

Deep Dive: Tracking Machine Learning Experiments and Deploying Models with MLFlow
How to deploy ML

When developing models, it is critical to track experiments, register models and versionize iterations. As any software, we need a production release strategy to test and deploy models. MLflow is a framework to manage the Machine Learning lifecycle. Today we look at how to run experiments, register models and deploy them in a controlled manner. We cover:
What is MLflow?
Tracking experiments
Registering models
Serving models
What is MLflow?
I often see junior data scientists / Machine Learning engineers developing models in their notebooks without proper model governance. It is crucial to develop with production in mind and to couple the development pipeline with the production one.
I find MLflow to be quite an effective tool in an ML engineer's arsenal. It provides best practices for ML pipelines. It is not a full-fledged MLOps tool, but it integrates with multiple cloud services. It can be used locally by a single team member or remotely by a large ML engineering team.

MLflow will help automate the following:
Tracking: one of the most significant aspects of model development is the ability to capture the whole state of an experiment. To know an experiment is successful, we need to be able to capture performance metrics to compare experiments. If the experiment happens to be successful, we need to ensure that we can recover all the parameters that led to that success.
Models: once a model has proven to provide good performance in offline experiments, we need to be able to move it to production without making mistakes. With MLflow, you can containerize models and serve them in the same environment as your development environment.
Model registry: MLfLow allows to save models in a model store with version control where we can recover the whole model development history.
Projects: we can package the code and reuse it with different parameters. That can be very useful if we want to automate some processes like hyperparameter tuning.
Recipes: MLflow provides a high level set of templates to orchestrate multiple pieces related to model development and serving. Recipes make it easy to move from local machine development to orchestrated pipelines deployed on Kubernetes for example.
Tracking experiments
Let’s train a simple model to see how tracking helps us develop models. Here is a simple feed forward neural network developed in TensorFlow:
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
def get_model(max_words, num_classes):
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
return model
model = get_model(max_words, num_classes)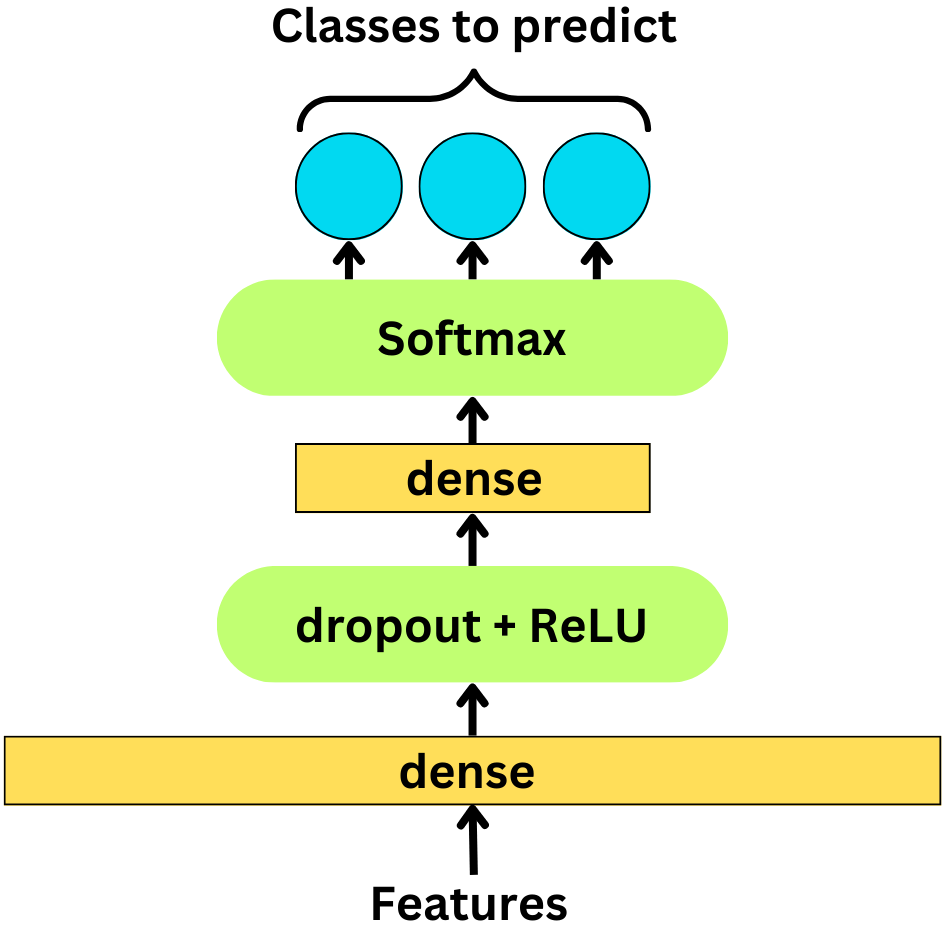
Let’s train that model on cross-entropy with the Adam optimizer and capture the accuracy metric as well:
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
) Let’s get some data to train on. I won't go into the data generation code details
import numpy as np
from keras.datasets import reuters
from keras.preprocessing.text import Tokenizer
def get_data(max_words):
(x_train, y_train), (x_test, y_test) = reuters.load_data(
num_words=max_words,
test_split=0.2
)
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(
x_train,
mode='binary'
)
x_test = tokenizer.sequences_to_matrix(
x_test,
mode='binary'
)
num_classes = np.max(y_train) + 1
y_train = keras.utils.to_categorical(
y_train,
num_classes
)
y_test = keras.utils.to_categorical(
y_test,
num_classes
)
return x_train, y_train, x_test, y_test
max_words = 1000
x_train, y_train, x_test, y_test = get_data(max_words)
num_classes = y_train.shape[1]To track training runs with MLflow, we simply use the autolog function. It only works for some model types but there are other methods if we need additional capabilities
import mlflow
# we only need this to track the training
mlflow.tensorflow.autolog()
history = model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=0.1
)Let’s now run the following in the terminal
mlflow uiand open a browser tab with the following URL http://localhost:5000/. Here is the UI to track the different experiments

If you click on one of the runs you, you can see the different parameters captured:

We may want to add additional parameters. Here for example, I am adding the dropout value as part of the logged parameters
dropout = 0.5
with mlflow.start_run():
...
model.add(Dropout(dropout))
mlflow.log_param('dropout', dropout)
...
mlflow.tensorflow.autolog()As an example, I am training the model with 3 different values of the dropout probability (0.5, 0.2, 0.8) in 3 different experiments. I can now switch to the chart view and compare model performance for the different values of the hyperparameter


It seems that dropout = 0.2 provides the higher performance.
Registering models
Now that we have decided that a specific model is worth pushing to production, we can register it to make it publicly available. By clicking on the run you selected, you will be given the opportunity to register the model
