

Deep Dive: How to Build the Twitter Feed Ranking Recommender System
Machine Learning System Design

Twitter needs to build daily tweet feeds for 450M monthly active users out of 500M tweets. How do we generate those feeds with low latency such that users keep engaging with the content? Twitter recently opened source its recommender system and we dig into the details of each algorithm. We cover:
The overall architecture
Candidate generation stage
Recommend Tweets within your network: RealGraph
Recommendation on real-time users-Tweets interaction graph: GraphJet
Learn users’ communities: SimClusters
Learn embedding representation of graph attributes using self-supervised learning: TwHIN
Fine ranking stage
The MaskNet model
The ranking objective

The overall architecture
The goal of the recommender system is to select the top 1500 most relevant Tweets for each user out of the ~500M daily Tweets generated on the platform. The top Tweets are then finely ranked such that the most engaging ones are at the top. The pipeline is as follows:
A user requests his feed on the application.
The request is dispatched to the candidate generation stage where the top 1500 most relevant Tweets are selected out of 500M available Tweets.
The top Tweets are then ranked by the heavy ranker in the fine re-ranking stage.
The Tweet list is augmented with Ads and suggested users to follow in the Mixing stage.
The feed is then available to be presented to the user.
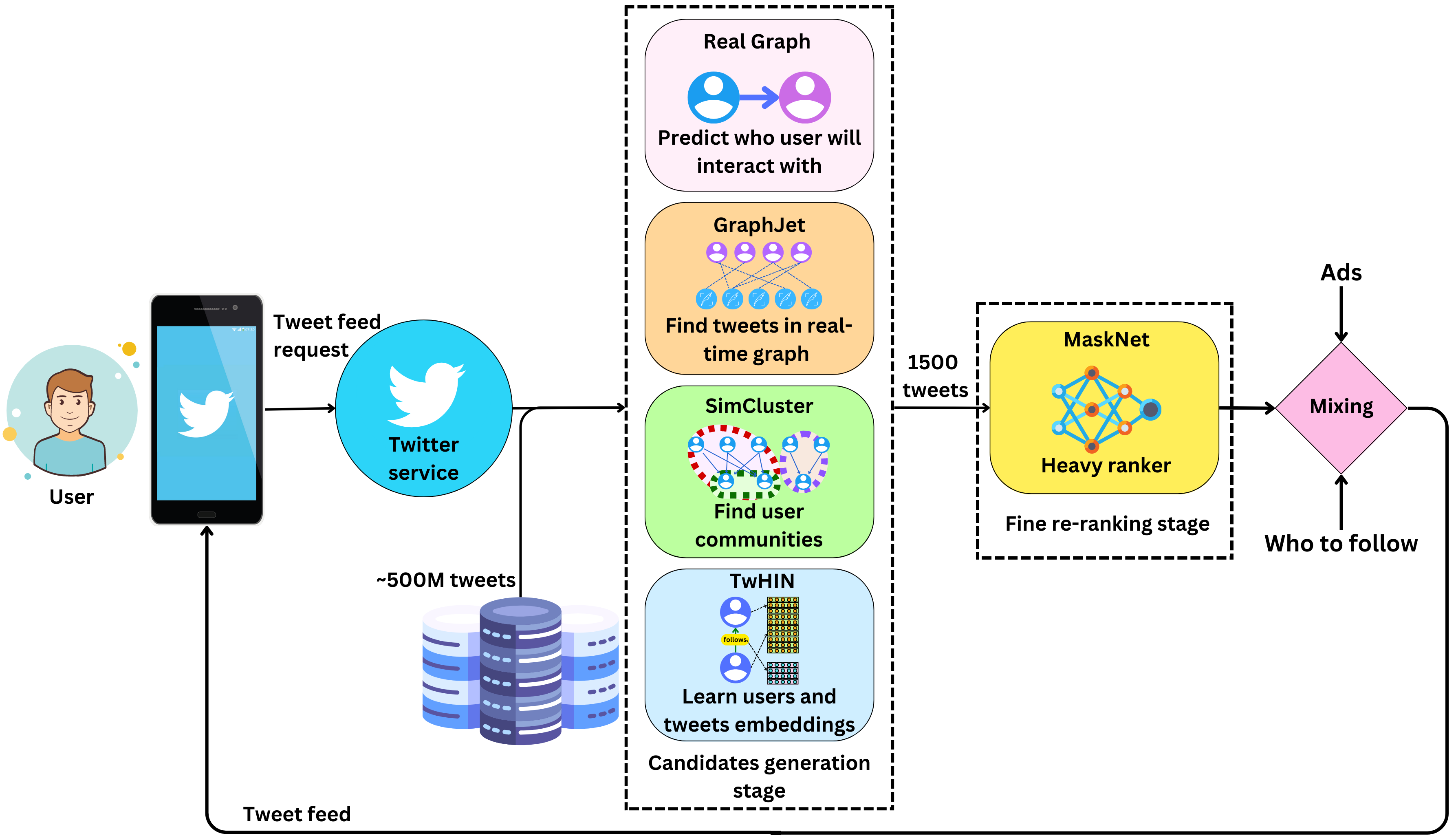
The recommender system follows a typical two-stage approach but differentiates itself by the diversity of the different components of the candidate generation stage. This provides the fine ranking stage with a heterogeneous set of Tweets that improve the user experience with more diverse and engaging recommended Tweets. Those four main components each generate a set of candidates:
Real graph: it recommends content within your direct network. Based on previous interactions with users within your network, it predicts the likelihood of future interactions.
GraphJet: it is a in-memory graph system that captures the real-time users-Tweets interactions. Tweet selection is done using a similar algorithm to PageRank.
SimCluster: it is a community discovery algorithm based on the most followed users on the platform. Twitter users can be recommended Tweets based on their communities.
