a matrix abstraction to a neural network model
The underlying machine learning model is actually a neural network and that matrix is an abstraction built on top of it. In reality, each column of that matrix is represented by a multi-layer perceptron followed by K softmax functions representing K nodes. The input to each layer is the output of the previous layer concatenated with all the predecessor outputs. Each layer outputs K values so the input to the last layer contains K x D values.

At the first layer, the softmax functions estimate the probability
Then at the second layer, the softmax functions estimate the probability
At the last layer, the softmax functions estimate the probability
At each layer, if you followed the path of maximum probability as follows
then each user would correspond to one path which in turn would lead to only one recommendation, which is a limited option!
Beam search for inference
What we want is to input one user and get ~100K video candidates as a result. The strategy adopted is to use Beam search. At each layer, we follow the top B paths that maximize the probability where B is a hyperparameter. We just need to choose B ~ 100K.
Inputs: user x, beam size B
for column i in all D columns:
C = the top B paths with highest p(c[i]|x, c[1], ..., c[i-1])
return C
How to rank
We can compute the probability of a path {c1, c2, …, cD} using the chain rule formula
The model weights are learned by maximizing the log-likelihood of the problem
In practice, it is possible that the learning paradigm associates multiple items to the same paths. To limit that, they add a factor to penalize those paths with multiple items. We call |c|, the number of items for a path c
Multiple items can still be associated with the same path, so we need a way to distinguish them if we need to subset the items further. To achieve that they jointly train a simple model with a softmax output function to learn to predict which item the user will watch. This model is trained as a classifier. In practice, the model can be a logistic regression for low latency inference. The output of that model will be a probability that can be used to rank the items coming out of the beam search


Training the model
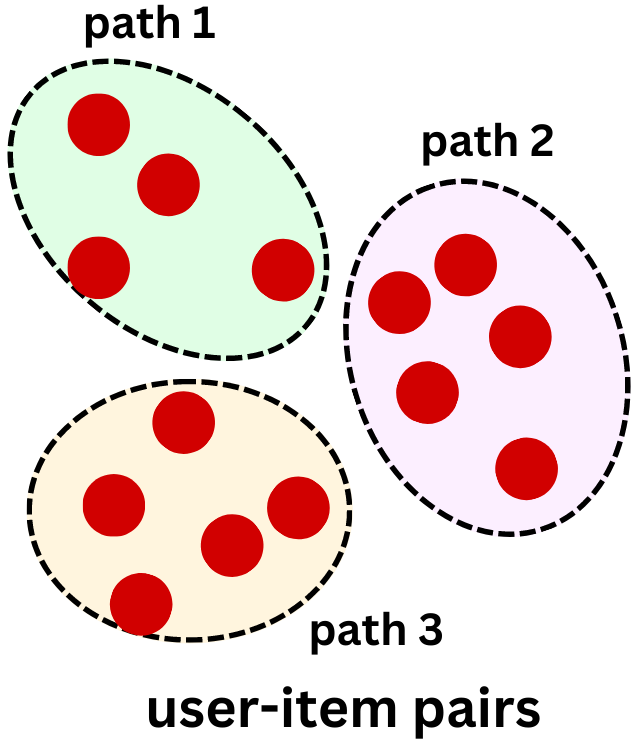
The Deep Retrieval model cannot be trained with gradient descent because mapping an item to a path is a discrete process. The problem is not established as a supervised learning problem because the loss function does not explicitly account for a ground truth target. We use the likelihood maximization principle to find paths that are likely to relate to a user, with those paths mapping to items. We try to learn parameters that make the model likely to represent the user-item pairs in the data.
This is very similar to the way we approach clustering problems. Here, we try to learn paths that represent user-item pairs. The paths can be thought as clusters and the problem is solved using the Expectation-Maximization algorithm:
Expectation: backpropagate the loss function.
Maximization: find path mapping using only the highest probability paths in a beam search manner.
Fine ranking stage
The candidate selection component must be optimized for latency and recall. We need to make sure all relevant videos are part of the candidate pool even if that means including irrelevant videos. Moreover, in most near real-time recommender systems, candidates are ranked by linear or low capacity models.
On the other hand, we need to optimize the fine re-ranking component for precision to ensure all videos are relevant. Latency is less of a problem as we only have to rank ~100 videos. For that component, models are typically larger with higher predictive performance.
