

Deep Dive: How to use the OpenAI DALL-E 2 API
Building Machine Learning Solutions

It is strange how outdated DALL-E 2 feels today where it felt like a revolution about a year ago. However, after testing the StableDiffusion API, and tools like Midjourney, I still believe it is the best and cheapest tool around to build software applications utilizing image generation. This is until the people at Midjourney wake up and provide a public API. Today we dive into the DALL-E 2 API to generate and modify images. We cover:
What is DALL-E 2?
Diffusion models
How DALL-E 2 uses the diffusion process
Using the API to generate images
Generating images
Downloading the generated images
Modifying images
Latent representation from CLIP
Latent representations from Denoising Diffusion Implicit Models (DDIM)
Interpolating the latent representations
Editing images using the API
Producing non-square images
References
What is DALL-E 2?
DALL-E 2 is starting to lag when it comes to the quality of the images it generates. You would get more satisfactory results using Midjourney or Leonardo.ai. But when it comes to building apps, it is still one of the easiest and cheapest tools around. Let’s hope it changes soon and we get an update with better tools!
Diffusion models
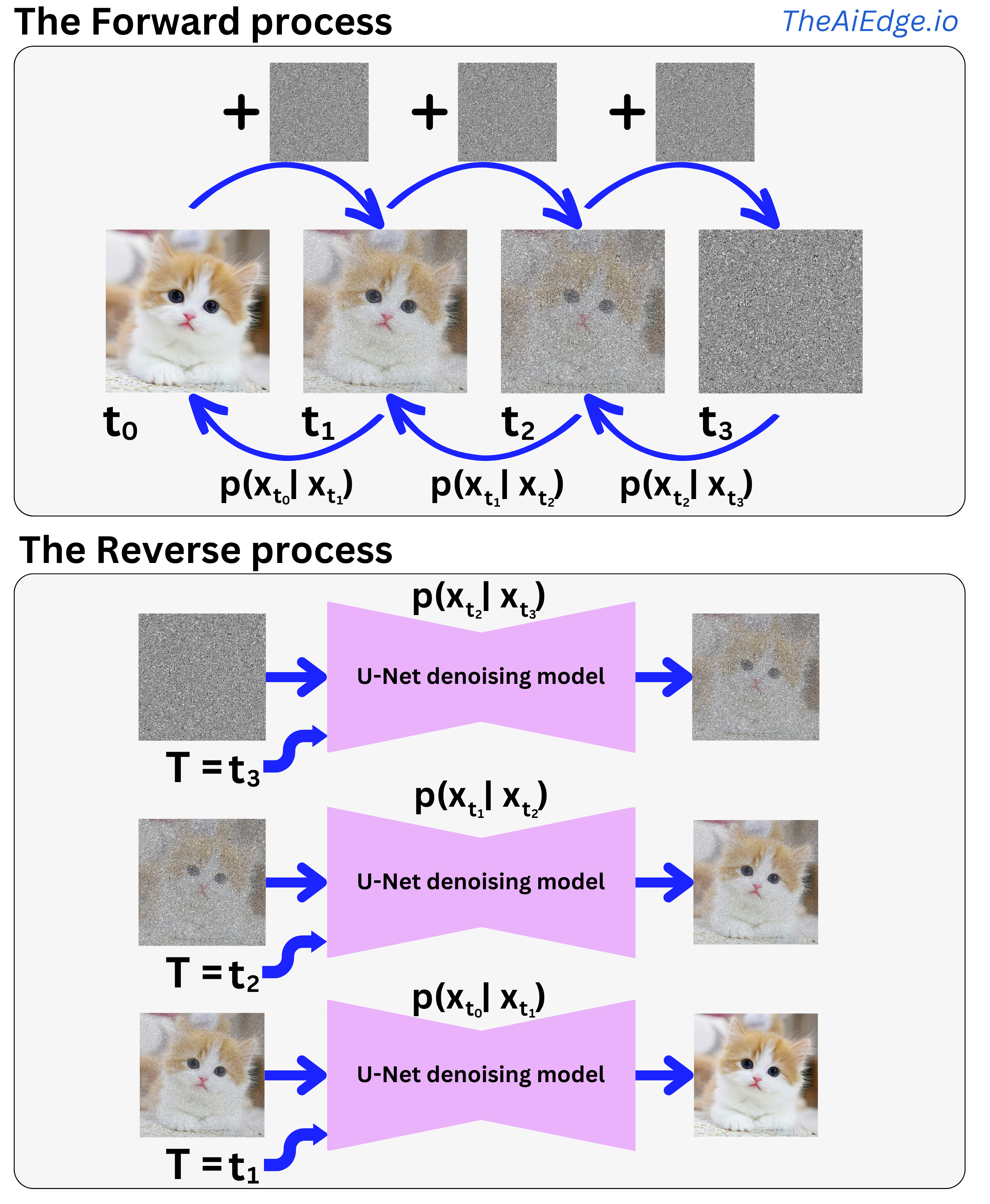
What is a diffusion model in Machine Learning? Conceptually, it is very simple! You add some noise to an image, and you learn to remove it. Train a machine learning model that takes as input a noisy image and as output a denoised image and you have a denoising model.
The typical way to do it is to assume a normal distribution of the noise and parametrize the distribution mean and standard deviation matrix. Effectively, we can simplify the problem to just learning the mean matrix. The process can be divided into the forward process, where white noise (Gaussian distributed) is progressively added to a clean image, and the reverse process, where a learner progressively learns to denoise the noisy image until it is back to being clean.
Why is that called a diffusion model? What does that have to do with the diffusive process of particles in a fluid with a concentration gradient (see Wikipedia)? This is due to the way mathematicians have abused the jargon of the physical process to formalize a mathematical concept. It happens that physical phenomena like Fick diffusion, heat diffusion and Brownian motion are all well described by the diffusion equation:
first time derivative of a state function is equal to the second space derivative of that state function. That diffusion equation has an equivalent stochastic formulation known as the Langevin equation:
At the core of the Langevin equation is a mathematical object called the Wiener process W. Interestingly enough, this process is also called Brownian motion (not to be confused with the physical process). It can be thought of as a random walk with infinitely small steps. The key feature of the Wiener process is that a time increment of that object is Normal distributed. That is why the concept of "diffusion" is intertwined with the white noise generation process and that is why those ML models are called diffusion models!
Those diffusion models are generative models as data is generated using a Gaussian prior, and they are the core of text to image generative models such as Stable Diffusion, DALL-E 2, Imagen and Midjourney.
How DALL-E 2 uses the diffusion process
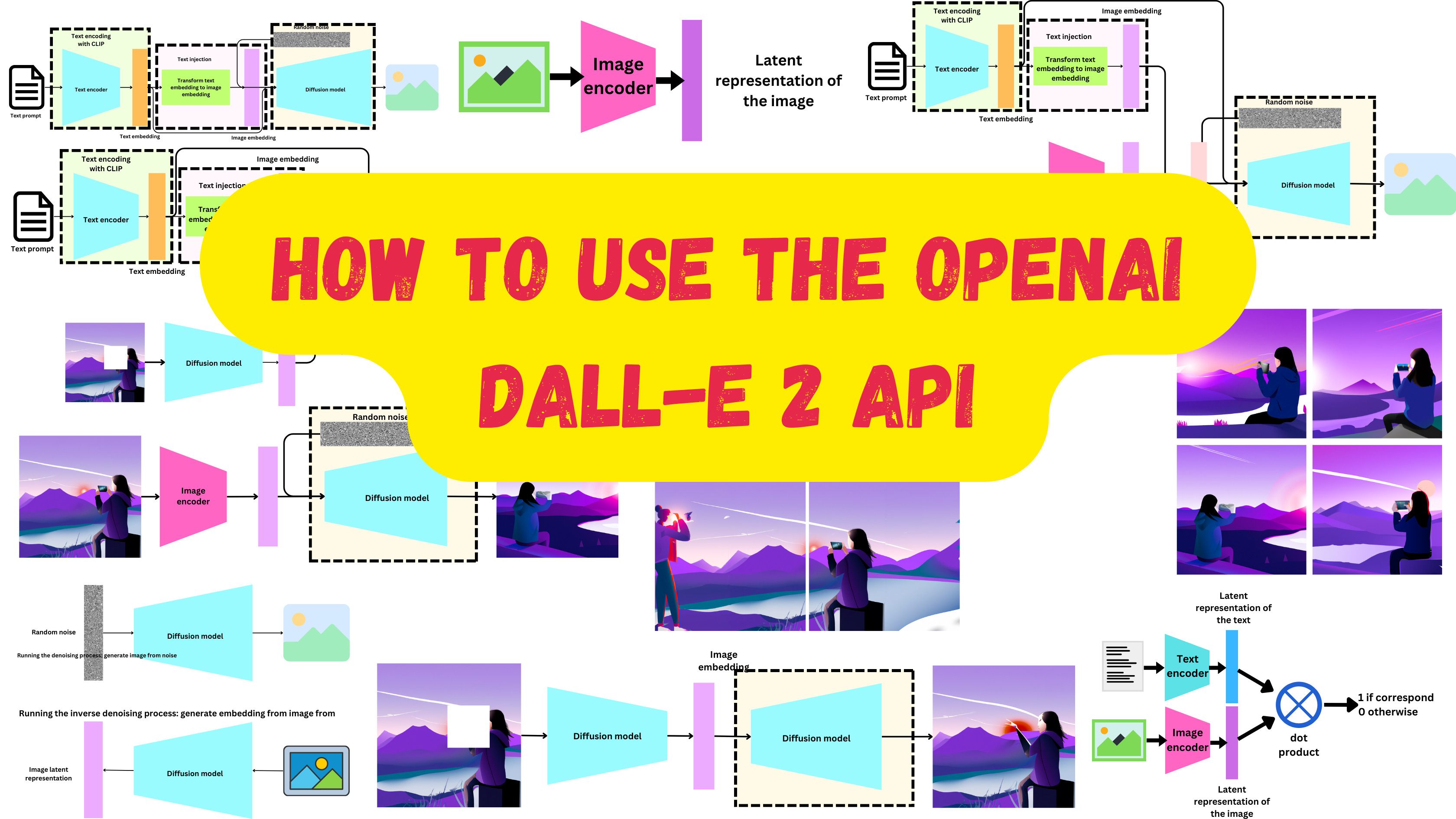
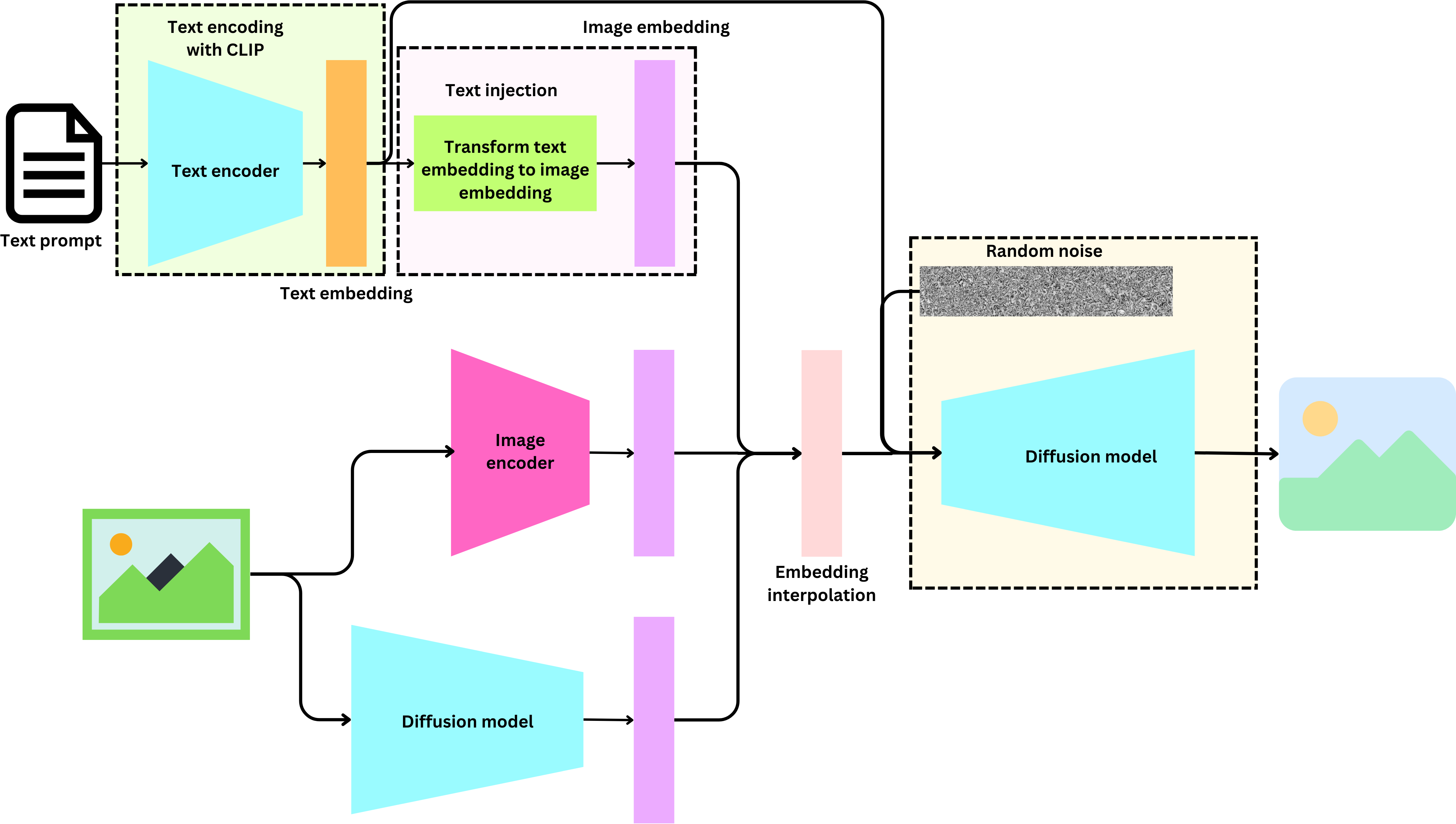
DALL-E 2 generates non-deterministic images from text data. It is basically a combination of a couple of models: a CLIP model that predicts embeddings from text and a diffusion model that non-deterministically predicts images from embeddings. The State of the Art image generation models conditioned on text prompt have 3 things in common: A text encoder, a way to inject text information into an image and a diffusion mechanism.
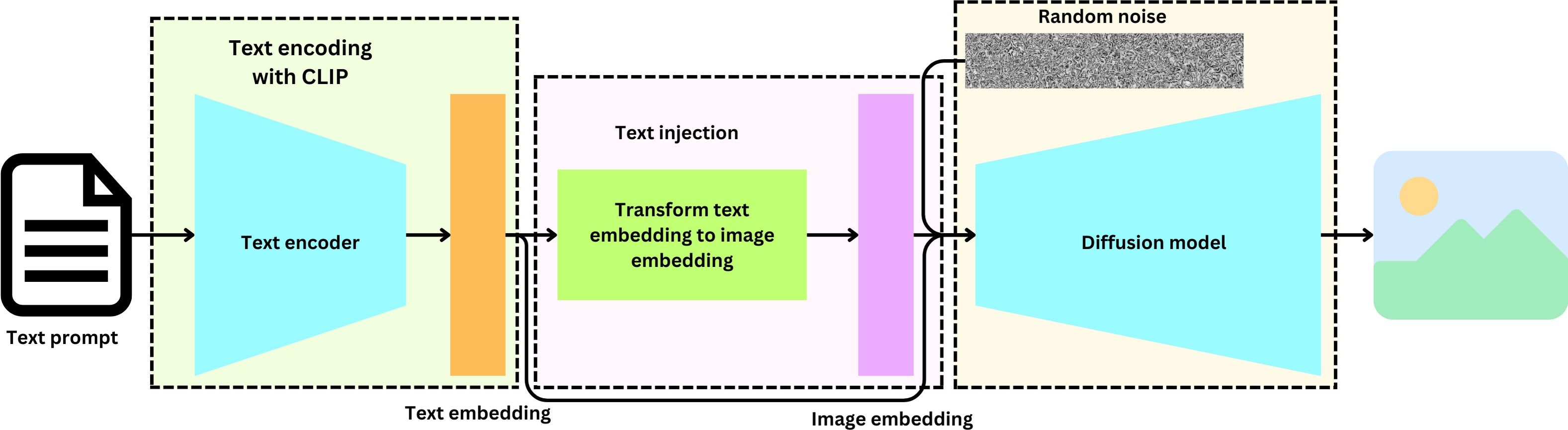
First, they train a Contrastive Language-Image Pre-training model (“CLIP: connecting text and images”) to semantically align the latent text representation and the latent image representation. That CLIP model is used as a text encoder that takes as input a text prompt and returns a text embedding. That text information is processed by a model that learns to predict image embeddings from text embeddings and the text embedding is further processed as input to the diffusion model. The diffusion model injects noise to make the process stochastic. The DALL-E 2's denoising model directly decodes image embedding into images using GLIDE's decoder (“GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models”).
Using the API to generate images
Generating images
Before continuing, make sure to get your OpenAI API key by signing up in the OpenAI platform:

Let’s first install the OpenAI Python package
pip install openaiWe can generate an image by running the following function with the prompt describing the image
import openai
openai.api_key = OPENAI_API_KEY
prompt = """
High-quality digital art of a person taking a photo in nature, surrounded by beautiful scenery,
capturing the present moment and promoting mindfulness.
"""
response = openai.Image.create(
prompt=prompt,
n=4,
size='1024x1024'
)Here I chose the number of resulting images to be n = 4 and the image size to be 1024 x 1024 pixels. With DALL-E 2, you can only use 256x256, 512x512, or 1024x1024 pixels. That is pretty limiting but I will demonstrate further down how to obtain images of any dimension using inpainting.
The images are now available and you can see them by following the URLs provided in the response:
url = response['data'][0]['url']
Downloading the generated images
To download the images it is pretty simple. You just need to run an HTTP get request using the URL
import requests
output_path = 'image_test.png'
img_data = requests.get(url).content
with open(output_path, 'wb') as handler:
handler.write(img_data)If you want to directly manipulate the image object in a Python script without having to download it we can use the Pillow package to do so:
pip install PillowWe can now use the image directly in the code
from PIL import Image
from io import BytesIO
img_data = requests.get(image_url).content
image_buffer = BytesIO(img_data)
image = Image.open(image_buffer).convert('RGBA')Modifying images
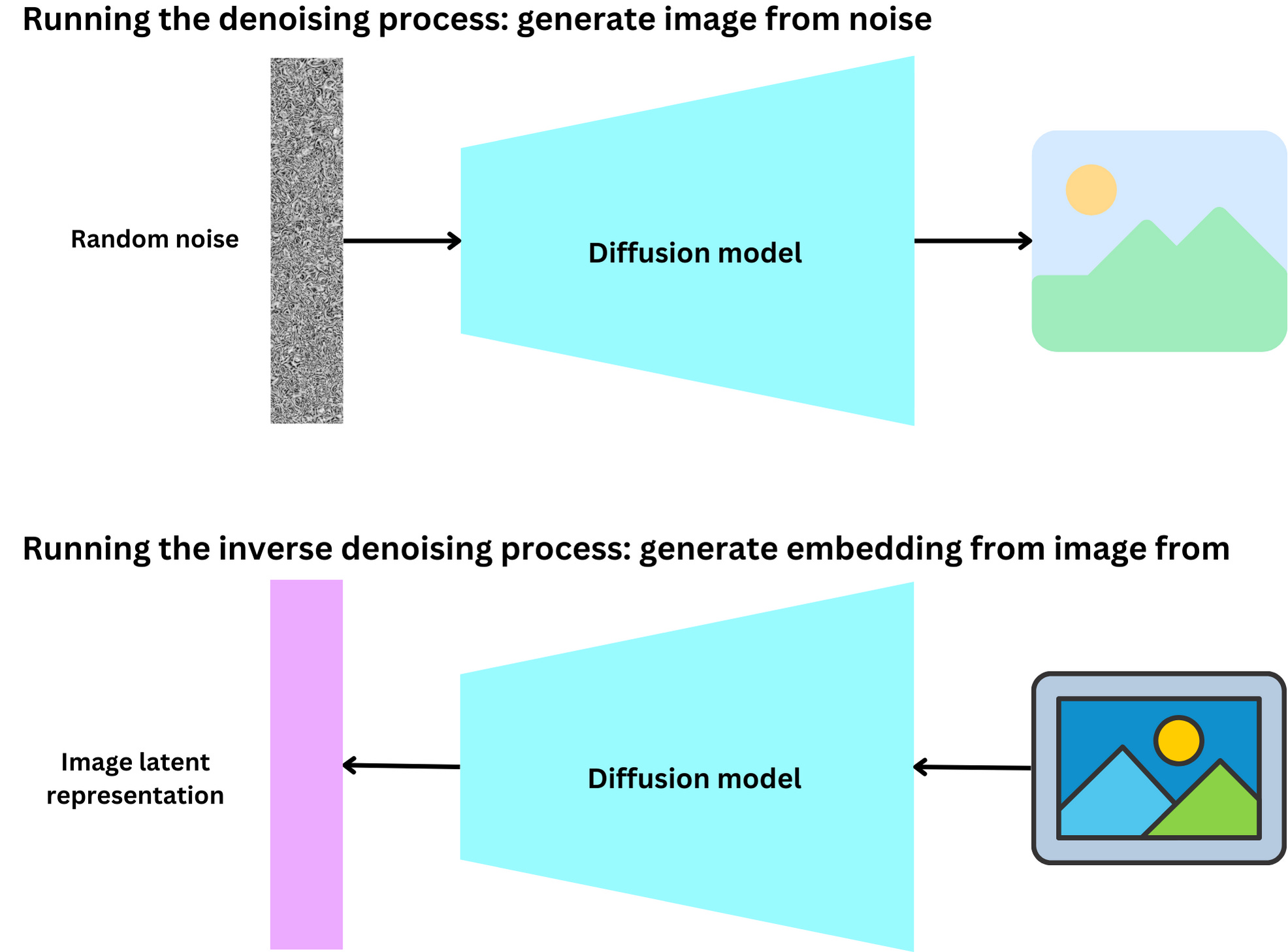
When we think about diffusion models, we tend to think about models that generate images using text prompts as input, but we can actually apply those models to modify images. The idea is to interpolate between latent representations and run the diffusion decoding process. How do we generate latent image representations? There are 3 ways using DALL-E 2.
Latent representation from CLIP
CLIP is a training process meant to learn alignments between the text latent representation and the image latent representation. The text and image are encoded using their respective encoders and the model is trained in a contrastive manner. For example a text encoder could be a simple BERT model and the image encoder could be a Vision Transformer. Contrastive learning means that the pairs of image and the text describing it are given a training label 1 and pairs of unrelated image and text are given a 0

Effectively the text encoder and the image encoder converge to a state where they generate text and image embeddings that are similar when the text describes well the image. In the case there is only a text input to the DALL-E 2 model, only the text encoder is used, but we can also use the image encoder to generate meaningful image embeddings

Latent representations from Denoising Diffusion Implicit Models (DDIM)
The diffusion model learns to denoise a noise input in an iterative manner as described above. Given a fixed input noise, the process is deterministic thus giving rise to an implicit latent space. We can run the process in reverse to get the latent representation that produces a given real image.
Interpolating the latent representations
Now that we have multiple image representations, we can interpolate between them. In the case of linear interpolation and 3 embeddings A, B, C, you can generate interpolations between the 3 embeddings using the following formula
Where u, v ∈ [0, 1] and u + v ≤ 1. Let’s imagine A represents the image embedding obtained from the text prompt, B is the image embedding coming from the CLIP encoder and C is the image embedding coming from the reverse denoising process. If u = v = 0, then if we don’t add any noise, the original image should be recreated. If v = 1, a different image with similar elements should be generated after the denoising process. We can modify the original image using a text prompt. If we use u = 0.5 and v = 0 for example, then the model will use the original image to modify it according to the prompt.
Editing images using the API
Let’s create a couple of functions to simplify the process. First, let's write a function that creates images from a prompt
def create_image(prompt):
response = openai.Image.create(
prompt=prompt,
n=1,
size='1024x1024'
)
image_url = response['data'][0]['url']
img_data = requests.get(image_url).content
image_buffer = BytesIO(img_data)
image = Image.open(image_buffer).convert('RGBA')
return imageLet’s now write a function that dumps the image object into a ByteIO object
def get_img_bytes(img):
bfr = BytesIO()
img.save(bfr, 'png')
return bfr.getvalue()And we create a function that allows us to inpaint images using the OpenAI create_edit method
def create_edit(prompt, image):
response = openai.Image.create_edit(
image= get_img_bytes(image),
prompt=prompt,
n=1,
size='1024x1024'
)
image_url = response['data'][0]['url']
img_data = requests.get(image_url).content
image_buffer = BytesIO(img_data)
image = Image.open(image_buffer).convert('RGBA')
return imageLet’s create an image
prompt = """
High-quality digital art of a person taking a photo in nature, surrounded by beautiful scenery,
capturing the present moment and promoting mindfulness.
"""
image = create_image(prompt)
image
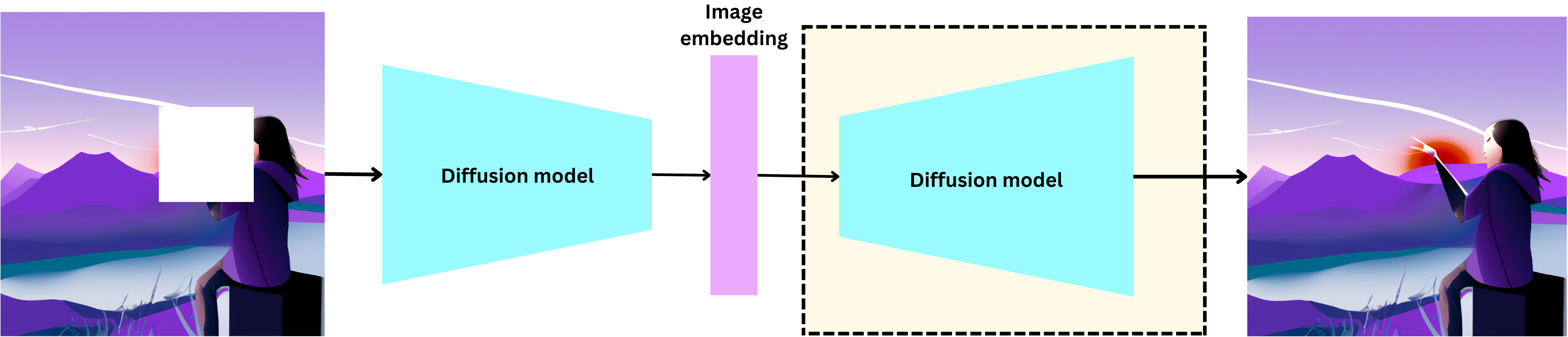
We can erase part of the image by setting a subset to 0
import numpy as np
img = np.array(image)
img[300:600, 500: 800] = 0
image_with_mask = Image.fromarray(img)
image_with_mask
We can now ask DALL-E 2 to reconstruct the image from the image with mask. The DALL-E 2 API does not allow empty prompts so I provide it with a meaningless one
create_edit('none', image_with_mask)
In the interpolation equation above, this is equivalent to setting u = v = 0. The model generates a latent representation of the image and when trying to recreate it, it fills in the blank to obtain a visually meaningful image
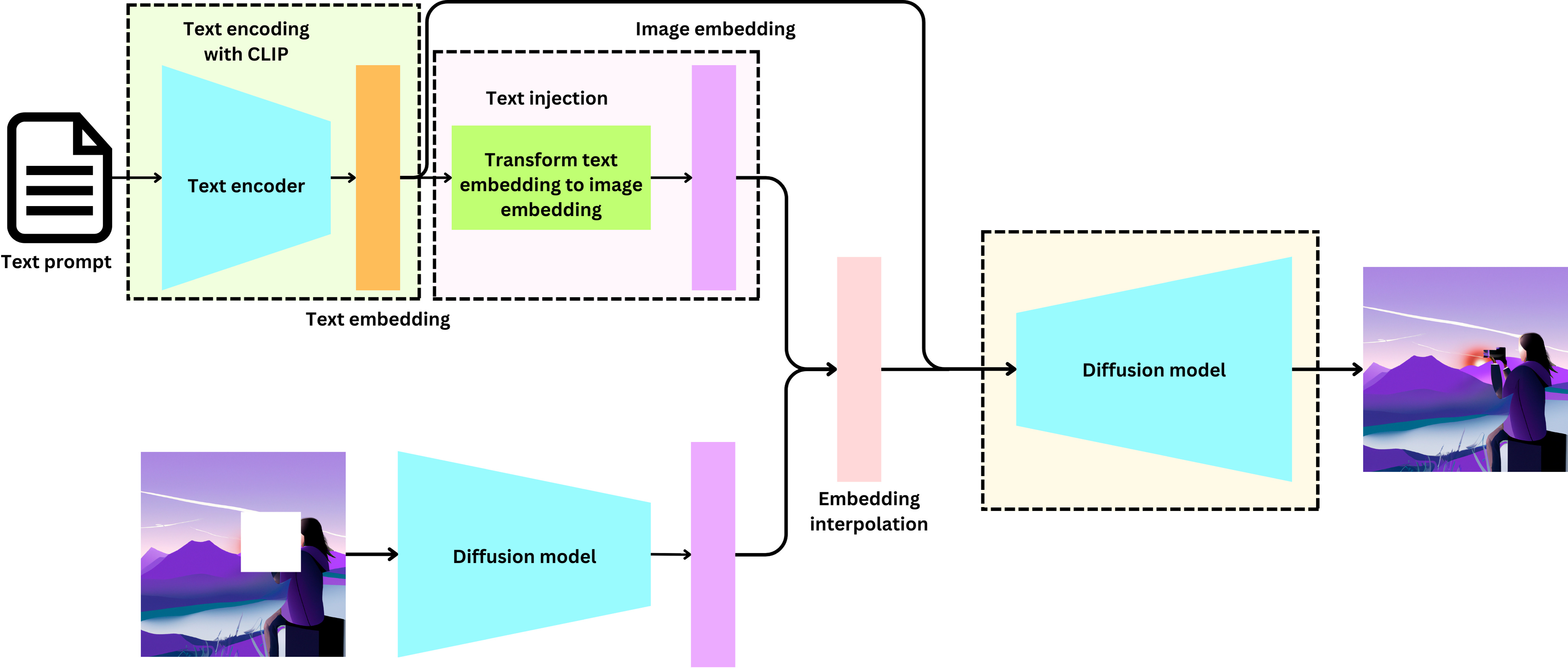
We can provide a more meaningful prompt to guide better the model. I am using the same prompt as before but I added the “camera constraint”
prompt = """
High-quality digital art of a person taking a photo with a camera in nature, surrounded by beautiful scenery,
capturing the present moment and promoting mindfulness.
"""
create_edit(prompt, image_with_mask)
The phone has been replaced by a camera. This time we interpolated between the text prompt and the original image with v = 0
OpenAI provides another function create_variation. Let’s run it and see the results
def create_variation(image):
response = openai.Image.create_variation(
image= get_img_bytes(image),
n=1,
size='1024x1024'
)
image_url = response['data'][0]['url']
img_data = requests.get(image_url).content
image_buffer = BytesIO(img_data)
image = Image.open(image_buffer).convert('RGBA')
return image
create_variation(image)
I ran the function multiple times. We can see that similar elements appear in the resulting images but they are quite different from the original. The images are semantically similar but the pixel similarities are low. In that situation, we are closer to the case where u = 1, v = 0

Producing non-square images
It is quite a pity that DALL-E 2 does not provide the option to generate images of any dimension. However, using the model's outpainting capabilities we can solve that. The idea is to cut the image in half and pad left and right to create 2 “masked” images. We just need to ask DALL-E 2 to fill in the blank using the original prompt:
We first convert the original image and split it in half:
img = np.array(image)
hh, ww, f = img.shape
start_idx = hh // 2
first_half_image = img[:, :start_idx]
second_half_image = img[:, start_idx:] We then create arrays of zeros of the same size as the half images:
right_zeros = np.zeros_like(first_half_image)
left_zeros = np.zeros_like(second_half_image)And concatenate the different arrays:
left_img = np.concatenate([left_zeros, first_half_image], 1)
right_img = np.concatenate([second_half_image, right_zeros], 1)
left_image = Image.fromarray(left_img)
right_image = Image.fromarray(right_img)
We now edit those images using the original prompt
prompt = """
High-quality digital art of a person taking a photo in nature, surrounded by beautiful scenery,
capturing the present moment and promoting mindfulness.
