

How to Scale LLM Applications With Continuous Batching!

If you want to deploy an LLM endpoint, it is critical to think about how different requests are going to be handled. In typical machine learning models, it is ok to queue them, waiting for the machine learning server to be free for inference, but in the case of LLM, it can take seconds for a request to be treated. So, how do we scale to hundreds of requests per second? Let me show you how!
Deploying a text generation service is really different from most other machine learning applications! The latency of an LLM for responding to the prompt is such that it is not possible to use typical strategies like real-time inference. We could scale horizontally, but the cost associated with serving an LLM can be quite high if we are not careful.

We could batch the prompts together to make use of the parallelism provided by GPU machines. But how do we do that? Do we wait to have enough requests to start a batched decoding process? If we do that, it will induce high latency for the first requests, and the incoming requests during the decoding process will need to wait idle until the end of it.

One strategy that has been proposed is continuous batching by using the iterative nature of the decoding process. To generate text, an LLM will iteratively predict the next word and append it to the previous tokens that have already been decoded and the prompt. This process continues until the model predicts an end-of-sentence [EOS] token or if we reach the maximum number of tokens threshold. We can use this mechanism to construct a more dynamic batching process. At the end of each iteration, we can do the following:
We append the newly predicted tokens for each of the sequences at the end of the sequences.

If one or more prompt requests have been queued, we include them in the current batch, and we pad the batch to the longest sequence in the batch.

If one of the sequences reaches an ending condition, we evict the sequence from the current batch. We can return the whole sequence or the last token depending on whether we used a streaming process or not.
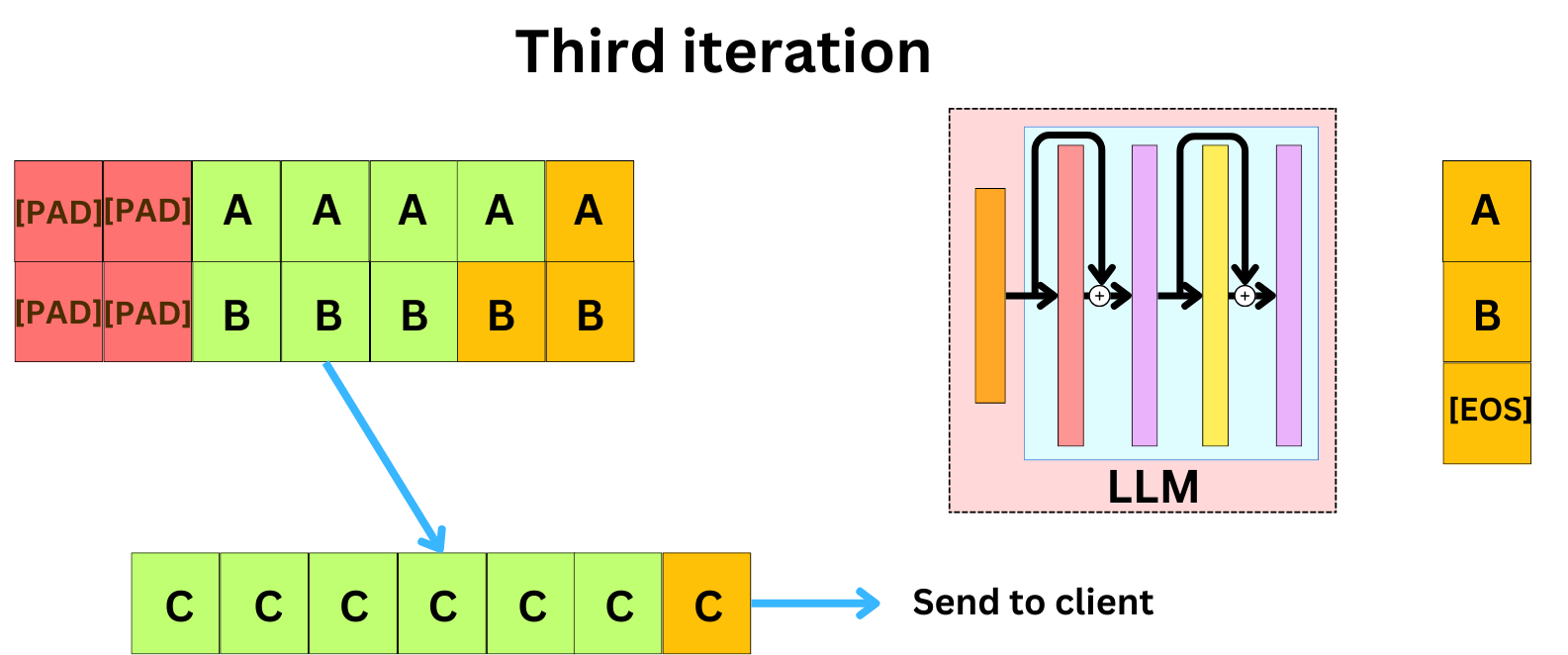
By dynamically rebatching the data during the decoding process, we increase the throughput while maintaining low latency. One problem that emerges is we lose the ability to preserve the low latency provided by KV-caching. As a new request joins the batch, its KV cache needs to be populated, and the initialization phase of those slows down the batch's decoding process.
This kind of strategy is unavoidable for text generation services with high request loads like ChatGPT, Gemini, or Claude, and it is a great way to minimize serving costs!