

How Twitter and TikTok Recommend Content to their Users
The main reason for their success!

Recommender Engine might be one of the most profitable Machine Learning Model paradigms right now but I think it doesn’t get the recognition it deserves! That is the bread and butter of many big tech companies. Today we dig in how Twitter recommends tweets and TikTok recommends videos. We look at:
The overview of Recommendation engines
The Twitter recommender engine
The TikTok recommender engine
Additional materials to learn more about recommenders: courses, book, Github repositories, Youtube videos

Recommendation engines overview
Recommender Engine might be one of the most profitable Machine Learning Model paradigms right now but I think it doesn’t get the recognition it deserves! There are many ways to generate money with ML but the niche business applications where recommendation engines are typically used make it a more certain high ROI ML application in general. The business value of recommendation engines is clear: personalized matching between a user and a product. That is the bread and butter of many big tech companies:
Search engines: Google, Amazon Product Search, …
Ads ranking: Google and Meta generate 65% of the world's digital ad revenue
Feed ranking: FB, Instagram, LinkedIn, …
Product Recommendation: Netflix’s landing page, …
The modern approach to recommender engine can be tracked back to the 2006 Netflix Recommendation contest where the Latent Matrix Factorization method won second place. In a supervised learning term, we use user data, product data and context data as input to estimate the affinity of a user to a product:

Those algorithms are peculiar because we want to use the same user and product population at training time than at inference time: in a sense, we want to overfit on user behavior!
Now Deep Learning dominates the field by extending on the original linear models and leading to many novel neural network architectures. Embeddings provide a natural mechanism to featurize the large users and products spaces and their related behavior history. Some architecture examples:
Multi gated Mixture of Experts for Youtube videos recommendation: “Recommending What Video to Watch Next: A Multitask Ranking System“.
Multi-Task Metric Learning for multi-stage inference when the product space is too large: “A multi-task framework for metric learning with common subspace“, “Homepage feed multi-task learning using TensorFlow“.
Two Tower models for retrieval: “Personalized recommendations - IV (two tower models for retrieval)“
Diversified recommendation with Graph Convolutional Networks: “DGCN: Diversified Recommendation with Graph Convolutional”.
Autoencoder-based recommender: “A survey of autoencoder-based recommender systems“.

The Twitter recommender engine
Twitter just open-sourced its recommendation algorithm for personalized tweet feeds and it is pretty much what you would expect: you get the "best" tweets, rank them with a machine learning model, filter the unwanted tweets and present them to the user. That is the way that most recommender engines tend to be used: search engines, ads ranking, product recommendation, movie recommendation, … What I find interesting is the way the different Twitter's ML algorithms come together to be used as multistage tweet selection processes for the ranking process.
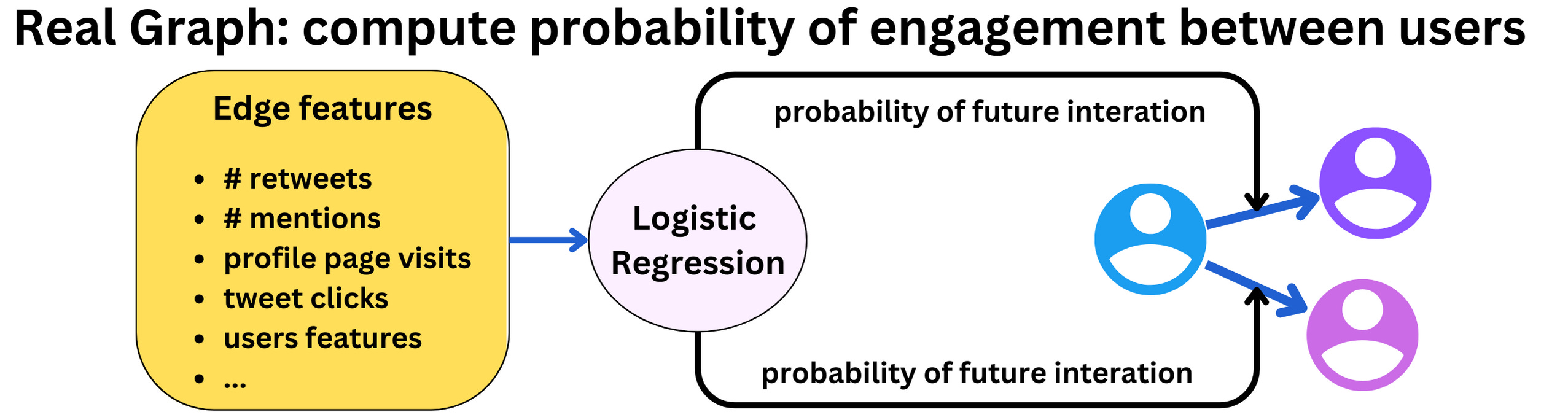
The first step in the process is to select ~1500 relevant tweets, 50% coming from people in your network and 50% outside of it. Real Graph (“RealGraph: User Interaction Prediction at Twitter“) is used to rank people in your network. It is a logistic regression algorithm running on Hadoop. Using features like previous retweets, tweet interactions and user features we can compute the probability that a specific user will interact again with other users.
For people outside your network, they use GraphJet (”GraphJet: Real-Time Content Recommendations at Twitter”), a real-time graph recommender system. Different users and tweet interactions are captured over a certain time window and a SALSA algorithm (random walk on a bipartite graph) is run to understand the tweets that are likely to interest some users and how similar users are to each other. SALSA is similar to a personalized PageRank algorithm but adapted to multiple types of objects recommendation. This process leads to metrics we can rank to select the top tweets.

The SimClusters algorithm (“SimClusters: Community-Based Representations for Heterogeneous Recommendations at Twitter“) clusters users into communities. The idea is to assign similarity metrics between users based on what influencers they follow. With those clusters, we can assign users' tweets to communities and measure similarity metrics between users and tweets.

The TwHIN algorithm (“TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation“) is a more modern graph algorithm to compute latent representations (embeddings) of the different Twitter entities (users, tweets, ads, advertisers) and the relationships between those entities (clicks, follows, retweets, authors, …). The idea is to use contrastive learning to minimize the dot products of entities that interact in the graph and maximize the dot-product of entities that do not. [Embeddings can be used to compute user-tweet similarity metrics and be used as features in other models.]

Once those different sources of recommendation select a rough set of tweets, we rank them using a 48M parameters MaskNet model (“MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask“). Thousands of features and 10 engagement labels are used to compute a final score to rank tweets.
For more information, take a look at the Twitter blog (Twitter's Recommendation Algorithm) and the GitHub repo.
The TikTok recommender engine
The TikTok recommender system is widely regarded as one of the best in the world at the scale it operates at. It can recommend videos or ads and even the other big tech companies could not compete. Recommending on a platform like TikTok is tough because the training data is non-stationary as a user's interest can change in a matter of minutes and the number of users, videos, and ads keeps changing.
