

How to Deploy a Streaming RAG Endpoint with FastAPI on HuggingFace Spaces

We often talk about Retrieval Augmented Generation these days, but how would we go about deploying one? Typically, when we think about a user application, we need to consider three components of the application:
The frontend: where the user can interact with the application.
The backend: where we connect to the database and proprietary data and where the private API keys can be used.
The LLM server: where the LLM is deployed.

We are going to assume that the LLM has already been deployed. For example, we can use meta-llama/Meta-Llama-3-8B-Instruct as our deployed LLM. It is available for free from a HuggingFace serverless endpoint. On the frontend, we are going to use Streamlit for simplicity, and on the backend, we are going to use FastAPI and LangChain. We are going to build an application similar to the one deployed here:

The idea with Retrieval Augmented Generation (RAG) is to encode the data you want to expose to your LLM into embeddings and index that data into a vector database. When a user asks a question, it is converted to an embedding, and we can use it to search for similar embeddings in the database. Once we found similar embeddings, we construct a prompt with the related data to provide context for an LLM to answer the question. The similarity here is usually measured using the cosine similarity metric.
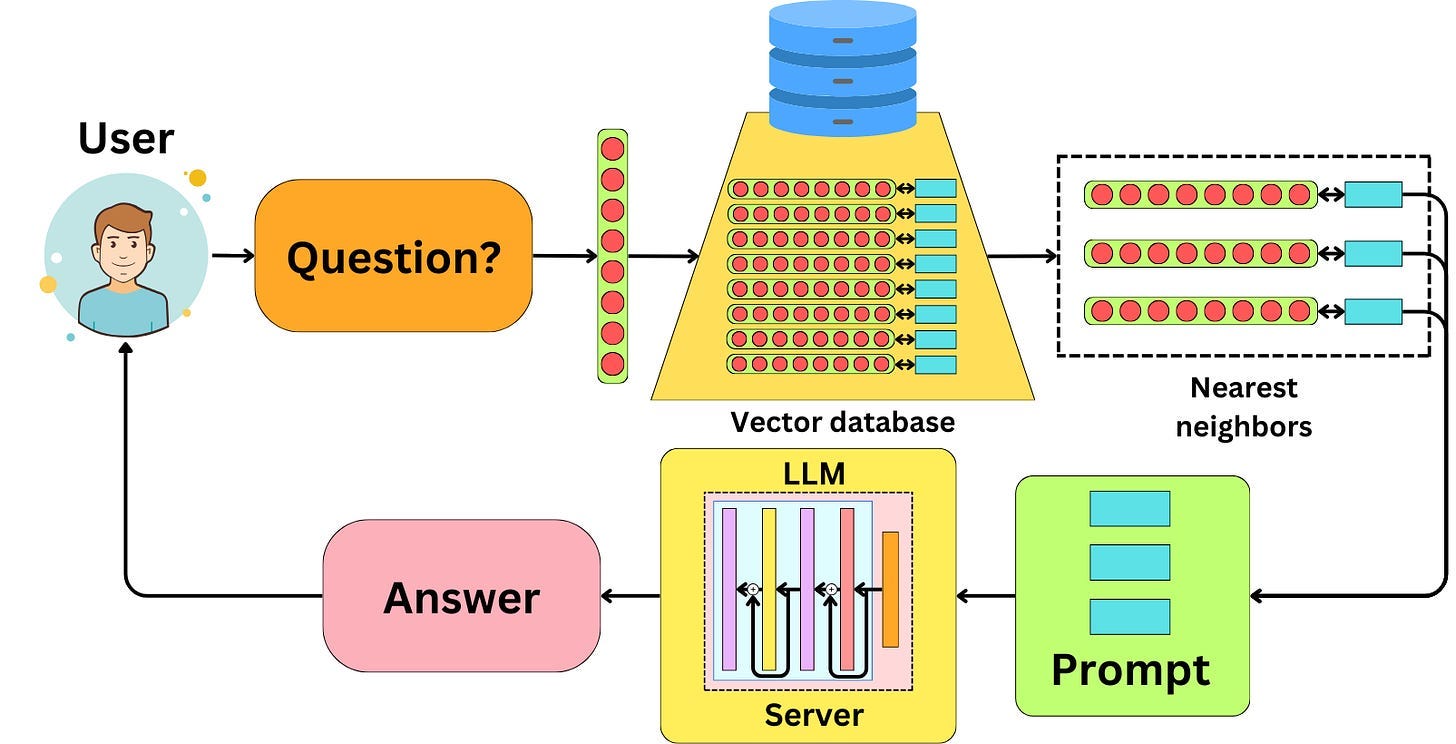
The RAG pipeline can be broken down into five components:
The indexing pipeline: we need to build the pipeline to index the data into a vector database.
The query: a query needs to be created from the question the user asks to search the database.
The retrieval: once we have a query, we need to retrieve the data from the database
The document selection: not all the data retrieved from the database must be passed as part of the context within the prompt, and we can filter less relevant documents.
Giving context to the LLM: once the right data has been selected to be passed as context to the LLM, there are different strategies to do so.

