


Multi-Vector Retriever
Hypothetical Queries
Parsing a Multimodal Document
Summarizing the Data
Describing the Images with LlaVA
Index the Data into a Database
Finalizing the RAG Pipeline
Below is the code used in the video!
Multi-Vector Retriever
With a muti-vector retriever, multiple vectors can correspond to the same data chunk.

Let’s install the libraries:
%pip install -U unstructured unstructured-inference onnx pytesseract python-poppler chromadbLet’s load some data and split it into large chunks
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
file_path = '~/Projects/Teaching/Introduction_Langchain/data/mixed_data/element_of_SL.pdf'
loader = PyPDFLoader(file_path=file_path)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=10000,
chunk_overlap=0
)
sl_data = loader.load_and_split(text_splitter=text_splitter)
sl_data
Let’s create a multi-vector retriever:
from langchain.vectorstores import Chroma
from langchain.storage import InMemoryStore
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers.multi_vector import MultiVectorRetriever
vectorstore = Chroma(
collection_name="statistical_learning",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)Let’s chunk the parent documents into child documents
import uuid
doc_ids = [str(uuid.uuid4()) for _ in sl_data]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
all_sub_docs = []
for i, doc in enumerate(sl_data):
doc_id = doc_ids[i]
sub_docs = child_text_splitter.split_documents([doc])
for sub_doc in sub_docs:
sub_doc.metadata[id_key] = doc_id
all_sub_docs.extend(sub_docs)Let’s index the parent documents with the child documents
retriever.vectorstore.add_documents(all_sub_docs)
retriever.docstore.mset(list(zip(doc_ids, sl_data)))Now the retriever can be used in an RAG pipeline:
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0)
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
verbose=True
)
chain.run("What is linear regression?")'Linear regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables. It assumes that the relationship between the variables can be approximated by a linear equation. The goal of linear regression is to find the best-fitting line that minimizes the difference between the predicted values and the actual values of the dependent variable. This line can then be used to make predictions or understand the relationship between the variables.'
Hypothetical questions for RAG
Let’s create a chain that creates possible questions about the documents we want to index:
from langchain.chains import LLMChain
from langchain.output_parsers import NumberedListOutputParser
prompt = """
Generate a numbered list of 3 hypothetical questions that the below document could be used to answer:
{doc}
"""
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo-16k')
chain = LLMChain.from_string(
llm=llm,
template=prompt,
)
chain.verbose = True
chain.output_parser = NumberedListOutputParser()Let’s create those questions for the book data:
from langchain.schema.document import Document
doc_ids = [str(uuid.uuid4()) for _ in sl_data]
question_docs = []
for i, doc in enumerate(sl_data):
result = chain.run(doc.page_content)
question_docs.extend([
Document(
page_content=s,
metadata={id_key: doc_ids[i]}
) for s in result
]) Let’s create a multi-vector retriever:
vectorstore = Chroma(
collection_name="hypo-questions",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)Now we are going to index the documents by the vector representation of the possible questions related to those documents:
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, sl_data)))Parsing a multimodal document
Let’s parse the article about LlaVA:
from unstructured.partition.pdf import partition_pdf
path = "./projects/live/multimodal/"
raw_pdf_elements = partition_pdf(
filename=path + "LLAVA.pdf",
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=path + 'images/'
)and let’s split the table data from the text data:
table_elements = []
text_elements = []
for element in raw_pdf_elements:
if element.category == "Table":
table_elements.append(element.text)
elif element.category == "CompositeElement":
text_elements.append(element.text)Summarize
We are going to index the data by their summaries. We create the summaries:
prompt = """You are an assistant tasked with summarizing tables and text.
Give a concise summary of the table or text.
Table or text chunk: {element}
"""
model = ChatOpenAI(temperature=0, model_name='gpt-4')
summarize_chain = LLMChain.from_string(
llm=model,
template=prompt
)
table_summaries = summarize_chain.batch(table_elements)
text_summaries = summarize_chain.batch(text_elements)Describe Images with LlaVA
Here is a diagram representing LlaVA:

We download the llama.cpp repo and the LlaVA models. We make sure to install cmake and git-lfs:
brew install git-lfs
brew install cmakeWe build the binaries:
mkdir build && cd build && cmake ..
cmake --build .And we generate the descriptions of the images using LlaVA:
%%bash
# Define the directory containing the images
IMG_DIR=~/Projects/Teaching/Introduction_Langchain/projects/live/multimodal/images/
TEXT_DIR=~/Projects/Teaching/Introduction_Langchain/projects/live/multimodal/text/
# Loop through each image in the directory
for img in "${IMG_DIR}"*.jpg; do
# Extract the base name of the image without extension
base_name=$(basename "$img" .jpg)
# Define the output file name based on the image name
output_file="${TEXT_DIR}${base_name}.txt"
# Execute the command and save the output to the defined output file
~/Projects/Teaching/Introduction_Langchain/projects/live/multimodal/llama.cpp/build/bin/llava \
-m ~/Projects/Teaching/Introduction_Langchain/projects/live/multimodal/llama.cpp/models/ggml-model-q5_k.gguf \
--mmproj ~/Projects/Teaching/Introduction_Langchain/projects/live/multimodal/llama.cpp/models/mmproj-model-f16.gguf \
--temp 0.1 \
-p "Describe the image in detail. Be specific about graphs, such as bar plots." \
--image "$img" > "$output_file"
doneLet’s load the resulting images:
import glob
from PIL import Image
text_path = "./projects/live/multimodal/text/"
images_path = "./projects/live/multimodal/images/"
text_list = sorted(glob.glob(text_path + "*.txt"))
img_list = sorted(glob.glob(images_path + "*.jpg"))
logging_header="clip_model_load: total allocated memory: 201.27 MB\n\n"
appendix='main: image encoded in'
# Read each file and store its content in a list
img_summaries = []
for i, text_path in enumerate(text_list):
with open(text_path, 'r') as file:
summary = file.read()
summary = summary.split(logging_header, 1)[1].strip()
summary = summary.split(appendix, 1)[0].strip()
img_path = img_list[i]
img = Image.open(img_path)
img_summaries.append({
'summary': summary,
'image': img
})Index the data into a database
We have 3 options when it comes to building multimodal RAG pipelines. The pure multimodal option:
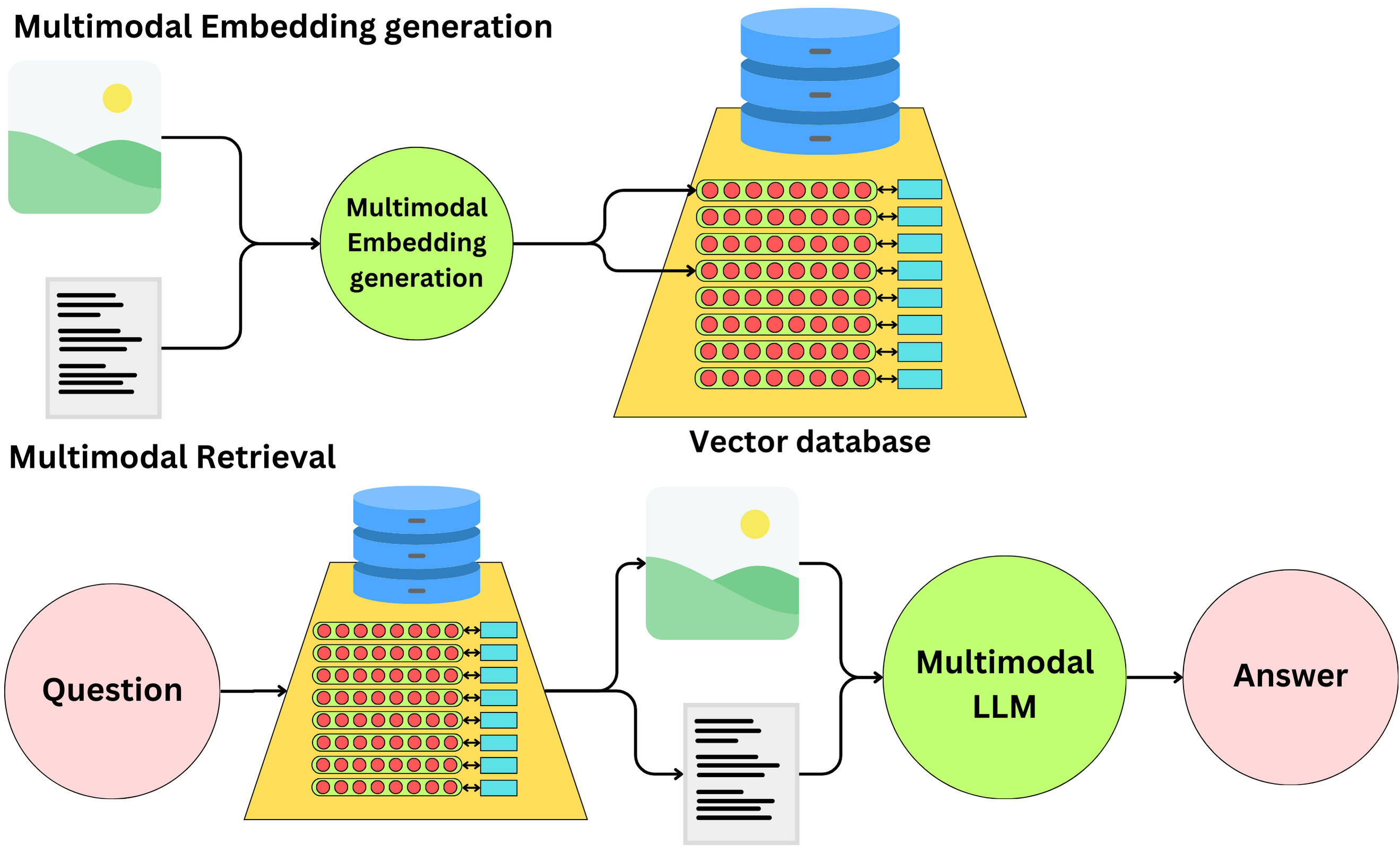
The multimodal retrieval option:

The data modes converted to their text representations option:

We are choosing the last option. We convert the lists into lists of documents:
def get_docs(text_list, ids):
return [
Document(
page_content=s,
metadata={id_key: ids[i]}
) for i, s in enumerate(text_list)
]
doc_ids = [str(uuid.uuid4()) for _ in text_summaries]
text_docs = get_docs(
[t['element'] for t in text_summaries],
doc_ids
)
summary_text_docs = get_docs(
[t['text'] for t in text_summaries],
doc_ids
)
table_ids = [str(uuid.uuid4()) for _ in table_summaries]
table_docs = get_docs(
[t['element'] for t in table_summaries],
table_ids
)
summary_table_docs = get_docs(
[t['text'] for t in table_summaries],
table_ids
)
img_ids = [str(uuid.uuid4()) for _ in img_summaries]
img_summary_docs = get_docs(
[i['summary'] for i in img_summaries],
img_ids
)And we index that data into a multi-vector retriever:
vectorstore = Chroma(
collection_name="llava_pdf",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
retriever.vectorstore.add_documents(summary_text_docs)
retriever.docstore.mset(list(zip(doc_ids, text_docs)))
retriever.vectorstore.add_documents(summary_table_docs)
retriever.docstore.mset(list(zip(table_ids, table_docs)))
retriever.vectorstore.add_documents(img_summary_docs)
retriever.docstore.mset(list(zip(img_ids, img_summary_docs)))Multimodal RAG
Now we can ask questions about that article:
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
verbose=True
)
chain.run('What makes LLava different from GPT-4')