

How to ARCHITECT a search engine like Google Search
Machine Learning System Design fundamentals

How would you ARCHITECT a search engine like Google Search? That is a very common Machine Learning System Design interview question. We are going to break it down into the following points:
The overall architecture
The role of the PageRank algorithm
The offline metrics and online experiments

The overall architecture
There are more than 100B indexed websites and ~40K searches per second. The system needs to be fast, scalable and needs to adapt to the latest news!
When a query is created, it goes through a spell check and it is expanded with additional terms such as synonyms to cover as well as possible the user's query. We know Google uses RankBrain and it is used only 10% of the time. It uses a word vector representation to find semantically similar words.
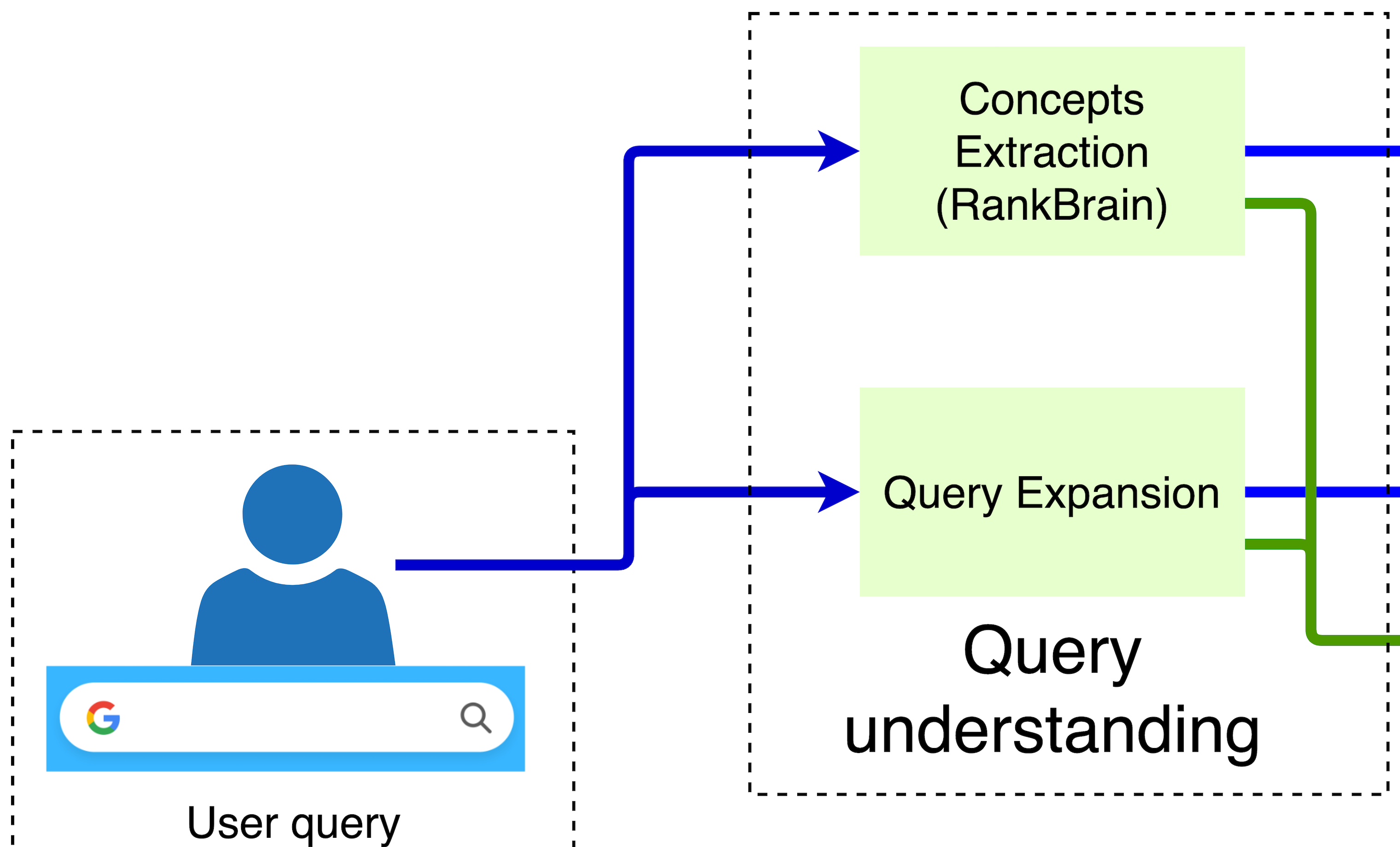
The query is then matched against a database, very likely by keyword matching for very fast retrieval. A large set of documents (~1B) are then selected. A small subset of those documents is selected using simple (fast) heuristics such as PageRank and other contextual information.

The ranking process happens in stages. The results go through a set of Recommender engines. There is most likely a simple Recommender Engine first ranking a large amount of documents (maybe 100,000 or 10,000 documents) and a complex one refining the ranking of the top ranked documents (maybe 100 or 1000). At this point, there might be tens of thousands of features created from the different entities at play: the user, the pages, the query, and the context. Google captures the user history, the pages interaction with other users, the pages natural language semantic, the query semantic, … The context relates to the time of the day, day of the week, … but also the current news of the day.

We will most likely need different model types for different languages, regions, platforms (website, mobile apps, …), document types, … There might be models that specialize in the pure search but I expect there are models that specialize in further filtering such as age appropriate websites or websites containing hate speech.
A typical server can handle 10,000 HTTP requests per second, but the limiting latency factor is mostly coming from the machine learning models. For example, if ranking 10,000 documents takes ~200 ms, that means we need ~8000 ML servers up at all times to handle the 40K/s requests.
Because Google is a search engine for multiple types of documents, we have a Universal Search Aggregation system to merge the search results. After the user is served with the results, we can use user engagement to assess the models in online experiments and aggregate the training data for following model developments and recurrent training processes.

There is a lot of talk around how ChatGPT could threaten Google Search. It is undeniable that ChatGPT “remembers” information, but the information is unstructured and does not come close to the robustness of information provided by Google Search. Second, I am pretty sure that Google has the capability to build a similar model.
The role of PageRank

Is PageRank still used as part of Google Search? Yes we know it is as we can see in the list of systems that are currently in use: the Google ranking systems guide. PageRank is a metric of the importance of a website as measured by how connected that website is to others [1]. It was developed by Google’s founders (Sergey Brin and Lawrence Page) and it used to be the main way websites were ranked in Google Search, leading to its success at the time. Now searches are personalized where PageRank is a global metric. We don't know how it is used, but we can pretty much guess!
A Google search happens in stages. First, the search query is expanded and used to perform an initial document selection. This document selection is driven by keywords matching in a database. If I type today "google search", Google tells me there are about 25B results related to my search.
Then the results go through a set of Recommender engines. As explained above, there is most likely a simple Recommender Engine first ranking a large amount of documents (maybe 100,000 or 10,000 documents) and a complex one refining the ranking of the top ranked documents (maybe 100 or 1000). Who cares about the quality of the ranking for documents far down the list of documents! The websites are probably already ranked by PageRank in the initial document selection as it can be computed at indexing time. There is no need to send all 25B documents to the first Recommender engine, and PageRank is most likely used as a cutoff to send a small subset.
However it is unlikely that PageRank is the only cutoff parameter as some websites would never get discovered. I would expect some simple geo-localization and context matching metrics as well as randomization to be used as well.
At this point, the ranking becomes personalized, and user data becomes the main factor, but PageRank is likely to still be used as a feature for all the successive Recommender Engines used in the search pipeline.
Obviously those are educated guesses as those information are not public.

The Offline Metrics

I may be wrong, but I think it is quite unlikely that Google Machine Learning engineers are using typical information retrieval metrics to assess the offline performance of the ML classifiers used within Google Search or a similar search engine during development! There are ~3.5 billion searches per day, with each search generating a lot of positive and negative samples. If you train a classifier on that data, you probably want to spam at least a few days of data if not more. It is an extremely class imbalanced problem, so you'll probably want to downsample the majority class for the computation to be manageable. That is still tens of billions of samples for each model development at least!
A metric like Normalized Discounted Cumulative Gain (NDCG) requires the concept of relevance (gain) to part of the data. That can be achieved with manual labeling but that is NOT going to be manageable with billions of samples. Metrics like Mean Reciprocal Rank (MRR) or Mean Average Precision (MAP) requires to know the true rank of the sample, meaning if I assess a classifier on a validation data, the predicted rank per search session is not going to be meaningful if we downsampled the data, and the metrics will be extremely dependent on the specific sampling scheme.
We could imagine that we downsample the number of sessions instead of the majority class, but this forces us to only keep the top samples shown by the algorithms. That seems unwise since this will prevent ML engineers from experimenting with new sampling methods in future developments and the models will never see very negative samples, which is a bit problematic if we want to build an accurate model. The same problem occurs with a metric like Hit Rate, since you need a window size.
If you order the search results by the probability of click provided by the classifier, log-loss (or cross entropy) is a completely acceptable ranking metric. It is a pointwise metric, which means it doesn't require us to know the predicted rank of the sample to compute a meaningful value. The probability itself will be biased by the false class distribution coming from downsampling, but this can be corrected by recalibrating the probability p using the simple formula:
where s is the negative sampling rate [2].
With a probability metric such as the log-loss, I expect more freedom for ML engineers to experiment with new techniques. For example, in the case of search engines, we could label with 1 the clicked links and 0 the non-clicked links, but you could also imagine that the negative samples are only sampled from unsuccessful sessions (where the users did not find the right link). In a successful session, the non-clicked links are not really “bad”, they are just less interesting to the user. To be able to assess across models and teams, it might be useful to use the normalized entropy metric [3] as anything above 1 is worse than random.
The online experiments
The online metrics validation is the true test of a Machine Learning model performance. That is where you want invest in term of the assessment quality. We know Google performed 757,583 search quality tests in 2021 using raters [4], so it is very likely that a model, before being proposed for online experiments, is passed through that testing round for additional validation. Online experiments are much more inline with the above information retrieval metrics. Because we know that raters are part of the process, it is likely that NDCG is predominantly used.

The anatomy of a large-scale hypertextual Web search engine by Sergey Brin and Lawrence Page: https://snap.stanford.edu/class/cs224w-readings/Brin98Anatomy.pdf
The Foundations of Cost-Sensitive Learning by Charles Elkan: https://eva.fing.edu.uy/pluginfile.php/63457/mod_resource/content/1/Elkan_2001_The_foundations_of_cost-sensitive_learning.pdf
Normalized Cross-Entropy: https://deychak.github.io/normalized-cross-entropy
Improving Search with rigorous testing: https://www.google.com/search/howsearchworks/how-search-works/rigorous-testing/
Fantastic Writeup. A suggestion that my readers gave me, that might be helpful to you was to have a summary section. Helps a lot with for my readers who are busy. They can read the quick highlights and decide if they want to dive in further
This is why I built https://searche.org
Check it out!!!!