

How To Optimize Your RAG Pipelines

The RAG pipeline
Indexing optimization
Query optimization
Retrieval optimization
Document selection optimization
Context optimization
The RAG pipeline
The idea with Retrieval Augmented Generation (RAG) is to encode the data you want to expose to your LLM into embeddings and index that data into a vector database. When a user asks a question, it is converted to an embedding, and we can use it to search for similar embeddings in the database. Once we found similar embeddings, we construct a prompt with the related data to provide context for an LLM to answer the question. Similarity here is usually measured using the cosine similarity metric:

The RAG pipeline can be broken down into five components:
The indexing pipeline: we need to build the pipeline to index the data into a vector database.
The query: a query needs to be created from the question the user asks to search the database.
The retrieval: once we have a query, we need to retrieve the data from the database
The document selection: not all the data retrieved from the database must be passed as part of the context within the prompt, and we can filter less relevant documents.
Giving context to the LLM: once the right data has been selected to be passed as context to the LLM, there are different strategies to do so.

Those are the five axes we could optimize to improve the RAG pipeline.
Indexing optimization
Indexing by small data chunks
In RAG, the data you retrieve doesn't have to be the data you used to index it! Typically, when we talk about RAG, we assume that the data is stored in its vector representation in a vector database. When we query the database, we then retrieve the most similar data to the query vector. But it doesn't have to be the case!
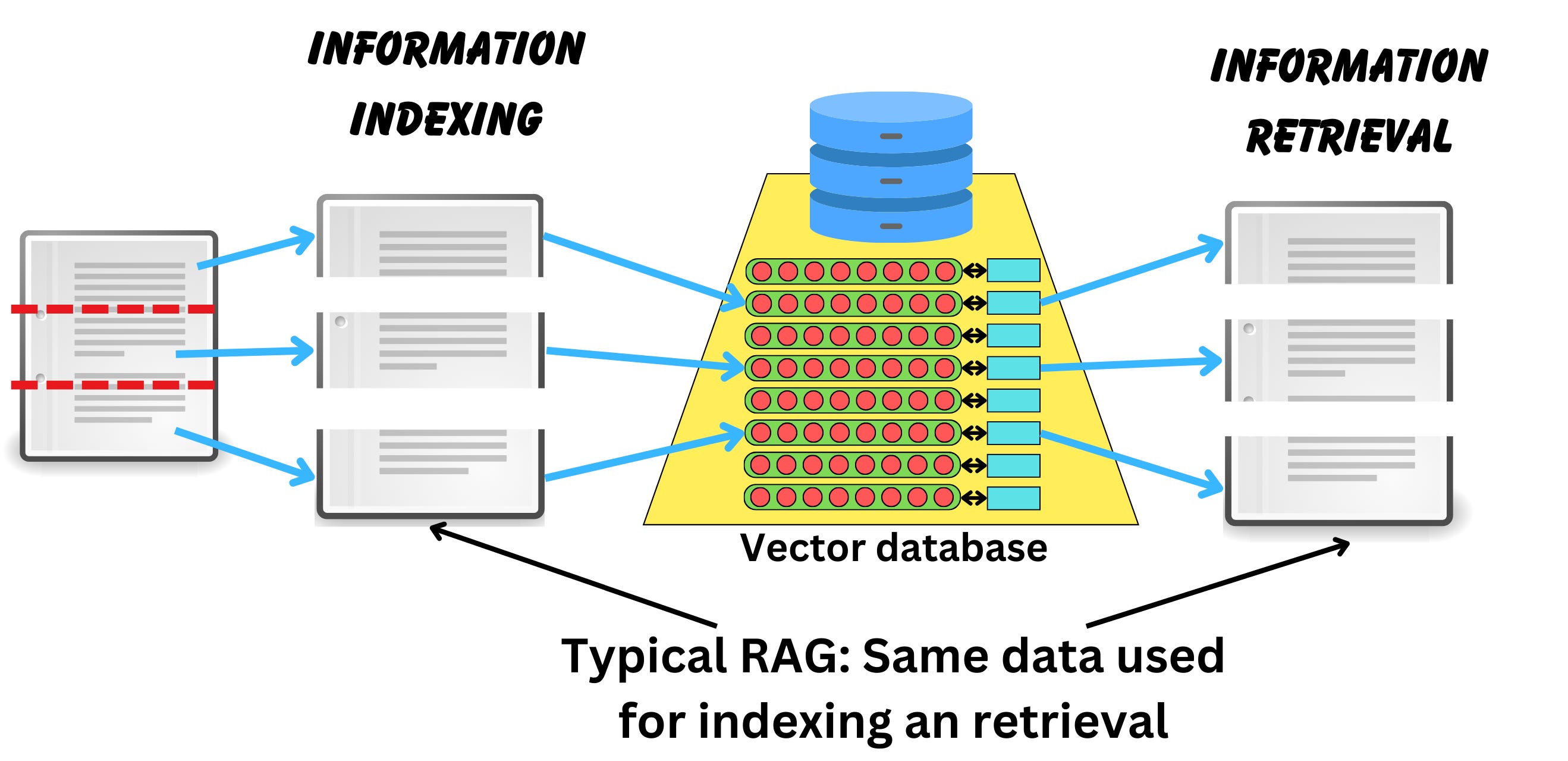
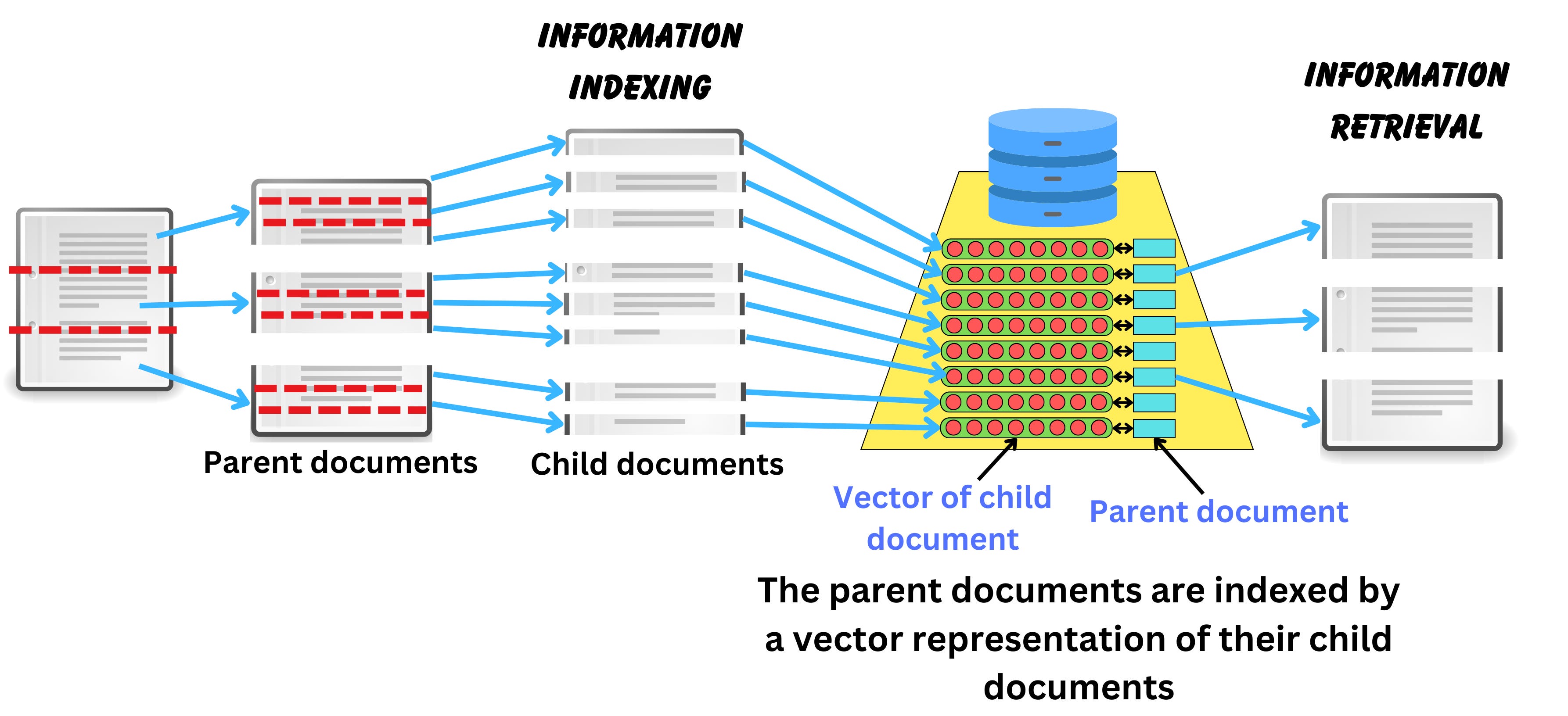
For example, the document could be quite large and could contain multiple conflicting information about different concepts. The query vector usually comes from a question about a single concept, so it is unlikely that the vector representation of the question will be similar to the large document. Instead, we could break down the large document into smaller chunks, convert those into their vector representations, and index the large document multiple times using the child documents' vectors. The small child documents have more chance to contain a unique concept, so they are great for indexing the data for similarity search, but they don't contain a lot of context to answer the question, so it is better to retrieve the larger document.
Indexing by the questions the document answers
We can also index the document by the questions that the document answers. As part of the indexing pipeline, we can have an LLM prompted to generate the questions that the document could answer. We then get the embeddings of the questions and index the document by those embeddings. When we have a question, the resulting query vector will be much more similar to the questions about the document than the document itself. However, the data retrieved should be the document so the LLM has all the context necessary to answer the question.

Indexing by the summary of the document
We could also index the document by its summary. Again, as part of the indexing pipeline, we could have an LLM tasked to summarize the incoming documents. The resulting text will be more concise and "semantically purer", so it could be a better option for a similarity search. This is a great option when your document contains tables (like .csv). Tables have numbers, and getting a question whose vector representation could be similar to the table's might be difficult. However, if, as part of the indexing pipeline, we have an LLM tasked to provide a text description of the table data, we can then index it using its text description. This will make it much easier on the similarity search! The retrieved data will be the original table data as it contains more information to answer the question.