TwHIM: it is a graph algorithm to learn vector representations of all Twitter entities (users, Tweets, ads, …). The vector representation can be used to recommend Tweets based on the similarity metric computed in that vector space.
Candidate generation stage
Recommend Tweets within your network: RealGraph
Real Graph is arguably the simplest of the candidate generation algorithms. The idea is to predict which users you may interact with in the future based on your past interactions. There are three options for an edge from user A to user B to exist:
If A follows B
If B is in A’s phone or email address book
If A interacted with B
The model is a simple logistic regression. The model is run daily in batch on Hadoop.
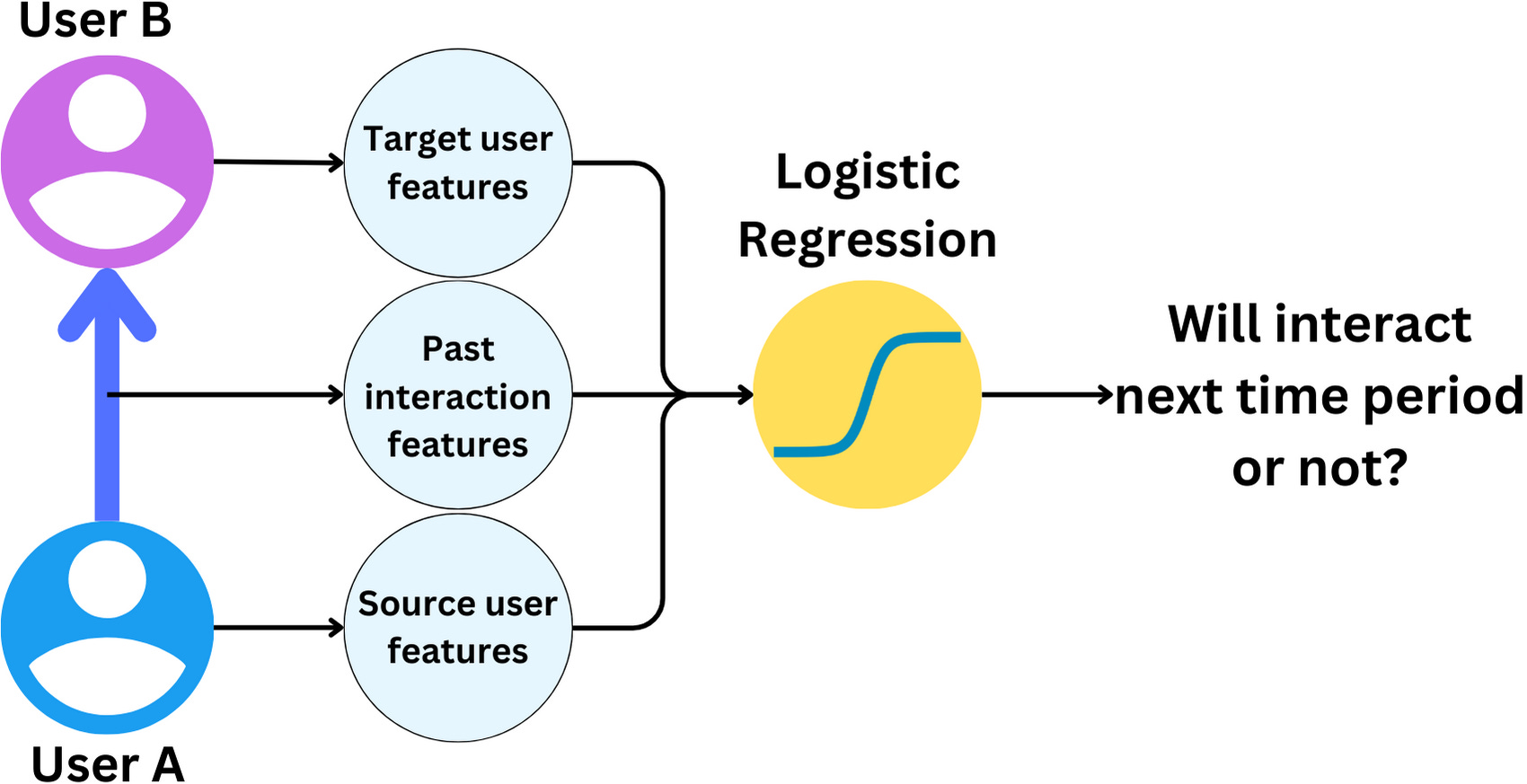
The data used within the model is:
The binary target: did any interaction (messages, likes, retweets, …) occur in the given time period?
Edge features:
The number of days since a specific interaction
Mean and variance of interaction counts
A daily exponentially decayed interaction count
Number of days since the last interaction happened
Number of days since the first interaction happened
User features:
Aggregated edge feature values for ingoing and outgoing edges
Number of tweets in the last week
Language
Country
Number of followers
Number of people they follow
PageRank on the follow-graph
Using the model's scores, we can rank users according to their probability of future interaction. We can now select Tweets from the top users. It is important to add diversity to the selected Tweets so that there are not too many Tweets from the same user.
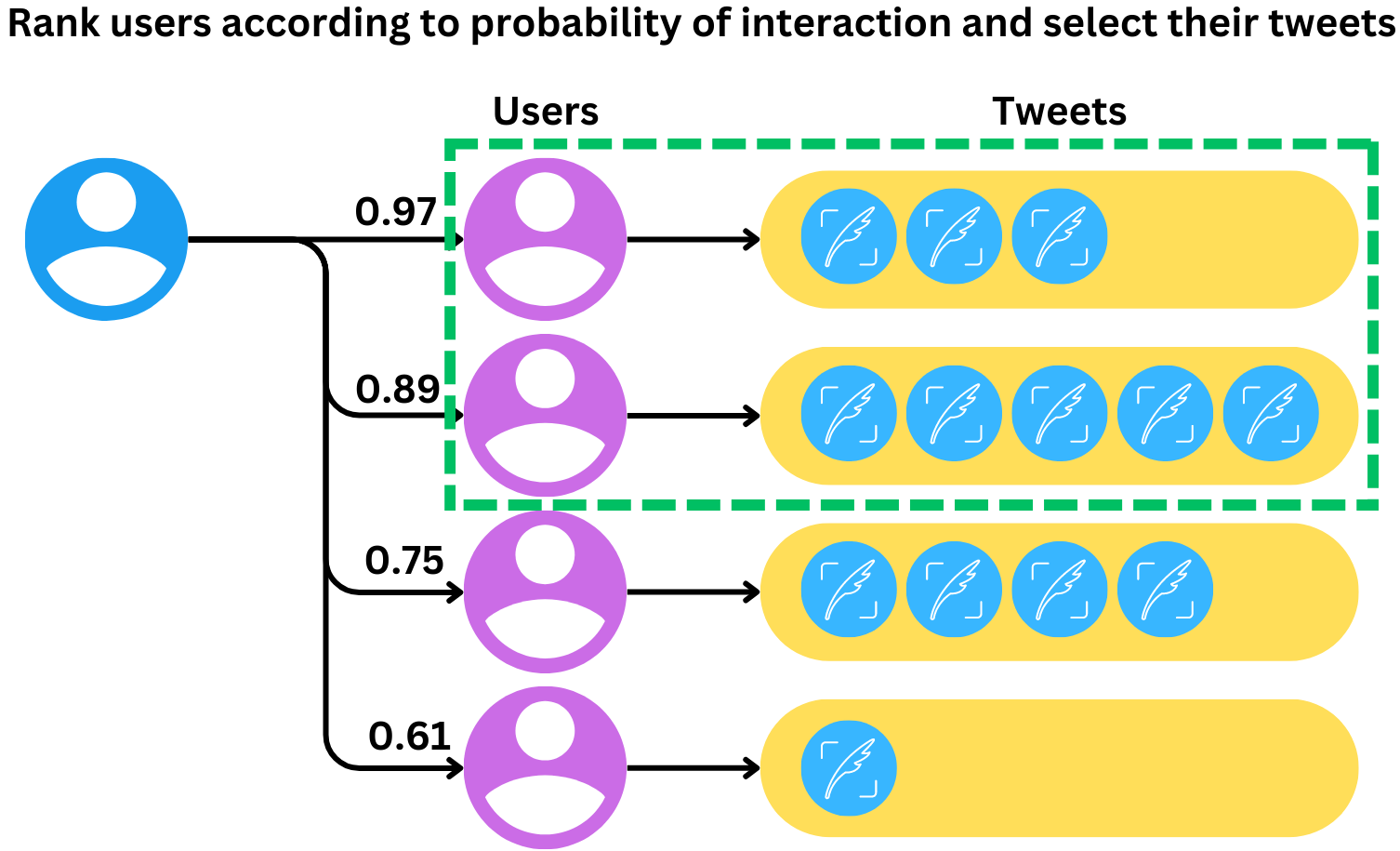
RealGraph is an old system at Twitter and is likely to be soon deprecated and replaced by newer systems.
Recommendation on real-time users-Tweets interaction graph: GraphJet
In-memory real-time graph system
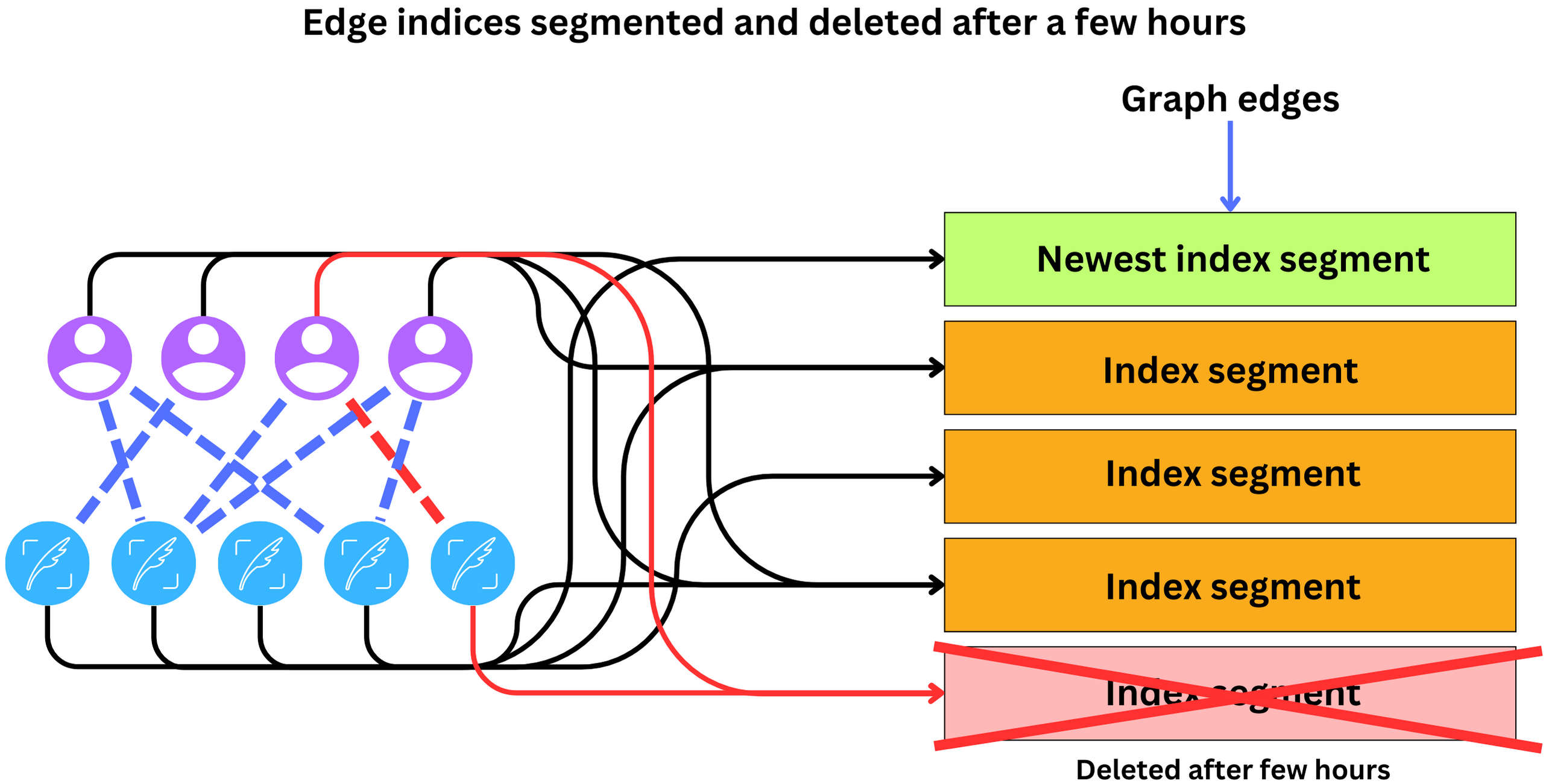
GraphJet is used to find Tweets for a user that similar users engaged with or to find similar users or similar Tweets. It captures a bipartite graph with on the left side the users and on the right side the Tweets. The edges between the left and right sides represent interactions between users and Tweets. It is time-dependent, so only interactions that are a few hours old are captured.

Because it is time dependent, the graph cannot grow unbounded. Because of it they can store the whole graph in memory on one machine for fast retrieval and computation. Considering Twitter's typical scales, to achieve such a feat, as little information as possible must be retained. The edges IDs are created monotonically such that it is easier to segment them by time of insertion. Segments are just buckets of IDs and the next segment is created once the previous one is full. The segments are then deleted after a few hours to enable GraphJet’s real-time behavior.
The SALSA algorithm for Tweets recommendation
The Tweets recommendation is based on a similar algorithm as personalized PageRank: the Stochastic Approach for Link-Structure Analysis (SALSA) algorithm. The idea is to perform a random walk from the user to compute a distribution of the number of times some Tweets get encountered in that walk. The process can be outlined as follows:
We start with the user we want to build a recommendation for.
We select randomly an edge toward the right side of the graph. We reach a Tweet and count the number of times we meet that Tweet.
From that Tweet, we select at random an edge to the left side and we jump to that user.
We iterate that process an odd number of times and track the counts for each Tweet we encounter.
We reset the random walk if it wanders too far away from the user.
In the case a user did not have a connection to the right side of the graph, we start with the users within that user’s network instead.
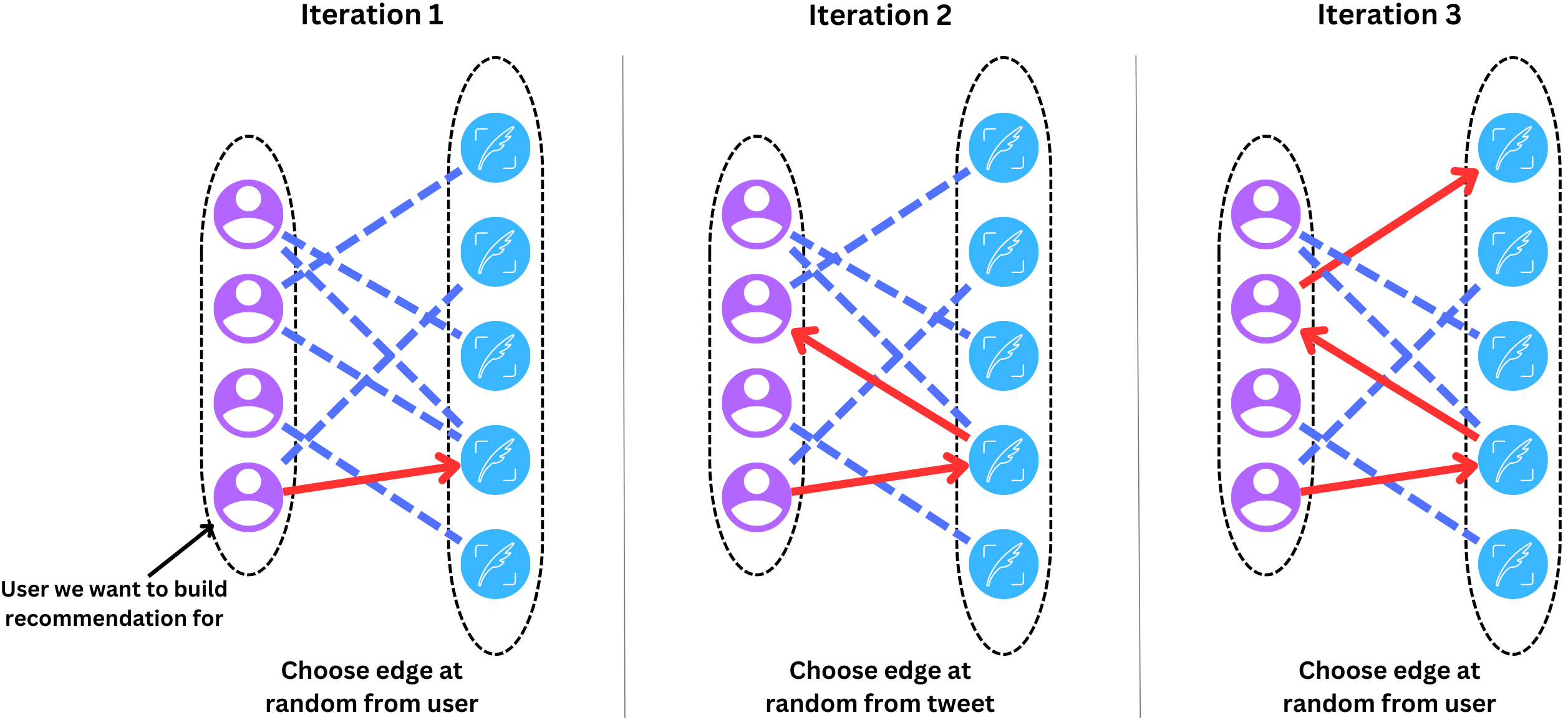
The logic is that Tweets that are met many times by the random walk are Tweets that users similar to the source user tend to engage with. After a few iterations, we can construct a distribution of the number of times the random walk met a specific Tweet. We can now rank Tweets according to their values in that distribution, with the ones with the highest counts being at the top.

GraphJet to measure similarities
GraphJet can also compute similarities among users or Tweets. The idea is that two Tweets are likely similar if they were engaged by many of the same people. We can construct a vector representation of each Tweet by looking at the users that interacted with them. As an example, we can build the following similarity metric:

