

Everything you need to know about Stable Diffusion
Well at least for this week!

This week we dig into Stable Diffusion:
What is Stable Diffusion?
But how do you generate those cool animations?
How do you measure similarity between text data and image data?
Let’s generate music with text prompts and Stable Diffusion

What is Stable Diffusion?
It is similar to DALL-E 2 as it is a diffusion model that can be used to generate images from text prompts. As opposed to DALL-E 2 though, it is open source with a PyTorch implementation [1] and a pre-trained version on HuggingFace [2]. It is trained using the LAION-5B dataset [3]. Stable diffusion in composed of the following sub-models:
We have an autoencoder [4] trained by a combination of a perceptual loss [5] and a patch-based adversarial objective [6]. With it, we can encode an image to a latent representation and decode it from it.
Random noise is progressively applied to the embedding [7]. A latent representation of a text prompt is learned from a CLIP alignment into the image representation [8].
We then use U-Net, a convolutional network with ResNet blocks to learn to denoise the diffused embedding [9]. The textual information is injected through cross-attention layers through the network [10]. The resulting denoised image is then decoded by the autoencoder decoder.
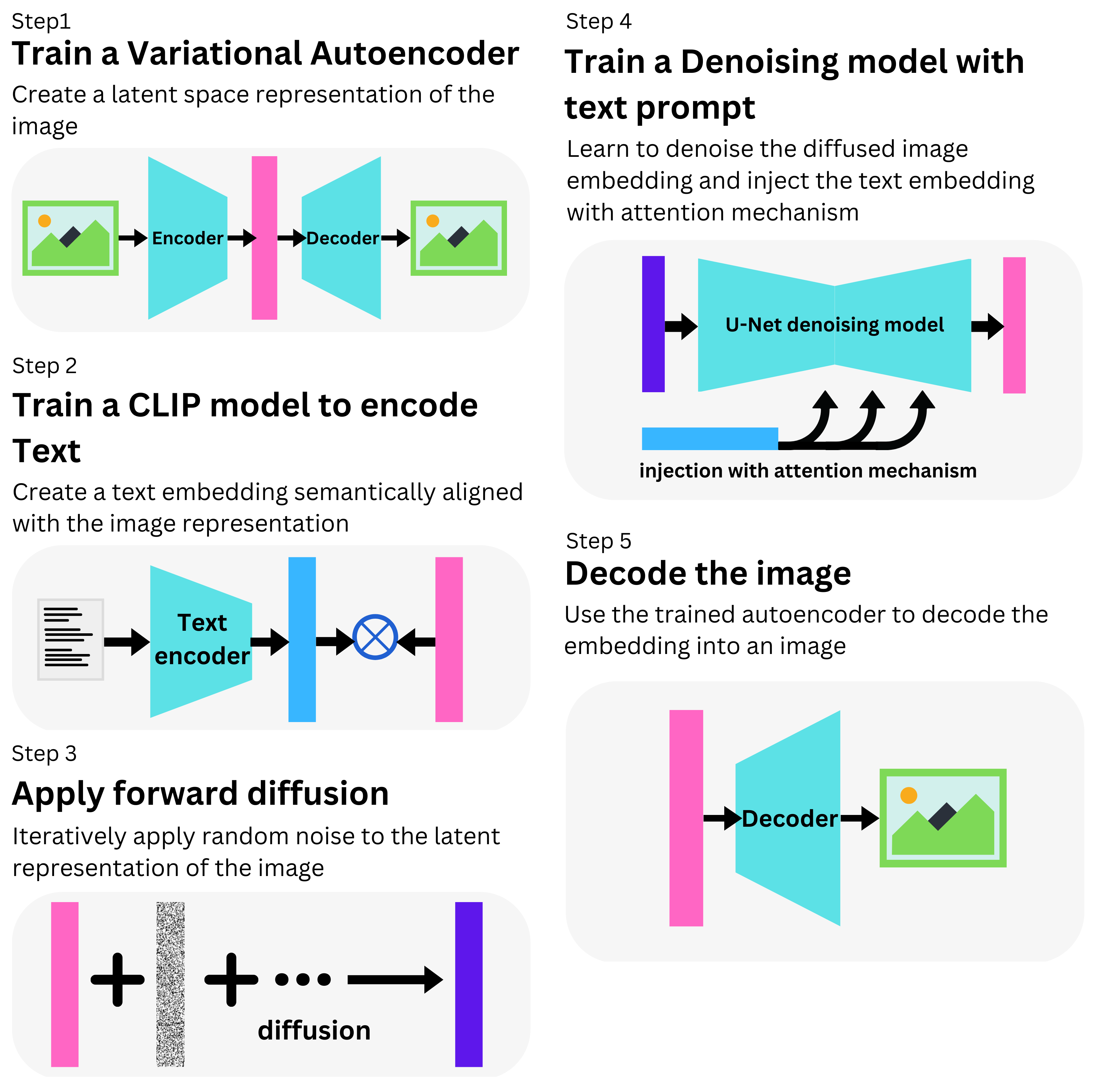
You can find the article here: Stable Diffusion article. Fun model!
But how do you generate those cool animations?
Check out the one I did in Replicate: my Stable Diffusion animation. Those animations are mostly due to the fact that it is easy to interpolate between 2 images or 2 text prompts in the latent space (embedding representations). The DALL-E 2 article explains that pretty well: [12].
You need a start and end prompt. I chose "A picture of a bear" and "A picture of an apple".
You then encode those texts in the latent space using the text encoder of the CLIP model [13], and you use the interpolation between the 2 text prompts to guide the denoising process of a random image for a few steps. This is just to anchor the denoising process in between the 2 prompts such that the animation is less jumpy.
You then create as many intermediary interpolations between the 2 prompts as you need frames in your animation, and continue the denoising process until you get clean images.
If you need smoother animations, you simply interpolate between the generated images in the latent space.