The Backend Application
In this part, we are going to deploy a FastAPI application as a Docker image by using the HuggingFace Spaces to host the endpoint. HuggingFace Spaces is not meant per se to be used as production-level backend applications, but it provides us with a simple hosting platform. Typically, it is used to build application demos. Here, we are going to use it to host a custom endpoint.
Setting up the HuggingFace Space
Before anything, we are going to set up our space. Because we don't need to host an LLM, we can deploy for free by using the free tier. Let’s go to the HuggingFace website and create a space for the backend application:

I am calling it “Backend”:
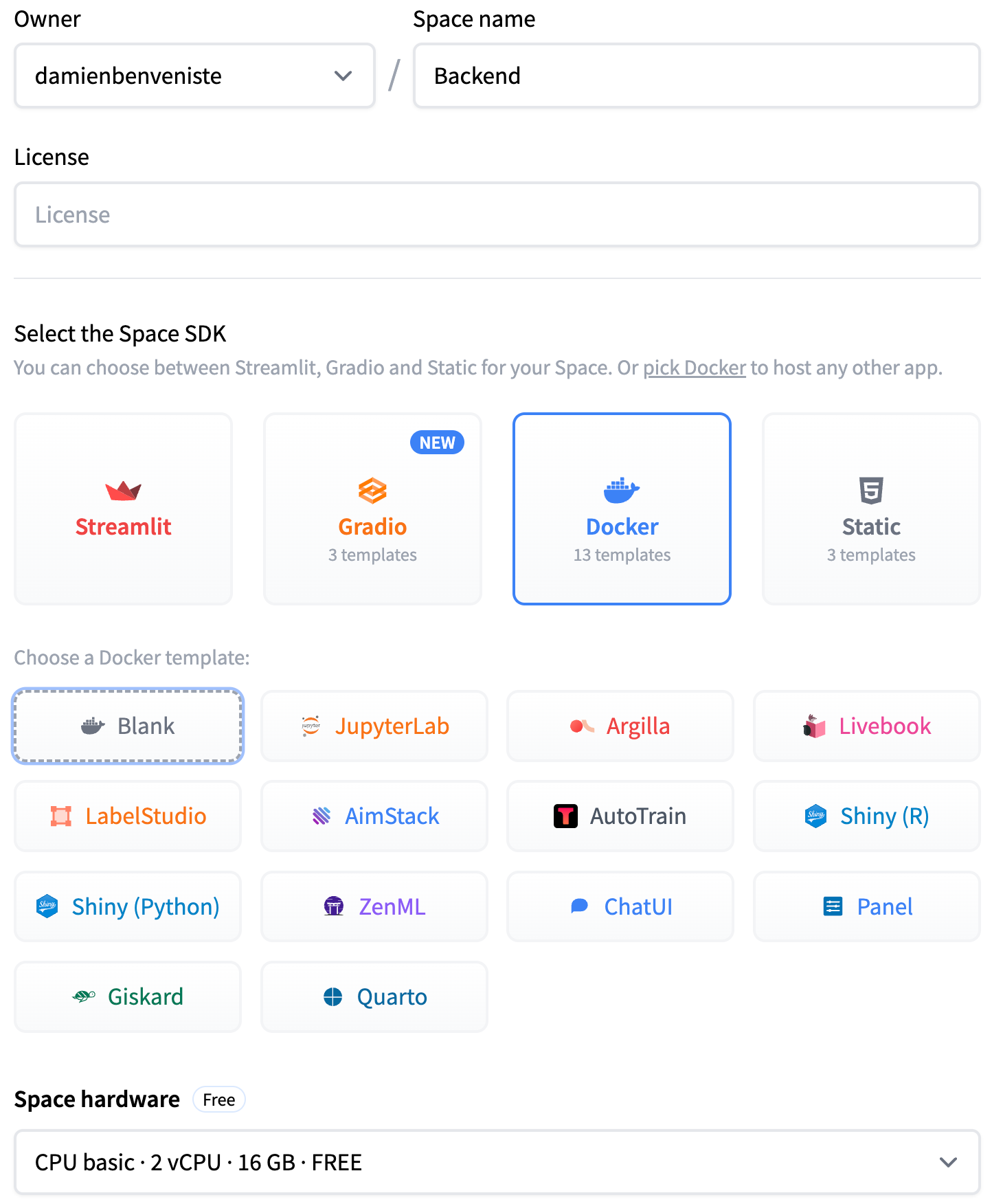
Once the space is created, you should see a template and create a small FastAPI application. We can clone the repo:
git clone https://huggingface.co/spaces/damienbenveniste/backendHere is the file structure of the application
├── Dockerfile
├── app
│ ├── callbacks.py
│ ├── chains.py
│ ├── crud.py
│ ├── data_indexing.py
│ ├── database.py
│ ├── main.py
│ ├── models.py
│ ├── prompts.py
│ └── schemas.py
└── requirements.txtThe Data models
FastAPI and LangChain use Pydantic to validate and parse the incoming and outgoing data. This provides control over what data is being used within the application. I am going to use a simple data model to parse the incoming data. In schemas.py:
# schemas.py
from pydantic.v1 import BaseModel
class UserRequest(BaseModel):
question: str
username: strThis assumes that on the frontend, the user will be able to provide its username and question. I am going to build an RAG pipeline that will use as input the user question but also the chat history to give the LLM a memory. Here is the related data model:
