


How to Approach Model Optimization for AutoML

Since I started my career in Machine learning, I have worked hard to automate every aspect of my work. If I couldn't develop a fully production-ready machine learning at the click of a button, I was doing something wrong! I find it funny how you can recognize a senior machine learning engineer by how little he works to achieve the same results as a junior one working 10 times as hard!
AutoML has always been a subject dear to my heart, and I wanted to talk today about how we should approach the model optimization problem from an automation standpoint. I want to address the different angles we should consider when building an AutoML pipeline and show you a basic example of a pipeline.
Join us for the Year’s Premier LLM & AI Observability Event in San Francisco on July 11 (Sponsored)

If you’re thinking about building AI-powered applications and improving quality and performance once in production, we hope you’ll meet us at Arize:Observe. Tech talks, panels, networking, and a happy hour.
Partner with us: damienb@theaiedge.io
The optimization space
The model selection is the component that involves the ML algorithmic components. When we talk about “model selection“, we mean searching for the optimal model for a specific training dataset. If we have features X and a target Y, we would like to learn what is the optimal transformation F from the data:
The term “optimal“implies we have a model performance metric, and the “optimal” model is the one that maximizes that metric.
There are different axes we can consider to optimize our model:
The model parameter space: this is the “space“we optimize when we “train” a model through statistical learning. The parameters are learned using an optimization principle such as the Maximum likelihood estimation principle.

The model paradigm space: Many supervised learning algorithms could be used to solve the same problem. Algorithms like Naive Bayes, XGBoost, or Neural Network could perform very differently depending on the specific dataset.

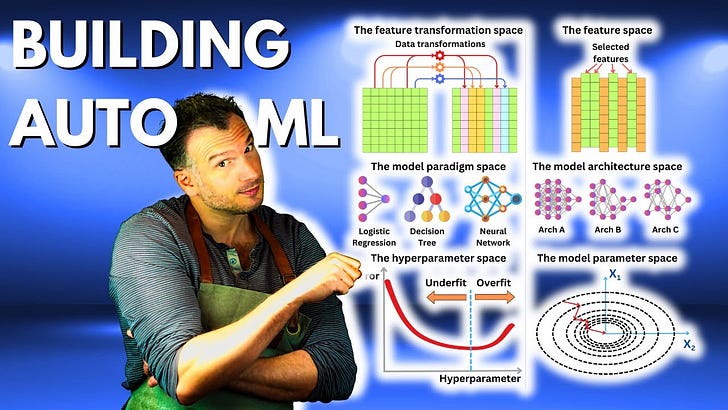
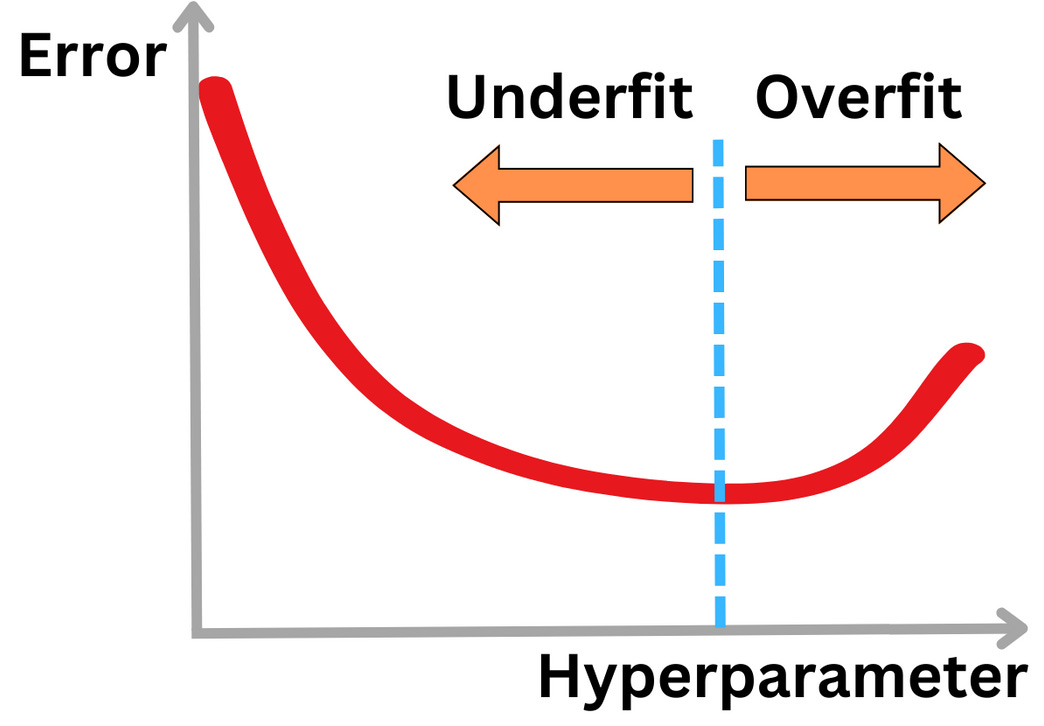
The hyperparameter space: those are the model parameters we cannot optimize using statistical learning, but they are choices we need to make to set up our training run.
The model architecture space: this is more relevant for Neural Networks. The model architecture can be characterized by a set of hyperparameters, but it tends to be a more complex search than typical hyperparameters. The search space dimension can be as big as 1040.
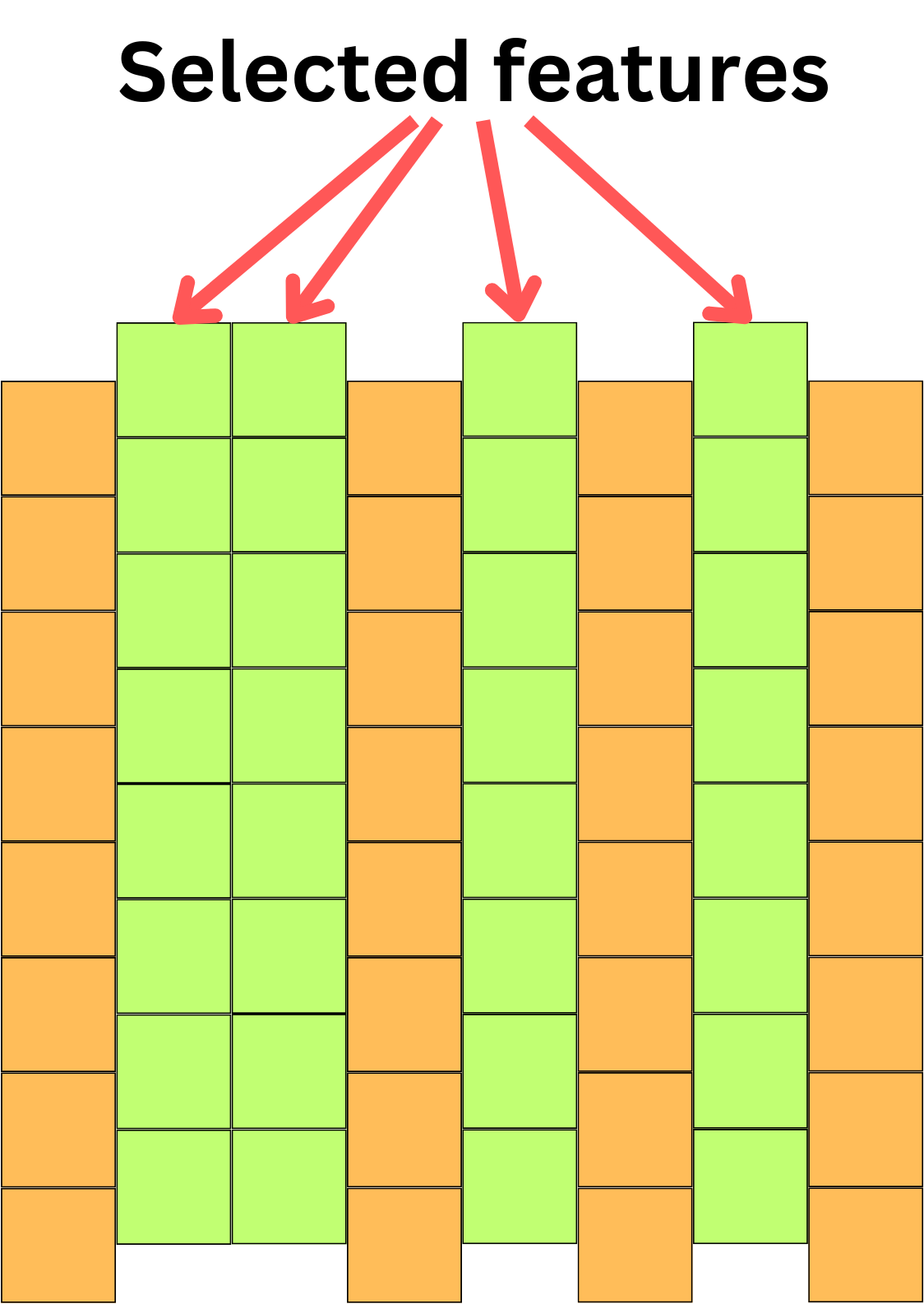
The feature space: We also need to select the right feature to feed to our model. Different models will react differently depending on the features we use. Too many features and we may overfit. Too few features and we may underfit.
The feature transformation space: We could consider many transformations to improve our model's performance, such as feature encoding or Box-Cox transformation.

