How I Automate Grading With LangChain And GPT-4

This is how I automate the grading of my students with LangChain and GPT-4 in the AiEdge School!
The Overall Design
The Django Application
The LangChain Application
Deploying on Elastic Beanstalk
Calling from Teachable
The Overall Design
I designed pretty intense coding projects for my Boot Camps, so I wanted to make sure I could focus on teaching without spending days grading them.

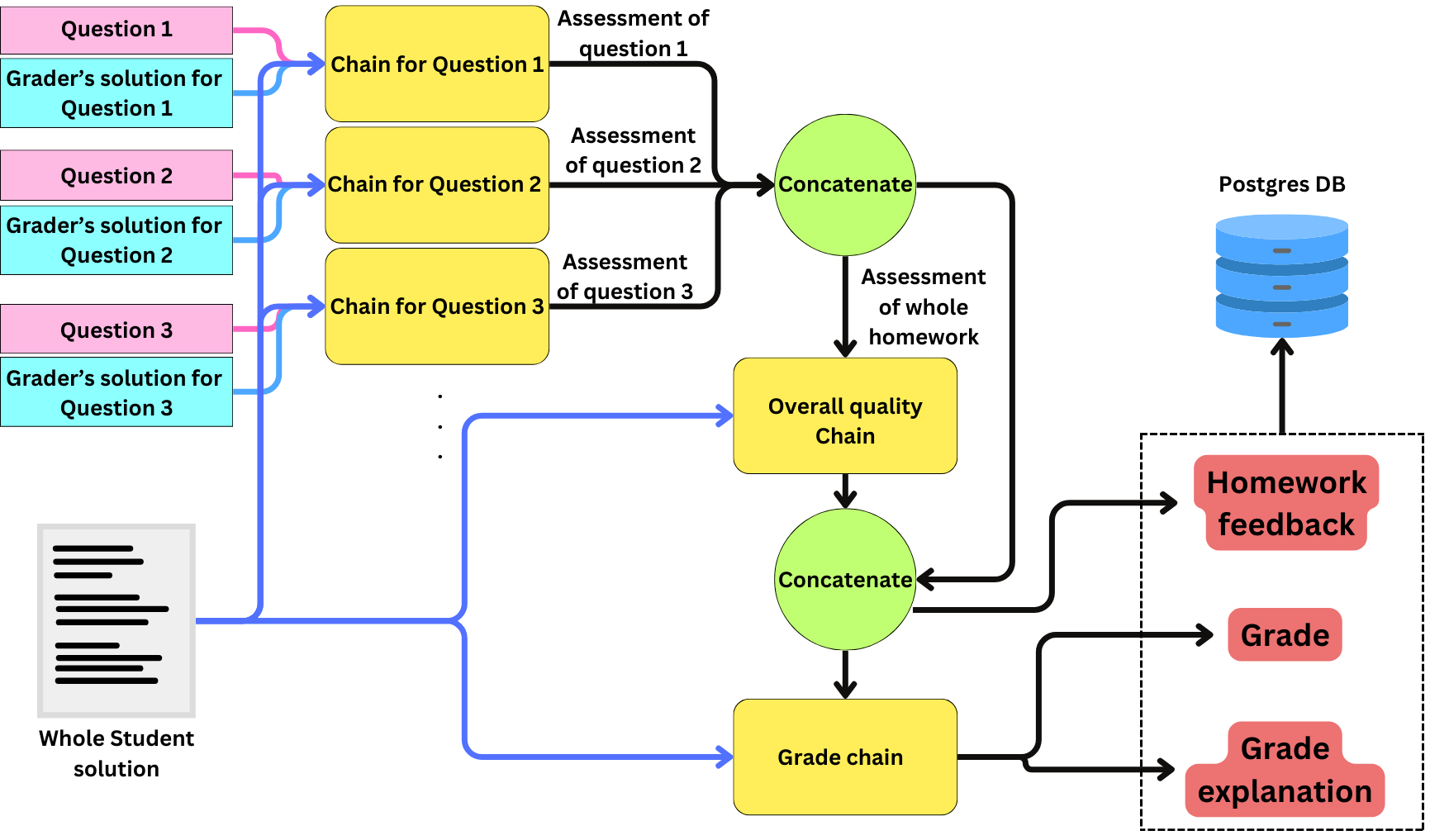
The automated grading tool is deployed as a Django application on AWS Elastic Beanstalk. I have always been a big fan of Django, and I have always found AWS EB easier to use than GCP App Engine. My app is basically a thin Restful API around a simple LangChain application. Because of the typical LLM latency, each job takes too long, so I need to use Celery workers to schedule the jobs in a RabbitMQ task queue so they can be executed asynchronously, and I store the resulting LLM's feedback and grading in a Postgres DB in a AWS RDS instance. My courses are hosted on Teachable, so I use custom HTML blocks for the API calls. My Langchain app is a pipeline of 3 successive chains.
The Django Application
I tend to use Django to build APIs. I also use the Django Rest Framework for the clean Restful API they provide. Before anything, we need to install those packages:
pip install Django djangorestframeworkWe start a Django project by just running the command:
django-admin startproject app Within the project, we can start an application by running
python manage.py startapp gradingI like to rearrange my Django project to look something like that
├── app
│ ├── settings.py
├── bootcamps
│ ├── langchain code
├── grading
│ ├── models.py
│ ├── serializers.py
│ ├── urls.py
│ └── views.py
├── manage.py
├── requirements.txtMy current Django application has only two data models: Student and Homework. In Django, a data “model“ is just an interface that maps between the Python code and the SQL database to interact with that data. The database connectivity is set within the app.settings.py file of the project.

