

How To Build a Multimodal RAG Pipeline With LlamaIndex

What is LlamaIndex?
LlamaIndex is a package specialized for building Retrieval Augmented Generation (RAG) pipelines. It provides functionalities for the five stages of RAG:
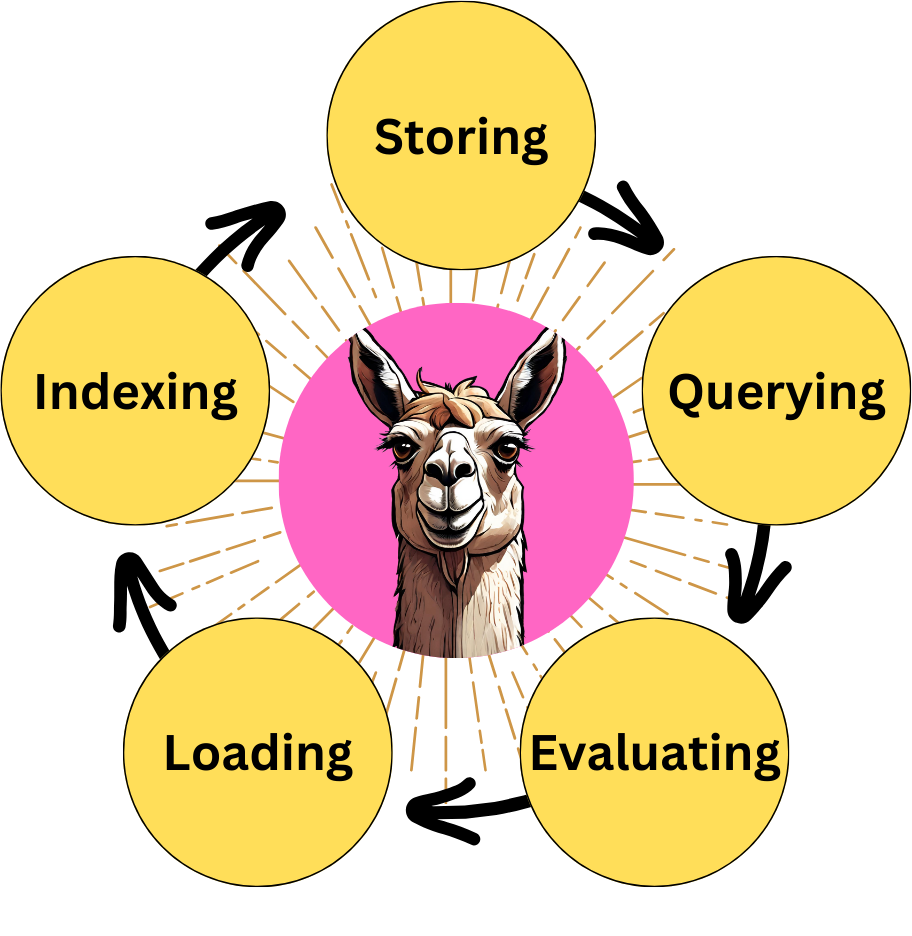
Loading: this refers to getting your data from where it lives – whether it’s text files, PDFs, another website, a database, or an API – into your pipeline. LlamaHub provides hundreds of connectors to choose from.
Indexing: this means creating a data structure that allows for querying the data. For LLMs, this nearly always means creating vector embeddings, numerical representations of the meaning of your data, as well as numerous other metadata strategies to make it easy to find contextually relevant data accurately.
Storing: once your data is indexed, you will almost always want to store your index, as well as other metadata, to avoid having to re-index it.
Querying: for any given indexing strategy, there are many ways you can utilize LLMs and LlamaIndex data structures to query, including sub-queries, multi-step queries, and hybrid strategies.
Evaluation: a critical step in any pipeline is checking how effective it is relative to other strategies or when you make changes. Evaluation provides objective measures of how accurate, faithful, and fast your responses to queries are.
It is very similar to LangChain, but it obviously focuses more on RAG. For now, LlamaIndex seems to be better ready for multimodal processing. I advise you to watch the following video to get more familiar with it:
Designing a Multimodal RAG pipeline
When it comes to building Retrieval Augmented Generation (RAG) pipelines, we need to consider the indexing pipeline and the retrieval pipeline. In the case of multimodal data, we need to adapt the two pipelines to be able to use images.
The typical text RAG retrieval pipeline works as follows:
A user asks a question
The question is encoded as a vector by an embedding model
The question vector is sent as a query to a vector database
The vector database returns the nearest neighbor vectors to the query along with the related data
The related is sent to an LLM along with the question for the LLM to have more context to answer the question fully
The LLM’s answer is returned to the user
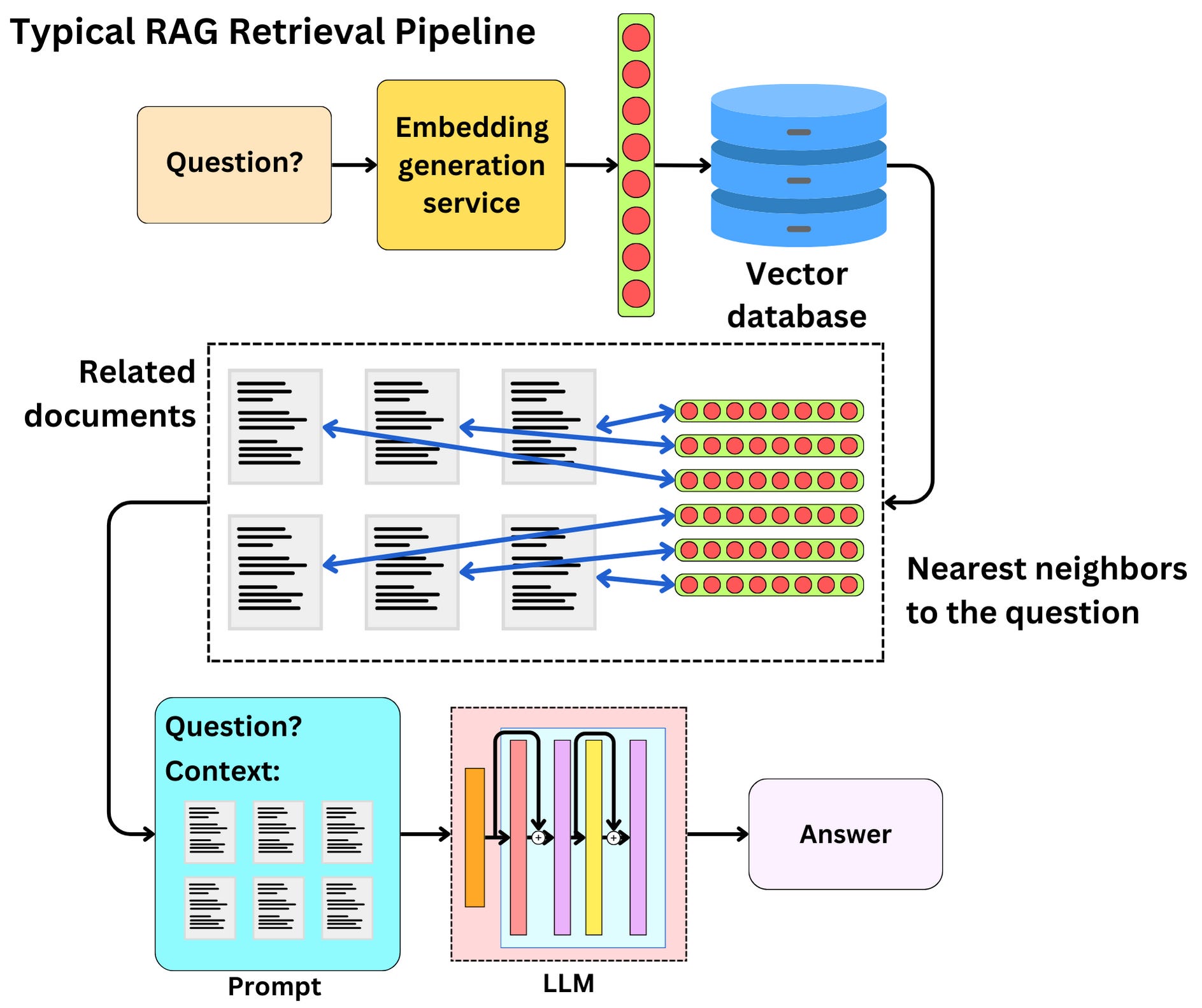
In the case of multimodal data (here, text and images), the LLM needs to be able to use image data as well for context. So we need a multimodal LLM!