The optimization strategies
Considering the complexity of those different subspaces, it is often impractical to attempt to solve the problem exactly, and we need to find ways to select a suitable model quickly.
Optimizing in sequence
The typical model optimization strategy is to optimize each axe separately in sequence. Modularizing the different optimization problems makes it easier for multiple people/teams to work on different aspects without stepping on each other’s toes.
A typical sequence of steps is as follows:

Optimizing the feature transformation space: this allows the potential injection of new features before selecting the right feature space.
Optimizing the feature space: now that the features are “better“because of the previous step, we can subset the best feature space.
Optimizing the model paradigm space: now that we have the “right“data, we can choose the right model.
Optimizing the model architecture space: if the model paradigm chosen in the previous step is a neural network, we need to optimize its architecture. Depending on how much flexibility we allow in the search, it is often easier to optimize the architecture first, independently from the hyperparameter search.
Optimizing the hyperparameter space: once we have a model paradigm and its architecture, it becomes easier to focus on the hyperparameters.
Optimizing the model parameter space: training the final model is the last step.
Joint-optimization
Optimizing in sequence will result in a suboptimal model because we are approximating the search. The feature selection module will select the “best“features in general, and the model paradigm module will determine the best model paradigm based on the features chosen in the previous step. However, for example, finding a model paradigm that would perform better had other features been selected is not impossible.

Therefore, we could consider jointly optimizing different axes together. For example, it is not uncommon to jointly optimize the feature space and the architecture space.

As always, with optimization problems, there is a balance between search accuracy and computational complexity. Each optimization space has a specific dimension. If there are N possible feature sets and M possible architectures, we need to search an N x M overall space to optimize for both axes jointly. However, if we optimize in sequence, the search complexity is only N + M. If, for example, we have 1M possible feature sets and 1M possible architectures, N x M = 1012 and N + M = 2M. This means it would take 500K (= 1012 / 2M) longer to find the exact optimal feature-architecture pair than an approximate one.
Many optimization processes have an iterative implementation, and we can use this to design pseudo-joint-optimization processes. For example, Recursive Feature Elimination (RFE) is a typical feature selection technique where Evolutionary algorithms such as Genetic algorithms (GA) are often used for architecture search. Both methods are iterative and converge slowly to an optimal solution.
We could merge those iterative processes to obtain a pseudo-joint optimization.
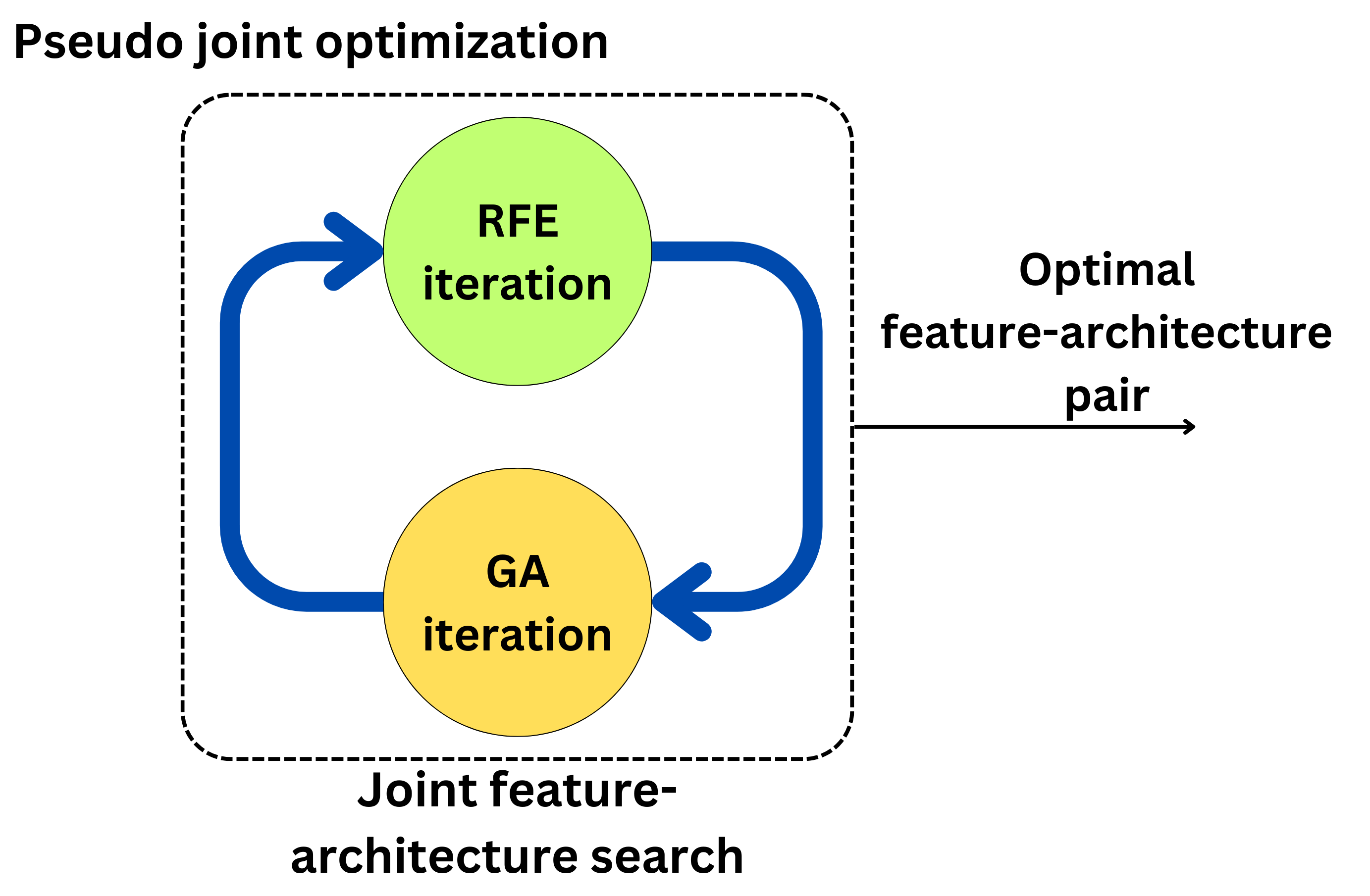
The search is still approximated (so fast), but the feature search considers the results from the architecture search and vice-versa.
SPONSOR US
Get your product in front of more than 64,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - tens of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
To ensure your ad reaches this influential audience, reserve your space now by emailing damienb@theaiedge.io.