The app has only two API endpoints: one for the students to pull their homework and one that creates the homework in the database and initiates the grading process with LangChain.

The grading process is initialized when a homework instance is created in the database. However, it takes too long (1-5 mins), and we don’t want to block the main thread waiting for the grading process to end. To solve for that, I schedule the grading process to happen in the background. I use Celery as an asynchronous task job queue and RabbitMQ as a message broker. Here is the process:

When a homework instance is created, I create a Celery task to grade the homework asynchronously
Celery will serialize the instructions related to that task and store this as a message in the RabbitMQ queue.
In parallel, a Celery worker always listens to the RabbitMQ queue to see if new messages appear. The RabbitMQ queue allows for the queueing of multiple tasks if multiple requests happen at once.
If the Celery worker detects a new message in RabbitMQ, it deserializes the instructions and executes the task.
In practice, we just need to create a celery.py file with the initialization of the celery application:
# celery.py
import os
from celery import Celery
from django.db import connection
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'app.settings')
app = Celery('app')
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
app.config_from_object('django.conf:settings', namespace='CELERY')
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()We need to make it visible from the __init__.py file
# __init__.py
from .celery import app as celery_app
__all__ = ('celery_app',)And we need to set up the connectivity with the RabbitMQ queue within the settings.py file
# settings.py
CELERY_BROKER_URL = 'amqps://YOUR-RABBITMQ-URL:5671/'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_RESULT_BACKEND = 'django-db'
CELERY_TASK_SERIALIZER = 'json'├── app
│ ├── __init__.py
│ ├── settings.py
│ ├── celery.pyThe LangChain Application
My Langchain app is a pipeline of 3 successive chains. My first chain is provided with a set of questions and context, the student's solution, and my solution, and I ask the LLM to assess the solution. The questions typically involve implementing the functionalities of an ML solution. Because I have many questions, I break down the different questions into multiple prompts, and I use LangChain's batched interface to minimize latency. I tend to use GPT-4 for the 128K context size, but I will most likely switch to Claude Haiku as soon as I can increase the rate limit. It has a context size of 200K, and it is much cheaper, but the rate limit is so low it is almost unusable! In the following chain, I provide it with the whole student's solution (thanks to the 128K context size!), and I ask the LLM to assess the overall code quality of the solution. In the last chain, I use the question level and overall assessments as input to generate an overall grade. In the end, I get feedback, a grade, and an explanation for the grade that I save in the related homework instance in the database.
I found that if we ask the LLM for very simple and precise tasks, we can get very good results. The way I design my LangChain applications is by breaking down the overall logic of the problem to solve into very simple tasks and having a chain for each of those tasks. We can then combine the results of those tasks with a final chain.