I have had a lot of fun playing with Andreas Jansson's implementation of animations with Stable Diffusion: [14]. He is using the pre-trained model on Hugging Face [2].
How to measure similarity between Text and Image data?
How would you know if an image is "similar" to its text caption? Conceptually, you could “simply” measure the cosine similarity between the image and the text. That is the idea behind CLIP (Contrastive Language-Image Pretraining [13]), the OpenAI algorithm underlying Dall-E 2 and Stable Diffusion. An intermediate latent vector representation of the image and the text is learned such that a high value of the dot product is indicative of high similarity. Here is how to build it
First, they created a dataset of 400M pairs (image, text) from publicly available datasets on the internet.
Then they used a 63M parameters Transformer model (A small GPT-2 like model [15]) to extract the text features T and a Vision transformer [16] to extract the image features I.
The resulting vectors are further transformed such that the text and image vectors have the same size. With N (image, text) pairs, we can generate N^2 - N pairs where the image does not correspond to the text caption. They then take the normalized dot product (cosine similarity) between T and I. If the text corresponds to the image, the model receives a label 1 and 0 otherwise, such that the model learns that corresponding images and text should generate a dot product close to 1.

This model has a lot of applications in zero-shot learning! In typical image classification, we feed the model with an image, and the model provides a guess from a set of predefined text labels used during the supervised training. But with CLIP, we can provide the set of text labels we want the model to classify the image into without having to retrain the model because the model will try to gauge the similarity between those labels and the image. We can virtually build an infinite amount of image classifiers by just switching the text labels! The CLIP article [8] showcases its robustness to generalize to different learning tasks without the need to retrain the model. In my opinion, this adaptability of ML models shows how much closer we are to true Artificial Intelligence! CLIP is an open-source project (https://github.com/openai/CLIP), so make sure to try it.
Let’s generate music with text prompts
Imagine if you could tell a Machine Learning model “play a funk bassline with a jazzy saxophone” and it would synthesize artificial music! Well actually, you don't need to imagine, you can just use it! Introducing RIFFUSION, a Stable Diffusion model trained on Spectrogram image data: Riffusion. The idea is simplistic:
Just pick a pre-trained Stable Diffusion model [2].
Take a lot of musics with their text descriptions and convert that into Spectrogram image data.
Fine-tune to the Stable Diffusion model.
You now have a model that can predict new spectrograms based on other spectrograms or text prompts. Just convert those spectrograms back to music.
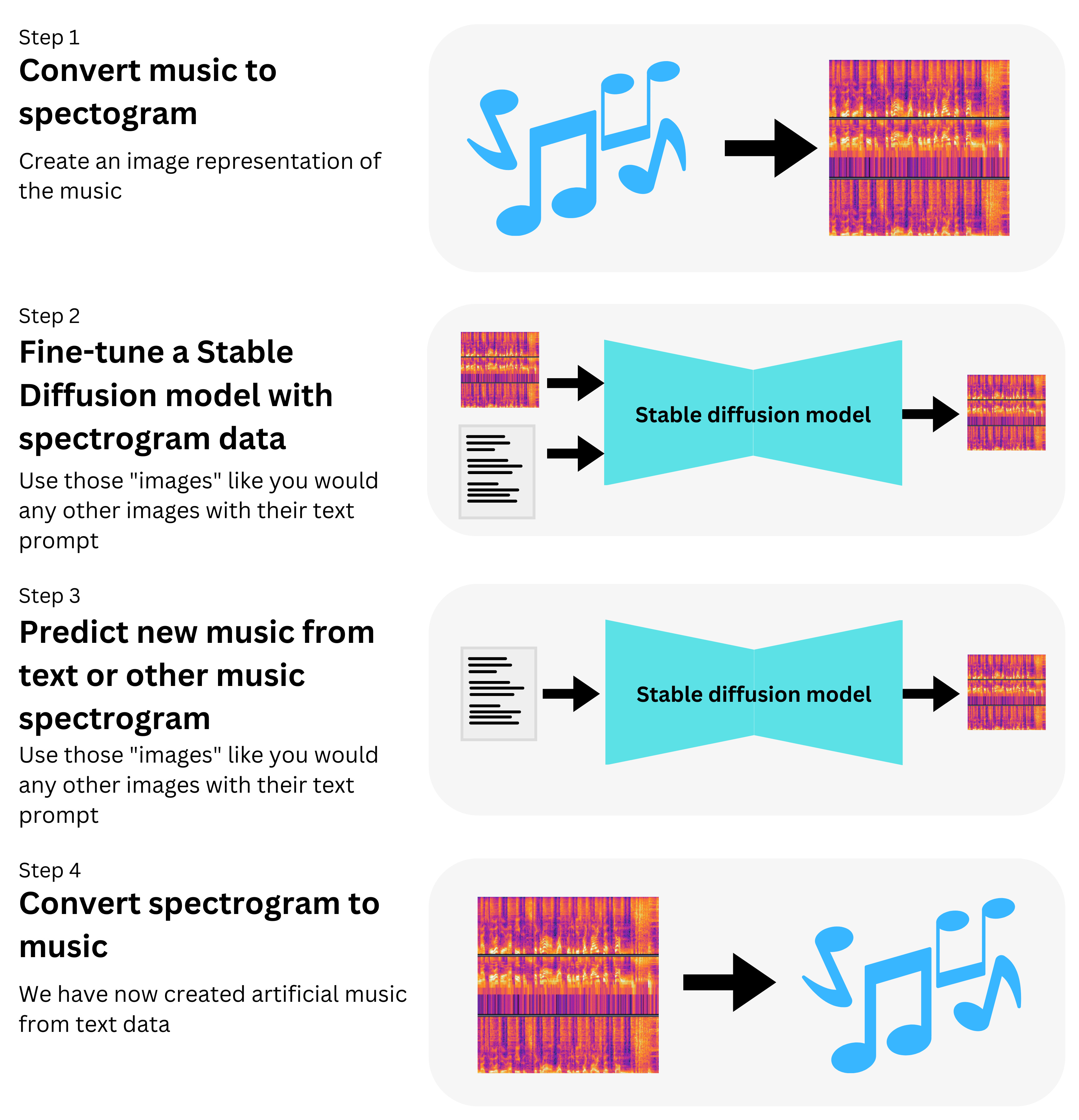
If you want more details on how to do it yourself you can follow the process here: https://www.riffusion.com/about.
Stable Diffusion’s Pytorch implementation: https://github.com/CompVis/stable-diffusion
Pre-trained version on HuggingFace: https://huggingface.co/spaces/huggingface-projects/diffuse-the-rest
LAION-5B dataset: https://laion.ai/blog/laion-5b/
Taming Transformers for High-Resolution Image Synthesis by Patrick Esser et al: https://arxiv.org/pdf/2012.09841.pdf
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric by Richard Zhang et al: https://arxiv.org/pdf/1801.03924.pdf
Image-to-Image Translation with Conditional Adversarial Networks by Phillip Isola et al: https://arxiv.org/pdf/1611.07004.pdf
Deep Unsupervised Learning using Nonequilibrium Thermodynamics by Jascha Sohl-Dickstein et al: https://arxiv.org/pdf/1503.03585.pdf
Learning Transferable Visual Models From Natural Language Supervision by Alec Radford et al: https://arxiv.org/pdf/2103.00020.pdf
U-Net: Convolutional Networks for Biomedical Image Segmentation by Olaf Ronneberger et al: https://arxiv.org/pdf/1505.04597.pdf
Perceiver IO: A General Architecture for Structured Inputs & Outputs by Andrew Jaegle et al: https://arxiv.org/pdf/2107.14795.pdf
High-Resolution Image Synthesis with Latent Diffusion Models by Robin Rombach: https://arxiv.org/pdf/2112.10752.pdf
Hierarchical Text-Conditional Image Generation with CLIP Latents by Aditya Ramesh et al: https://arxiv.org/pdf/2204.06125.pdf
OpenAI’s CLIP model: https://openai.com/blog/clip/
Andreas Jansson's implementation of animations with Stable Diffusion: https://replicate.com/andreasjansson/stable-diffusion-animation
OpenAI’s GPT-2: https://openai.com/blog/tags/gpt-2/
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale by Alexey Dosovitskiy: https://arxiv.org/pdf/2010.11929.pdf
Your article is awesome and I like the references to paper that are spread throughout the article.
Which software do you use to draw the diagrams though? These diagrams are very useful.