

Implementing a Language Agent Tree Search with LangGraph VS Burr

The Different Orchestration Frameworks
Tree of Thoughts
ReAct
The Language Agent Tree Search Method (LATS)
Implementing LATS with LangGraph
Implementing LATS with Burr
The Different Orchestration Frameworks

In the world of orchestration frameworks for LLM applications, a few axes have emerged. There are many overlaps in the capabilities of the different frameworks, but I tend to separate those by their specialties:
Micro-orchestration: I refer to Micro-orchestration in LLM pipelines as the fine-grained coordination and management of individual LLM interactions and related processes. It is more about the granular details of how data flows into, through, and out of language models within a single task or a small set of closely related tasks. It can involve things like:
Prompt engineering and optimization
Input preprocessing and output postprocessing
Handling of model-specific parameters and configurations
Chaining of multiple LLM calls within a single logical operation
Integration of external tools or APIs at a task-specific level
The best examples of that are LangChain, LlamaIndex, Haystack, and AdalFlow.
Macro-orchestration: Macro-orchestration in LLM pipelines involves the high-level design, coordination, and management of complex workflows that may incorporate multiple LLM interactions, as well as other AI and non-AI components. It focuses on the overall structure and flow of larger systems or applications. It involves things like:
Workflow design and management
State management across multiple steps or processes
Parallel processing and distributed computation
Error handling and recovery at a system level
Scalability and performance optimization of the entire pipeline
Integration of diverse AI services and traditional software components
Example operations: Multi-agent systems, long-running tasks with multiple stages, complex decision trees involving multiple LLM and non-LLM components. This is a newer type of orchestration for LLM pipelines, and LangGraph seems to be leading the charge. Burr by Dagworks is also one of the main actors in the space.
Agentic Design Frameworks: These frameworks focus on creating and managing autonomous or semi-autonomous AI agents that can perform complex tasks, often involving multiple steps, decision-making, and interaction with other agents or systems. The main characteristics are:
Allowing the creation of multiple specialized agents that can work together on complex tasks.
Agents can make decisions based on their programming, goals, and environmental inputs.
Inter-agent communication and coordination between different agents.
Include mechanisms for breaking down complex tasks into smaller, manageable subtasks.
Persistent memory and state management for agents across multiple interactions or task steps.
Users can define various agent roles with specific capabilities and responsibilities.
Allowing for human-in-the-loop oversight and intervention in the agent's processes.
Most frameworks have their own approach to agentic design, but Autogen and CrewAI tend to separate themselves by having a unique angle to the problem.
Optimizer frameworks: These frameworks use algorithmic approaches, often inspired by machine learning techniques like backpropagation, to optimize prompts, outputs, and overall system performance in LLM applications.
Key characteristics of optimizer frameworks:
They use structured algorithms to iteratively improve prompts and outputs.
They can automatically adjust prompts or system parameters to improve performance.
The optimization process is guided by specific performance metrics or objectives.
This is a newer category of orchestrator, and it has been led by frameworks like DSPY and TextGrad. To my knowledge, AdalFlow is currently the most mature framework in the domain.
In this newsletter, I want to show how to use micro-orchestration and macro-orchestration to implement the Language Agent Tree Search Method (LATS). This method can be viewed as a mix of the tree-of-thought and the ReAct methods. Specifically, I want to showcase the difference in implementation between LangGraph and Burr. You can find the whole code at the end of this newsletter.
Tree of Thoughts
Before diving into LATS, it can be helpful to understand the Tree of Thoughts method. Tree of Thoughts (ToT) is itself an extension of the Chain of Thoughts (CoT) strategy. The idea is to induce a step-by-step reasoning for the LLM before providing an answer. Here is an example of a typical CoT prompt:
Solve the following problem step by step:
Question: A store is having a 20% off sale. If a shirt originally costs $45, how much will it cost after the discount, including a 7% sales tax?
Let's approach this step-by-step:
1) First, let's calculate the discount amount:
20% of $45 = 0.20 × $45 = $9
2) Now, let's subtract the discount from the original price:
$45 - $9 = $36
3) This $36 is the price before tax. Now we need to add the 7% sales tax.
7% of $36 = 0.07 × $36 = $2.52
4) Finally, let's add the tax to the discounted price:
$36 + $2.52 = $38.52
Therefore, the shirt will cost $38.52 after the discount and including sales tax.
Now, solve this new problem using the same step-by-step approach:
Question: A bakery sells cookies for $2.50 each. If you buy 3 dozen cookies and there's a buy-two-get-one-free promotion, how much will you pay in total, including an 8% sales tax?
Solution:In this example, it is a one-shot example prompt, but it is typical to use few-shot example prompts. We can also induce step-by-step reasoning by using the zero-shot CoT approach:
Solve the following problem. Let's approach this step by step:
Question: A store is having a 30% off sale. If a shirt originally costs $60, how much will it cost after the discount, including an 8% sales tax?
Solution:The idea is that the LLM, by reading its own reasoning, will tend to produce more coherent, logical, and accurate responses.

Considering the tendency of LLMs to hallucinate, it is often a good strategy to generate multiple reasoning paths so we can choose the better one. This is commonly referred to as the Self-Consistency approach:

This approach allows one to choose the best overall answer, but it is not able to distinguish the level of quality of the different reasoning steps. The idea behind ToT is to induce multiple possible reasoning steps and to choose the best reasoning path:
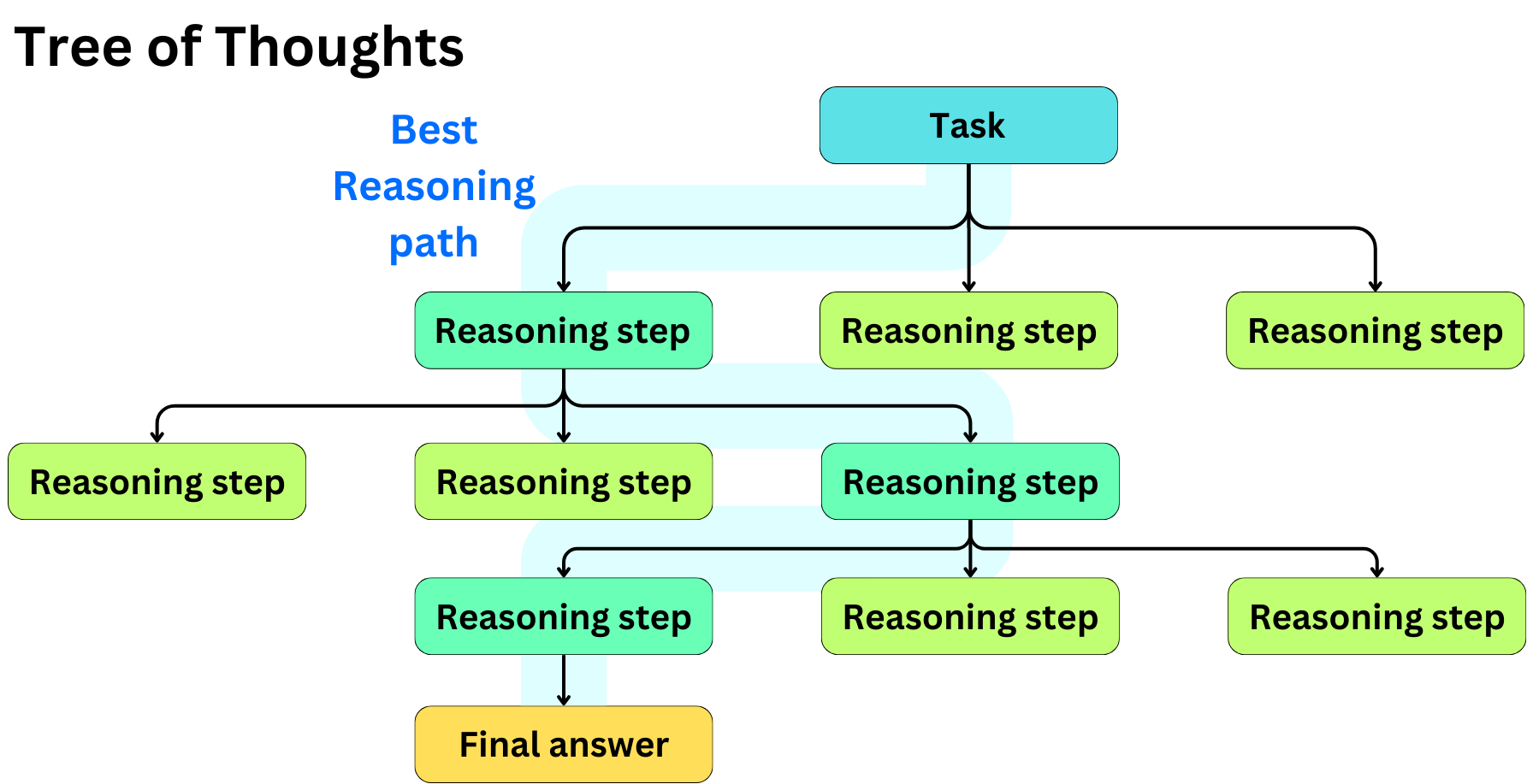
For example, here is how we could induce the generation of the next step:
Consider multiple approaches to solve the following problem. For each approach, provide the first step of calculation:
Question: A store is having a 30% off sale. If a shirt originally costs $60, how much will it cost after the discount, including an 8% sales tax?
Possible first steps:
1.
2.
3.
For each first step, briefly describe how you would continue the calculation. The resulting response would need to be parsed to extract the possible steps. The typical approach to understanding what step is better at each level is to quantitatively assess them with a separate LLM call. Here is an example of such a prompt:
Evaluate the following step in solving this problem:
Problem: A store is having a 30% off sale. If a shirt originally costs $60, how much will it cost after the discount, including an 8% sales tax?
Previous steps:
[Previous steps]
Current step to evaluate:
[Insert current step here]
Rate this step on a scale of 1-10 based on the following criteria:
1. Correctness: Is the calculation mathematically accurate?
2. Relevance: Does this step directly contribute to solving the problem?
3. Progress: How much closer does this step bring us to the final answer?
4. Consistency: How well does this step follow from the previous steps?
Provide a brief explanation for your ratings.Again, the output would need to be parsed to extract the relevant information. We can iteratively expand reasoning paths, assess them, and choose the better path:
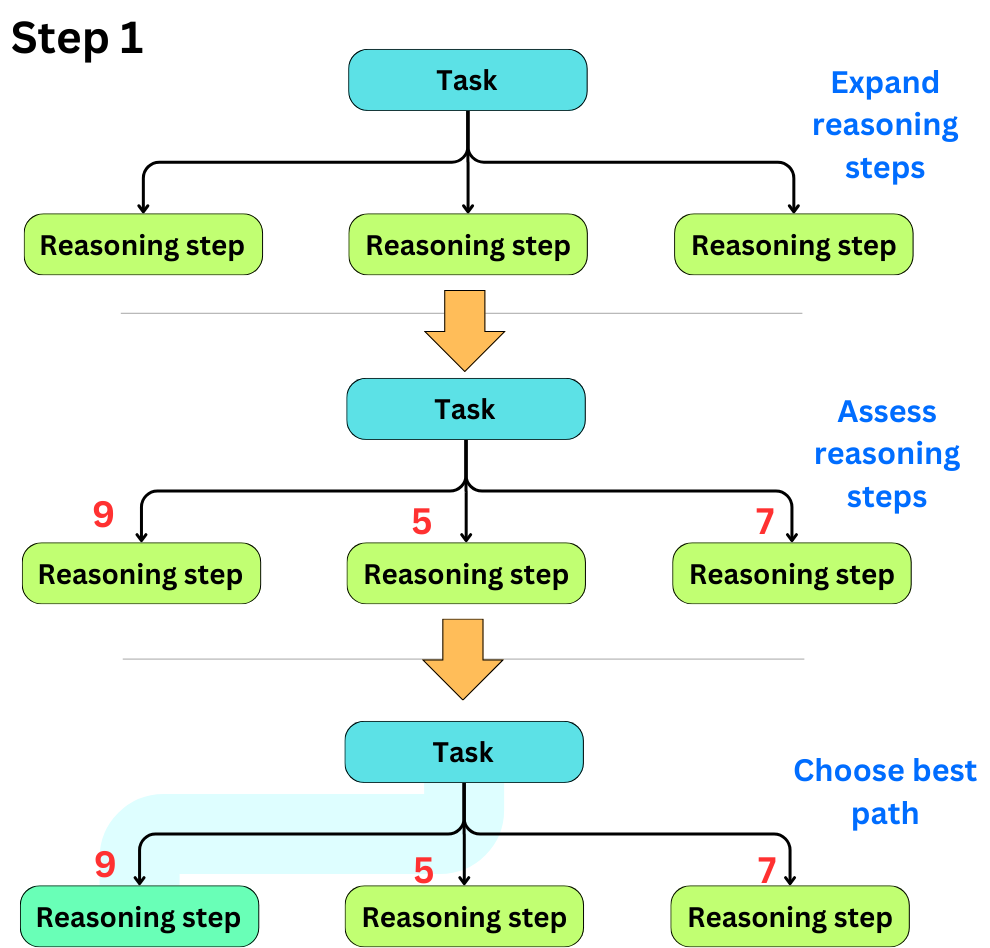
We can repeat this process at every level:

