


Prompt engineering is the set of techniques to construct prompts so you have a high level of control over the LLMs' output.
Many prompt engineering techniques are here to improve the accuracy of the LLM models but some of them are essential to augment LLMs with additional tools. We are going to look at the following techniques and how to implement them in LangChain:
Few-shot learning
Memetic proxy
Chain of Thought
Self-consistency
Inception
Self-ask
ReAct
Plan and execute
Below are the images and code used in the video!
Elements of a Prompt?
An LLM is very similar to a programming function with the Prompt being the input variable:

Let’s get a prompt with LangChain as an example
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
chat_model = ChatOpenAI()
conversation_chain = ConversationChain(
llm=chat_model
)
conversation_chain.prompt.templateThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:
Let’s dissect that prompt:

Few shot learning
With few shot learning we provide additional context to the LLM in the form of examples:

Let’s format examples specifically for a prompt
from langchain.prompts import (
FewShotChatMessagePromptTemplate,
ChatPromptTemplate,
)
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
{"input": "5+6", "output": "11"},
]
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
print(few_shot_prompt.format())Human: 2+2
AI: 4
Human: 2+3
AI: 5
Human: 5+6
AI: 11
Let’s now add instructions and an input argument for the human to ask a question
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are wonderous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
print(final_prompt.format(input='What is 3+3?'))System: You are wonderous wizard of math.
Human: 2+2
AI: 4
Human: 2+3
AI: 5
Human: 5+6
AI: 11
Human: What is 3+3?
Let’s feed that to an LLM
from langchain.chains import LLMChain
chain = LLMChain(
llm=chat_model,
prompt=final_prompt,
verbose=True
)
chain.run("What is 3+3?")
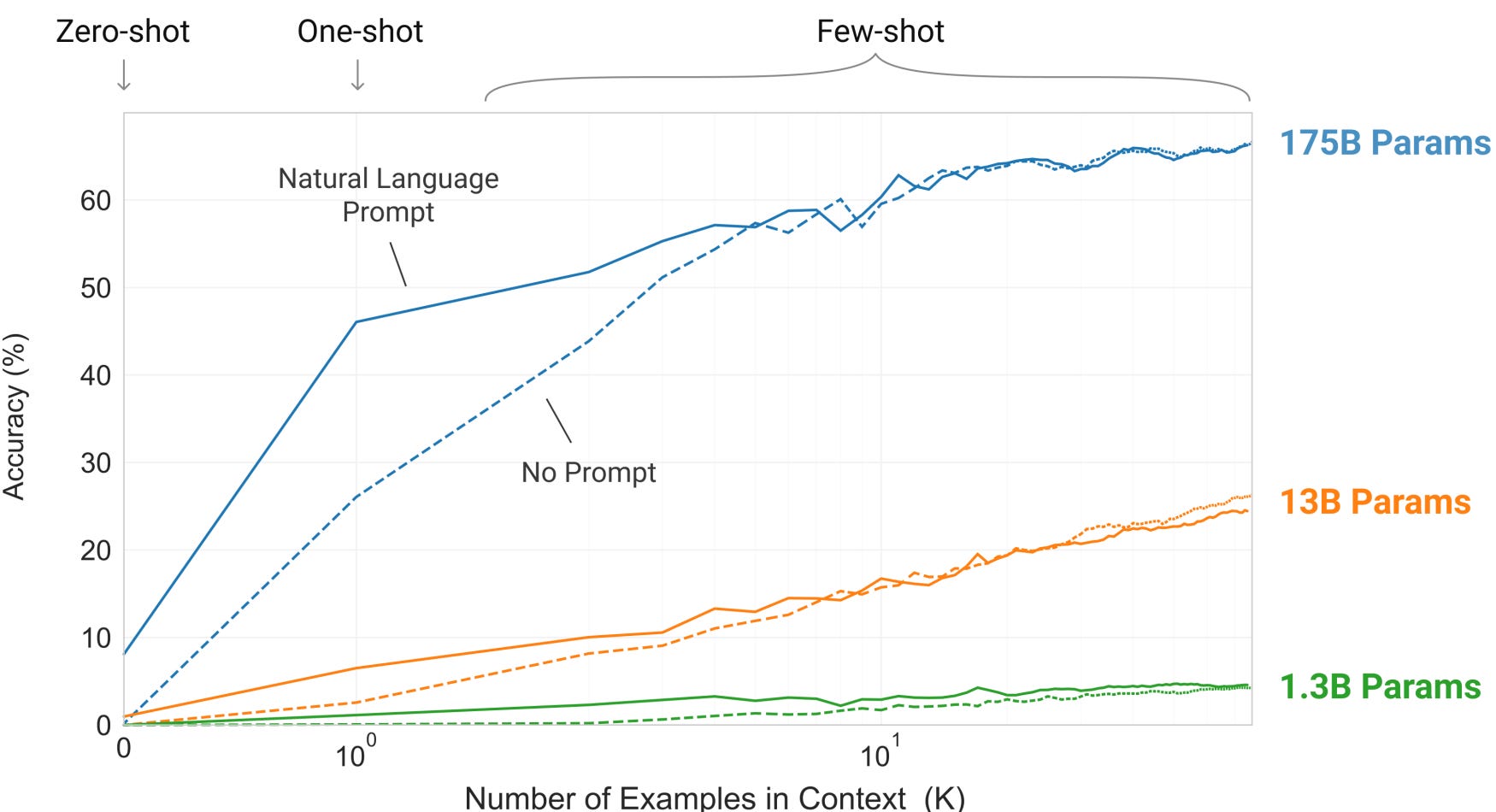
The following graph is from the GPT-3 paper. It shows that the more examples you provide, the better the accuracy of the model
Memetic Proxy
Memetic Proxy is a technique where we provide a cultural reference or an analogy for the LLM to understand what it needs to do. For example, let’s ask an LLM to explain Quantum Mechanics at the PhD level:
from langchain.prompts import PromptTemplate
template = """
System: {reference}
Provide an helpful answer to the following question
Human: {question}
AI:"""
prompt = PromptTemplate.from_template(template)
chain = LLMChain(
llm=chat_model,
prompt=prompt,
verbose=True
)
high_level = "Imagine you are a Professor teaching at the PhD level."
lower_level = "Imagine you are a Kindergarten teacher."
question = "What is Quantum Mechanics"
chain.run({
'question': question,
'reference': high_level
})
Now let’s ask the LLM to explain quantum mechanics at the Kindergarten level:
chain.run({
'question': question,
'reference': lower_level
})
Chain of Thought
Chain of Thought is a few-shot technique where we force the LLM to provide a rationale for its answer:

I found a dataset on Kaggle with Chain of Thought rationales:

I use this dataset to create Chain of Thought examples for a few-shot prompt. I load it as a Pandas data frame
import pandas as pd
file_path = ...
cot_df = pd.read_csv(file_path)
cot_df
This is a dataset of arithmetic questions. Let’s look at one example:
list(cot_df.T.to_dict().values())[0]
Let’s build that Chain of Thought prompt with 10 examples from that dataset
import random
from langchain.prompts import (
FewShotPromptTemplate,
PromptTemplate
)
examples = random.sample(list(cot_df.T.to_dict().values()), 10)
template = """
Question: {Question}
Rationale: {Rationale}
Response: {Response}
"""
example_prompt = PromptTemplate(
input_variables=["Question", "Rationale", "Response"],
template=template
)
system_prompt = """
You are provided with an arithmetic question.
Your task is to compute the solution using the given arithmetic operations.
The only arithmetic operators needed to answer the questions are'+'(addition) and'-'(subtraction).
The answer should be correct to one decimal place.
"""
COT_prompt = FewShotPromptTemplate(
prefix=system_prompt,
example_prompt=example_prompt,
examples=examples,
suffix="Question: {input}",
input_variables=['input']
)
print(COT_prompt.format(input='[EXAMPLE QUESTION]'))You are provided with an arithmetic question.
Your task is to compute the solution using the given arithmetic operations.
The only arithmetic operators needed to answer the questions are'+'(addition) and'-'(subtraction).
The answer should be correct to one decimal place.
Question: At a pie-eating contest, Erik got through 0.63 piebefore time was called ; Frank finished just 0.33 pie. How much more pie did Erik eat than Frank?
Rationale: At a pie-eating contest, Erik got through 0.63 piebefore time was called ; Frank finished just 0.33 pie. How much more pie did Erik eat than Frank?\n0.63 - 0.33 = 0.3
<p>
</details>
Response: 0.3
Question: A chef bought 0.12 kilograms of almonds and 0.38 kilograms of pecans. How many kilograms of nuts did the chef buy in all?
Rationale: The chef bought 0.12 kilograms of almonds and 0.38 kilograms of pecans, so in total they bought 0.12 + 0.38 = 0.50 kilograms of nuts.
Response: 0.5
Question: There are 42 walnut trees and 12 orange trees currently in the park.Park workers had to cut down 13 walnut trees that were damaged.How many walnut trees will be in the park when the workers arefinished?
Rationale: There are 42 walnut trees and 12 orange trees currently in the park.Park workers had to cut down 13 walnut trees that were damaged.How many walnut trees will be in the park when the workers arefinished?
Answer: 29.0
Rationale: By subtracting 13 from 42, we get 29
Response: 29.0
Question: Carefully following a recipe, Kenny used exactly 0.16 cup of oil and 1.14 cups ofwater. How many cups of liquid did Kenny use in all?
Rationale: Kenny used 0.16 cups of oil and 1.14 cups of water, so in total he used 0.16 + 1.14 = 1.3 cups of liquid.""
Response: 1.3
Question: Sally grew 6 carrots. Fred grew 4 carrots. How many carrots did theygrow in all?
Rationale: (Total) = 6 + 4 = 10.0
Response: 10.0
Question: Joan has 40 blue balloons Melanie has 41 blue balloons. How manyblue balloons do they have in total?
Rationale: Joan has 40 blue balloons Melanie has 41 blue balloons. The total number of blue balloons they have is 40+41 = 81. So the answer is 81.0
Response: 81.0
Question: Hoping to be named Salesperson of the Month, Rosa called thenames from 10.2 pages of the phone book last week. This week, shecalled the people listed on another 8.6 pages of the same phone book. How many pages worth of people did Rosa call in all?
Rationale: 10.2 + 8.6 = 18.8
Response: 18.8
Question: Melanie bought a Batman game for $6.97, a strategy game for $7.90, and a Superman game for $7.73. Melanie already owns 4 games.How much did Melanie spend on video games?
Rationale: Melanie bought 3 games, which cost $6.97, $7.90, and $7.73 respectively. Her total bill was: 6.97 + 7.90+ 7.73 = 22.60
Response: 22.6
Question: While making pastries, a bakery used 0.2 bag of wheat flour and 0.1 bag of white flour. How many bags of flour did the bakery use in all?
Rationale: 0.2 + 0.1 = 0.3
Response: 0.3
Question: Brennan had 0.25 grams of pepper. Then he used 0.15 grams of thepepper to make some scrambled eggs. How much pepper doesBrennan have?
Rationale: Brennan begins with 0.25 grams of pepper and uses 0.15 grams to make some scrambled eggs, so the amount of pepper that he has left is 0.25 - 0.15 = 0.1 grams.
Response: 0.1
Question: [EXAMPLE QUESTION]
Let’s now feed this prompt to an LLM
chain = LLMChain(
llm=chat_model,
prompt=COT_prompt,
verbose=True
)
question = """
Mandy made an apple pie. She used 0.6 tablespoon of cinnamon and 0.5 tablespoon of nutmeg.
How much more cinnamon than nutmeg did Mandy use?
"""
chain.run(question)

Self-consistency
Very often the model gives different responses to the same question. With self-consistency, we run multiple times a Chain of Thought prompt with the same question and choose the answer that comes up most often

For example in LangChain:
chat_model = ChatOpenAI(temperature=0.7)
cot_chain = LLMChain(
llm=chat_model,
prompt=COT_prompt,
verbose=True
)
template = """
Using the following answers, return the answer that comes up more often
{answers}
ANSWER:"""
consistency_prompt = PromptTemplate.from_template(template)
consistency_chain = LLMChain(
llm=chat_model,
prompt=consistency_prompt,
verbose=True
)
question = """
Mandy made an apple pie. She used 0.6 tablespoon of cinnamon and 0.5 tablespoon of nutmeg.
How much more cinnamon than nutmeg did Mandy use?
"""
responses = []
for i in range(10):
response = cot_chain.run(question)
responses.append(response)
answers = '\n\n'.join(responses)
consistency_chain.run(answers)

Inception
Inception is known as the zero-shot Chain of Thought

For example:
system_prompt = """
You are provided with an arithmetic question.
Your task is to compute the solution using the given arithmetic operations.
The only arithmetic operators needed to answer the questions are'+'(addition) and'-'(subtraction).
The answer should be correct to one decimal place.
"""
template = """
{input}
Let's think about it step by step:
"""
prompt = PromptTemplate.from_template(system_prompt + template)
chain = LLMChain(
llm=chat_model,
prompt=prompt,
verbose=True
)
question = """
Mandy made an apple pie. She used 0.6 tablespoon of cinnamon and 0.5 tablespoon of nutmeg.
How much more cinnamon than nutmeg did Mandy use?
"""
chain.run(question)
Self-Ask
Self-ask is a similar technique to Chain of Thought, but instead, we request intermediate questions and answers for the LLM to follow a logical path to get the answer
Self-ask is well adapted to answer questions with the help of a search engine

For example, let’s use the Google Search API with SerpAPI. Make sure to get your API key by signing up. We need to install the google-search-results Python package
pip install google-search-resultsSet up your API key as an environment variable:
import os
os.environ['SERPAPI_API_KEY'] = ...Let’s load an agent using a self-ask prompt for search with search engines
from langchain.agents import (
initialize_agent,
AgentType,
load_tools
)
tools = load_tools(["serpapi"])
tools[0].name = 'Intermediate Answer'
self_ask_with_search = initialize_agent(
tools=tools,
llm=chat_model,
agent=AgentType.SELF_ASK_WITH_SEARCH,
verbose=True
)
print(self_ask_with_search.agent.llm_chain.prompt.template)Question: Who lived longer, Muhammad Ali or Alan Turing?
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
Question: When was the founder of craigslist born?
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
Question: Who was the maternal grandfather of George Washington?
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
Question: Are both the directors of Jaws and Casino Royale from the same country?
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate answer: New Zealand.
So the final answer is: No
Question: {input}
Are followup questions needed here:{agent_scratchpad}
Let’s run this agent with a question:
from langchain.callbacks import StdOutCallbackHandler
handler = StdOutCallbackHandler()
question = "What is the hometown of the reigning men's U.S. Open champion?"
self_ask_with_search.run(
question,
callbacks=[handler]
)After the first chain finished, the LLM answered the first intermediate question and got the first intermediate answer from the search engine

After a second iteration of the chain, it asks the second intermediate question and gets the resulting answer

After this, it is convinced it knows the answer

ReAct
ReAct (Resonning and Acting) is a technique to push the LLM to make an action after thinking about it. This is very well adapted to augment LLMs with tools

Let’s show an example with a search engine and a calculator LLM
tools = load_tools(["serpapi", "llm-math"], llm=chat_model)
agent = initialize_agent(
tools=tools,
llm=chat_model,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
handler = StdOutCallbackHandler()
question = """
Who is Leo DiCaprio's girlfriend?
What is her current age raised to the 0.43 power?
"""
agent.run(
question,
callbacks=[handler]
)After the question, the LLM establishes a thought and then chooses an Action with an Action Input. Based on that it produces an Observation

In the second iteration, it utilized what it learned in the previous step to formulate a different thought and a different resulting Action. It then produces a different observation

It then iterates through this process until it is convinced it knows the answer

Here is the prompt that led to the LLM understanding of how to use tools and how to utilize the results of the previous steps
print(agent.agent.llm_chain.prompt.template) Answer the following questions as best you can. You have access to the following tools:
Search: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.
Calculator: Useful for when you need to answer questions about math.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [Search, Calculator]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
Plan and execute
Plan and execute is a technique where a question is broken down into the steps needed to solve the problem with each of the steps being solved by a ReAct chain. After each step is solved, the result is fed as an argument in the ReAct chain of the next step:

To see an example in LangChain, we need to install an experimental package where the plan and execute agent is currently in beta
pip install langchain-experimentalWe can then create the agent
from langchain_experimental.plan_and_execute import (
PlanAndExecute,
load_agent_executor,
load_chat_planner
)
chat_model = ChatOpenAI()
tools = load_tools(["serpapi", "llm-math"], llm=chat_model)
planner = load_chat_planner(chat_model)
executor = load_agent_executor(
chat_model,
tools,
verbose=True
)
agent = PlanAndExecute(
planner=planner,
executor=executor,
verbose=True
)Let’s look at how the planner is going to devise a plan
print(planner.llm_chain.prompt.format(input='Some input'))System: Let's first understand the problem and devise a plan to solve the problem. Please output the plan starting with the header 'Plan:' and then followed by a numbered list of steps. Please make the plan the minimum number of steps required to accurately complete the task. If the task is a question, the final step should almost always be 'Given the above steps taken, please respond to the users original question'. At the end of your plan, say '<END_OF_PLAN>'
Human: Some input
Let’s look at how the executors are going to follow a ReAct plan
print(executor.chain.agent.llm_chain.prompt.format(
previous_steps='[previous_steps]',
current_step='[current_step]',
agent_scratchpad='[agent_scratchpad]'
)) System: Respond to the human as helpfully and accurately as possible. You have access to the following tools:
Search: A search engine. Useful for when you need to answer questions about current events. Input should be a search query., args: {{'tool_input': {{'type': 'string'}}}}
Calculator: Useful for when you need to answer questions about math., args: {{'tool_input': {{'type': 'string'}}}}
Use a json blob to specify a tool by providing an action key (tool name) and an action_input key (tool input).
Valid "action" values: "Final Answer" or Search, Calculator
Provide only ONE action per $JSON_BLOB, as shown:
```
{
"action": $TOOL_NAME,
"action_input": $INPUT
}
```
Follow this format:
Question: input question to answer
Thought: consider previous and subsequent steps
Action:
```
$JSON_BLOB
```
Observation: action result
... (repeat Thought/Action/Observation N times)
Thought: I know what to respond
Action:
```
{
"action": "Final Answer",
"action_input": "Final response to human"
}
```
Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:.
Thought:
Human: Previous steps: [previous_steps]
Current objective: [current_step]
[agent_scratchpad]
Let’s run this agent
question ="""
Who is Leo DiCaprio's girlfriend?
What is her current age raised to the 0.43 power?
"""
agent.run(question)We first establish the plan to solve the problem:

It then starts solving the first step
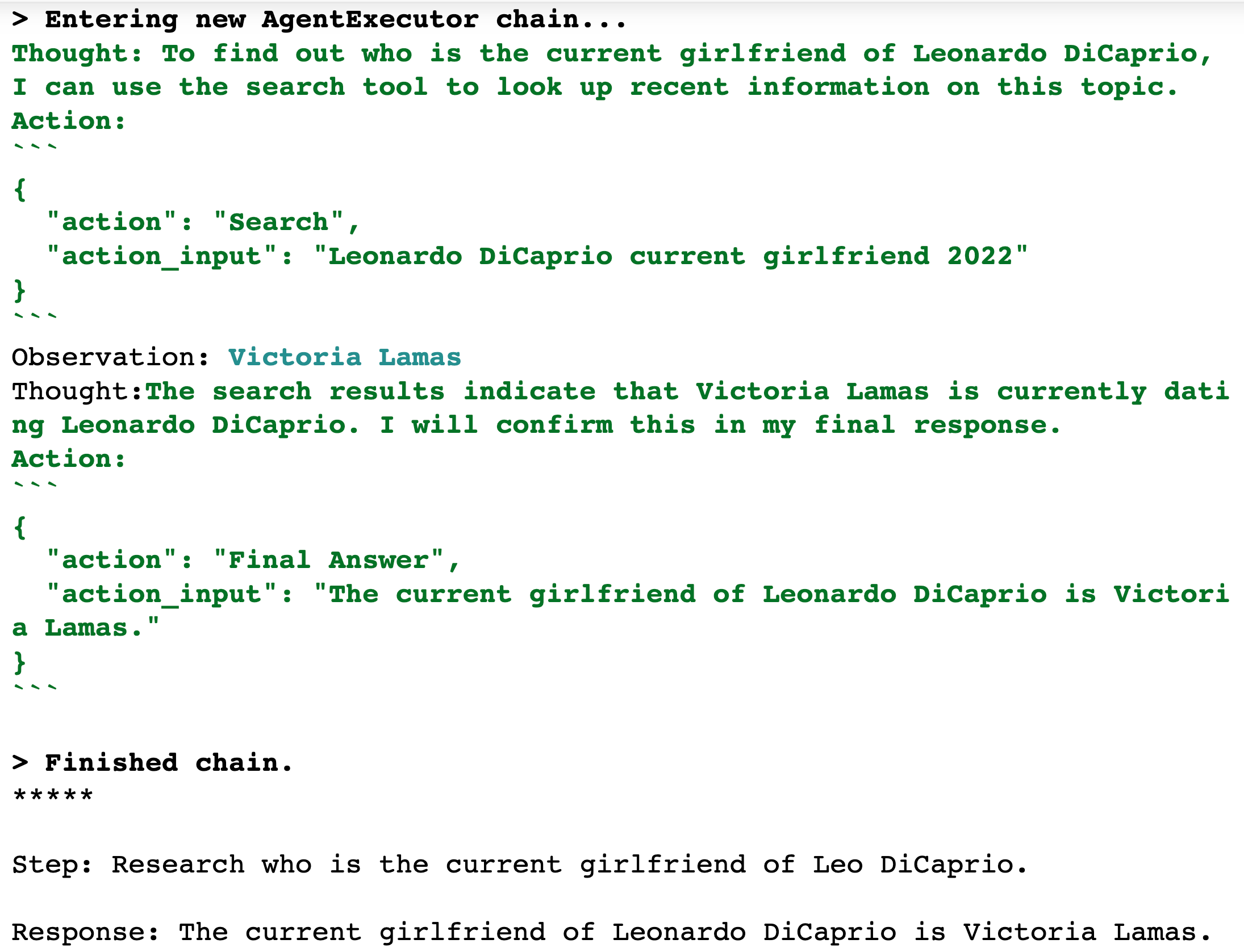
It then enters the second step

After going through all the steps, the LLM comes up with an answer

