

How to Build Ridiculously Complex LLM Pipelines with LangGraph!

A Simple RAG Pipeline
Rewriting the query
Inducing Self-Reflection
Providing feedback for generation retry
Limiting the number of iterations
Filtering the documents and extracting knowledge
Adaptive RAG
Corrective RAG

I have had a lot of resentment in the past months with the current state of LangChain. That library evolved very fast, and I shifted my feelings about it from “I love it“ to “I hate it“. I find their LangChain Expression Language (LCEL) unusable for most cases going beyond a basic chain, and their constant change in the API and documentation makes it impossible to understand how to use it properly.
When LangGraph came out by the same guys, I found the idea great, but I was scared to find myself back in a similar hellhole of an ever-changing framework going downhill. Now, being a bit more experienced with it, I find it to be one of the best tools on the market. It is not perfect, but it gave me the means to build complex stuff with ease, and I am recovering this long-lost feeling of pleasure that I once experienced with LangChain.
LangChain does too much, and as a consequence, it does many things badly. Scaling beyond the basic use cases with LangChain is a challenge that is often better served with building things from scratch by using the underlying APIs. LangGraph is simpler and, in many ways, can be used as a replacement for LCEL. The idea is to capture the orchestration of LLM calls into a Directed Graph structure. This is a very common strategy for orchestrating complex systems. It is the underlying principle behind KubeFlow for building ML pipelines on Kubernetes and AirFlow for building Data Engineering pipelines. Being able to focus only on the mechanism of a specific node in the graph at the time allows us to abstract away the complexity of the whole pipeline and engineer systems that can scale in complexity without making it harder on the engineers.
Let’s see an example of how we can move from a simple pipeline to a complex one with ease with LangGraph. You can find the code used in this article here.
A Simple RAG Pipeline
As a pipeline example, I like to use the Retrieval Augmented Generation (RAG) pipeline as it is an easy pipeline to mess up. In its simplest form, RAG is composed of a retriever and a generator:

The user question is used to retrieve the data that could be used as context to answer the question better. The data is typically in a database, such as a vector, SQL, or graph database.
The retrieved data is used as context in a prompt for an LLM to answer the question.
The Data
As an example of data to use for our RAG pipeline, I like to use the GitHub repository of LangChain. Considering how bad its documentation is, it is a good idea to complement it with our own custom RAG pipeline using the code base itself. I am storing the whole code base in a local vector database by using the OpenAI embedding model to index the data. First, I pull the GitHub repo with the LangChain GitLoader:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import GitLoader
from langchain_text_splitters import (
Language,
RecursiveCharacterTextSplitter,
)
loader = GitLoader(
clone_url="https://github.com/langchain-ai/langchain",
repo_path="./code_data/langchain_repo/",
branch="master",
)
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=10000, chunk_overlap=100
)
docs = loader.load()
docs = [doc for doc in docs if len(doc.page_content) < 50000]I chunk the code into chunks of 10000 characters maximum, and I remove any documents with more than 50000 characters. Then, I index the data into a local Chroma database:
vectorstore = Chroma(
collection_name="rag-chroma",
embedding_function=OpenAIEmbeddings(),
persist_directory="./chroma_langchain_db",
)
vectorstore.add_documents(documents=docs)
retriever = vectorstore.as_retriever()Here, I persist the data in a local folder, so I don’t have to reindex the data every time I run the code.
The Pipeline state
The idea behind LangGraph is to ensure that we keep track of the state of the pipeline. For a simple RAG pipeline, the state is captured by the user question, the retrieved documents, and the LLM generation. We capture the state as a Pydantic data model. Pydantic is a data validation library for Python:
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel
class GraphState(BaseModel):
question: Optional[str] = None
generation: Optional[str] = None
documents: List[str] = []The Retrieval node
At any point within the pipeline, I can look at the state, modify it, and make decisions based on its current value. Let’s implement the retrieval node:
def retriever_node(state: GraphState):
new_documents = retriever.invoke(state.question)
new_documents = [d.page_content for d in new_documents]
state.documents.extend(new_documents)
return {"documents": state.documents}The retriever node does the following:
It uses the question stored in the state as a query to the retriever.
The retrieved documents are passed to the pipeline state.
The Generation node
To implement the generation node, I need first to create a chain that can use as input the user question and the context and generate the response. Let’s create the prompt:
from langchain_core.prompts import ChatPromptTemplate
system_prompt = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Only provide the answer and nothing else!
"""
human_prompt = """
Question: {question}
Context:
{context}
Answer:
"""
rag_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)Let’s bind this prompt to the gpt-4o-mini model by OpenAI (because it is cheap) as a chain:
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
llm_engine = ChatOpenAI(model='gpt-4o-mini')
rag_chain = rag_prompt | llm_engine | StrOutputParser()Now, let’s pass this chain to the generation node:
def generation_node(state: GraphState):
generation = rag_chain.invoke({
"context": "\n\n".join(state.documents),
"question": state.question,
})
return {"generation": generation}The generation node does the following:
It uses the question and the documents stored in the state to pass to the generation chain.
The generation chain generates an answer, and we store it in the state.
Building the pipeline
To build the pipeline, we pass the state data structure to the LangGraph StateGraph class:
from langgraph.graph import END, StateGraph, START
pipeline = StateGraph(GraphState)Then, we add the nodes:
pipeline.add_node('retrieval_node', retriever_node)
pipeline.add_node('generator_node', generation_node)And we connect the nodes:
# We start by the retrieval
pipeline.add_edge(START, 'retrieval_node')
# We continue to the generation node
pipeline.add_edge('retrieval_node', 'generator_node')
# Once we generated the text, we end the pipeline
pipeline.add_edge('generator_node', END)To be able to use the pipeline, we need to compile it:
rag_pipeline = pipeline.compile()We can visualize the current pipeline:
from IPython.display import Image, display
display(Image(rag_pipeline.get_graph().draw_png()))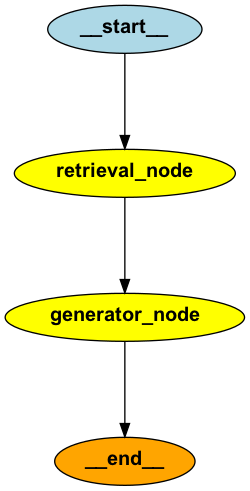
We can query that pipeline and stream the different events as they are being executed:
inputs = {"question": "What is LangChain?"}
for output in rag_pipeline.stream(inputs, stream_mode='updates'):
for key in output.keys():
print(f"Node: {key}")
print(value["generation"])
> Node: retrieval
> Node: generatorLangChain is a framework designed for developing applications powered by large language models (LLMs). It simplifies the entire application lifecycle, including development, productionization, and deployment, through a set of open-source libraries and tools. Key components of LangChain include model I/O, retrieval strategies, and agents, enabling the creation of context-aware reasoning applications.
Rewriting the query
Instead of using the original user question as a query to the database, it is typical to rewrite the question for optimized retrieval. For example, we can use the HyDE method.