"""
left_image = create_edit(prompt, left_image)
right_image = create_edit(prompt, right_image)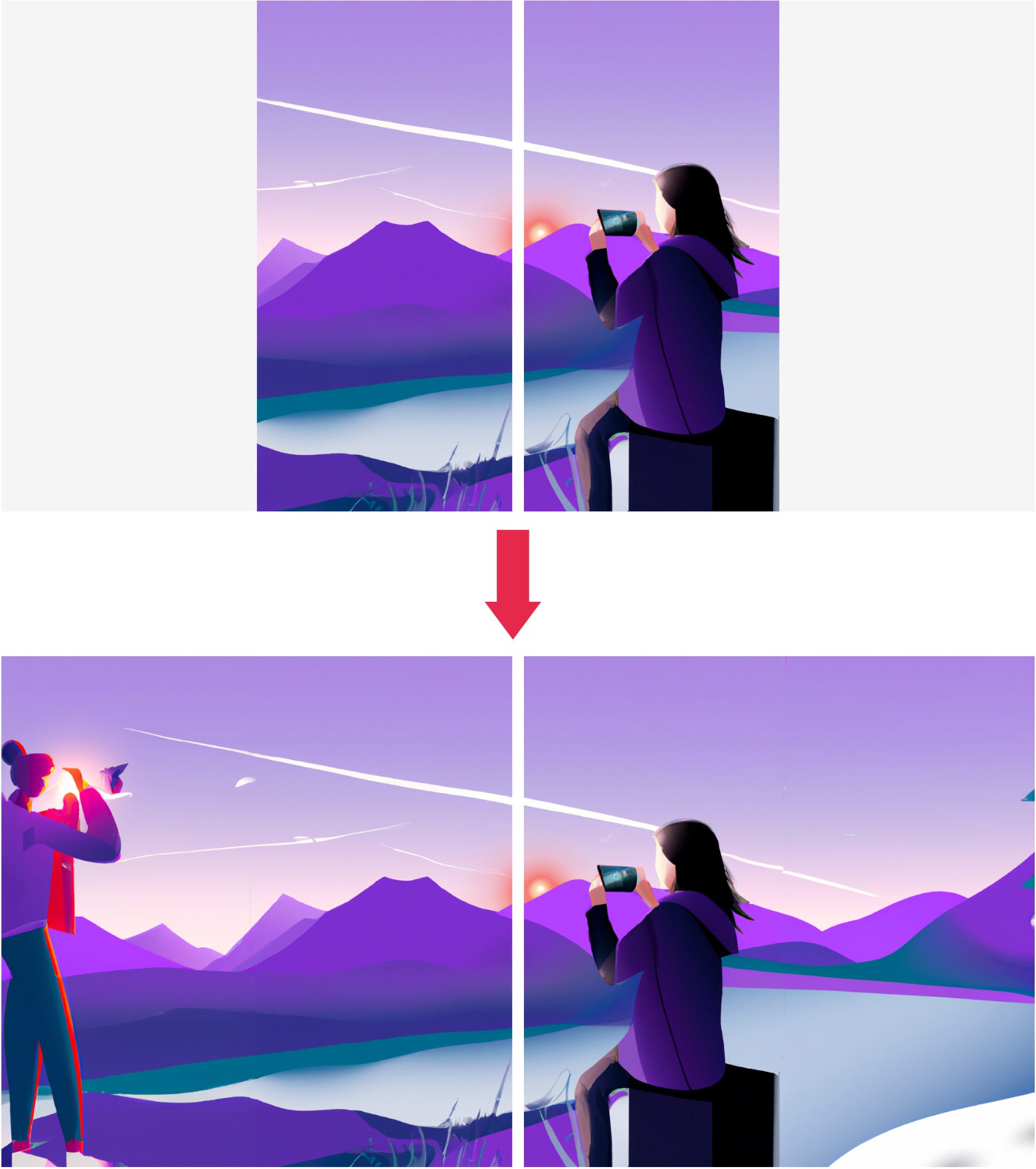
Now we just need to stitch them together
left_img = np.array(left_image)
right_img = np.array(right_image)
long_image = np.concatenate([left_img, right_img], 1)
Image.fromarray(long_image)
That works but it is too much effort to my taste for such a simple feature available in other image generator competitors. I think OpenAI really needs to up its game if it wants to stay in the competition.
References
Hierarchical Text-Conditional Image Generation with CLIP Latents
Learning Transferable Visual Models From Natural Language Supervision
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
That’s all Folks!