The typical text RAG indexing pipeline works as follows:
The text is chunked in small documents
The smaller documents are converted to embeddings
The embeddings are indexed in a vector database

If we want to be able to use images as well, we need to make sure the embedding generation service can ingest images as well.
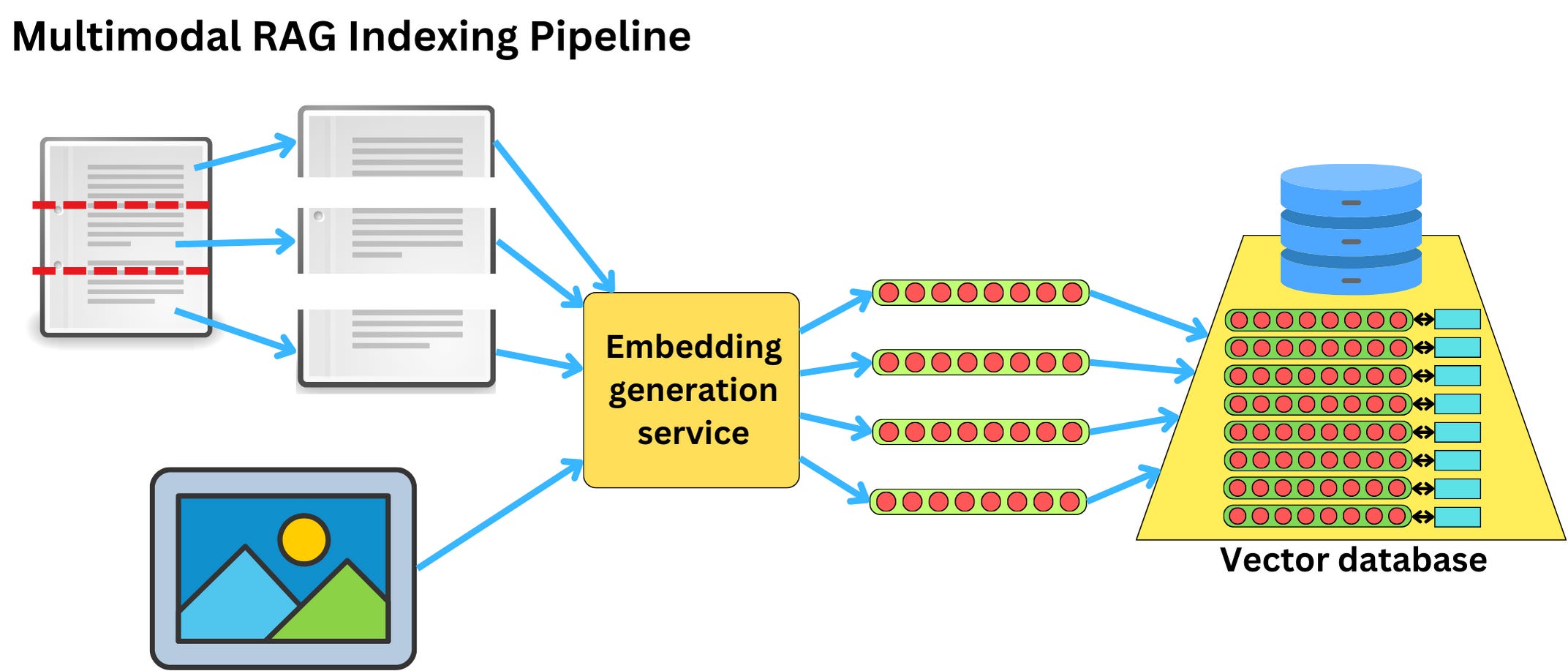
Not only that, but the embeddings need to be aligned across data modes. This means that a text document should have a very similar vector representation to the one of the image it is describing.

