


Black Friday offers
That has been an exciting year for the AiEdge Newsletter! We launched in January, and we have now reached 50,000 readers all over the world. We even started a podcast! To thank you, here is a 30% coupon for yearly subscriptions available until the end of the weekend:
Additionally, I am making my LangChain course 50% off for the next 5 days when applying the following coupon:
Course Link: Introduction to LangChain
Coupon Code: BLACKFRIDAY
This post is the first lecture of the course, so you can see what it is about. Here is the curriculum:
LangChain Basics
Loading and Summarizing Data
Prompt Engineering Fundamentals
Vector Database Basics
Retrieval Augmented Generation
RAG Optimization and Multimodal RAG
Augmenting LLMs with a Graph Database
Augmenting LLMs with tools
How to Build a Smart Voice Assistant
How to Automate Writing Novels
How to Automate Writing Software
What is LangChain
When you have a typical large language model, the way to interact with it is to ask a question and you get an answer. But it's pretty isolated from the rest of the world. You cannot really do much more than that.

So, if you want to build applications, you may want to connect your large language model to data. You may want to give it access to tools. You may want to give it memory access. And you may want to automate the process of prompt engineering. LangChain allows you to connect all those different aspects to build software applications.

There are really 2 sides to Prompt Engineering: the one pushed by the non-technical influencers (e.g., "The top 5 prompts to improve your productivity!") and the one that actually allows you to build applications. To build applications, you dynamically need to chain multiple prompts while controlling the output of each to obtain somewhat deterministic outcomes. I have to say, I have seen so many of those prompt engineering guides by influencers that I have wrongly ignored the complexity of going beyond the basic ChatGPT UI interface.

Let's say you want to build your company's chatbot! First, you need to make your text data discoverable by the LLM. The typical way to do that is to index your data into a vector database. You'll need to partition your data into chunks, encode those chunks into embeddings using an LLM, and index those chunks using those embeddings. When you have a question, you can encode the question into another embedding and search in that database for the corresponding piece of data with the highest cosine similarity metric. By feeding that piece of data within a prompt, the LLM can more confidently recover the right answer.
You might need to insert users' questions within a prompt template with additional examples to provide the right context for the LLM, or you might need to augment it by asking the LLM to establish a plan of action to respond to the question accurately. Often, chaining multiple (prompt, answer) pairs will be necessary to arrive at the desired outcome.
There are multiple tools that an LLM can use: Google Search, Python REPL, GraphQL, Wikipedia… We need to prompt the LLM with a set of tools it can use and how to utilize the result to answer the question if it decides to use one of them. Additionally, we may want to keep track of the history for the LLM to remember what was previously discussed. This needs to be coordinated with the data search in the vector database that may happen in parallel.
When we take into account the initial question, prompt templates, prompt augmentation, data search, tools, plan of action, and memory, we start to understand the difficulty in juggling all those items when we need to construct the right prompts for meaningful results. LangChain is most likely one of the most powerful LLMops tools today! It provides an abstracted interface to chain all those items together in a simple manner to build applications. It has an API connection to ~40 of the public LLMs, Chat, and embedding models. It integrates with more than 30 different tools and 20 different vector databases.
LangChain basics
So let's demonstrate some of LangChain's capabilities. Let's pip install it along the OpenAI python package:
pip install langchain openaiWe set up the OpenAI API key as part of the environment variables
import os
os.environ['OPENAI_API_KEY'] = ...LLMs
We can import the OpenAI’s GPT-3 model and ask it questions
from langchain.llms import OpenAI
llm = OpenAI()
llm.predict('How are you?')
> "\n\nI'm doing well, thank you. How about you?"We can also import the underlying model behind ChatGPT
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI()
chat_model.predict('How are you?')
> "As an AI, I don't have feelings, but I'm here to help you with any questions or tasks you have. How can I assist you today?"The problem with raw LLMs is that they don’t remember the history of the conversations
chat_model.predict('What was my previous question?')
> "I'm sorry, but I am an AI language model and I don't have access to your previous questions."Chains
We can create a chain that is going to help us augment the LLM
from langchain.chains import ConversationChain
chain = ConversationChain(
llm=chat_model,
verbose=True
)
chain.run('How are you today?')
As part of the prompt, we see now that there is a bit more to my simple prompt. We have a system prompt, the history of the conversation, and the human’s question. The system prompt allows us to give the LLM more context on what needs to be done. Let’s see if it remembers:
chain.run('What was my previous question?')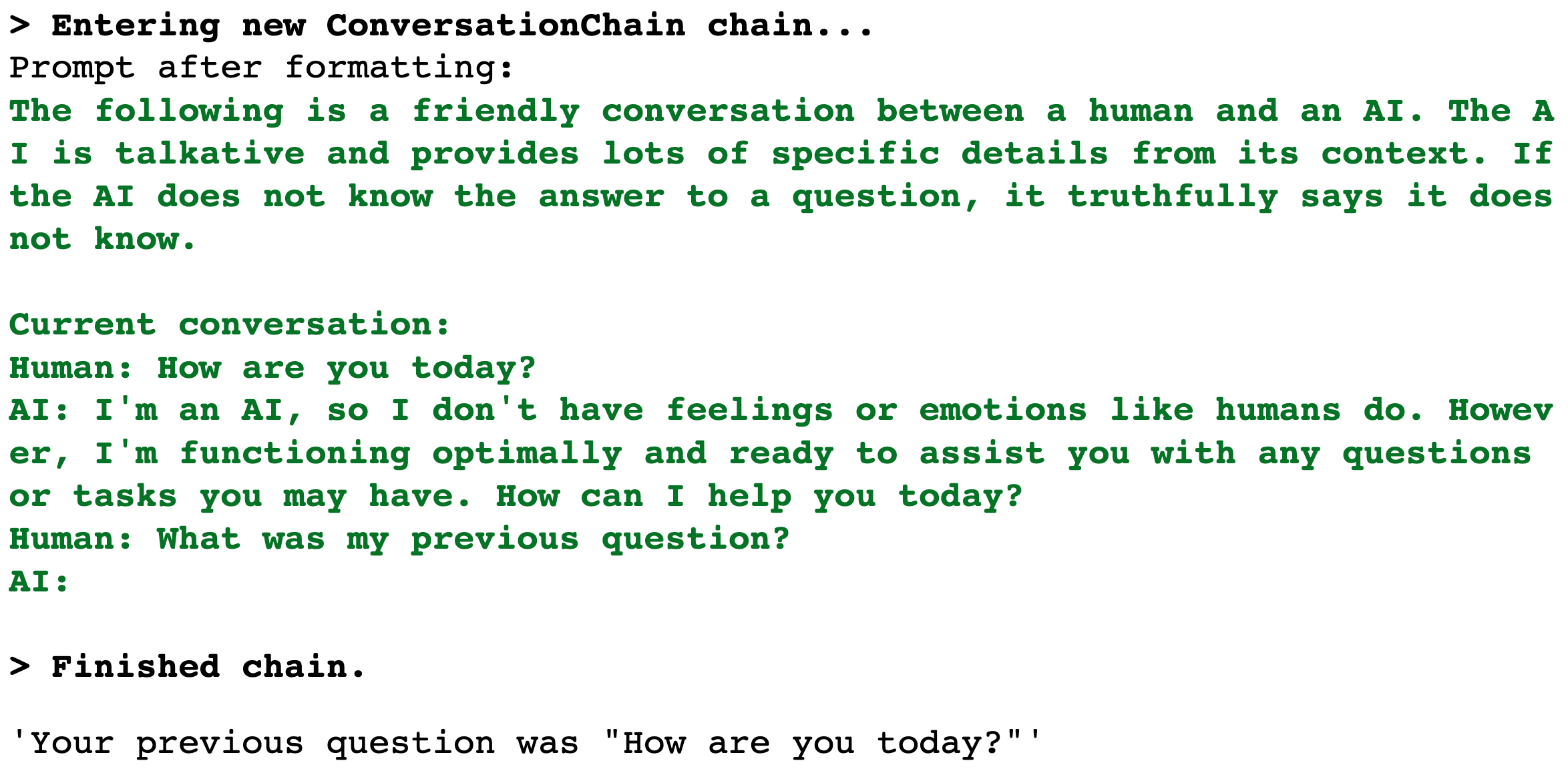
Prompt templates
With LangChain, we can automate a lot of the prompt engineering, and for that, we can use prompt templates. Let’s create a prompt template
from langchain.prompts import PromptTemplate
template = """
Return all the subcategories of the following category
{category}
"""
prompt = PromptTemplate(
input_variables=['category'],
template=template
)‘Category’ is an input variable that will be used once we run the chain. Let’s input it into a chain. We use LLMChain, which is the simplest chain we can use
from langchain.chains import LLMChain
chain = LLMChain(
llm=chat_model,
prompt=prompt,
verbose=True
)
chain.run('Machine Learning')
We can also break down the prompts into the system and human prompts. This is helpful when we build chatbots
from langchain.prompts import (
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
ChatPromptTemplate
)
system_template = """
You are a helpful assistant who generate comma separated lists.
A user will only pass a category and you should generate subcategories of that category in a comma separated list.
ONLY return comma separated and nothing more!
"""
human_template = '{category}'
system_message = SystemMessagePromptTemplate.from_template(
system_template
)
human_message = HumanMessagePromptTemplate.from_template(
human_template
)Ans we can combine the 2 prompts into one:
prompt = ChatPromptTemplate.from_messages([
sytem_message, human_message
])
chain = LLMChain(
llm=chat_model,
prompt=prompt,
verbose=True
)
chain.run('Machine Learning')
This gives us more control of the LLM’s output, but we can go further by using an output parser.
Output parser
Let’s overwrite the base output parser and generate Python lists from the LLM’s response:
from langchain.schema import BaseOutputParser
class CommaSeparatedParser(BaseOutputParser):
def parse(self, text):
output = text.strip().split(',')
output = [o.strip() for o in output]
return output
chain = LLMChain(
llm=chat_model,
prompt=prompt,
output_parser=CommaSeparatedParser(),
verbose=True
)
chain.run('Machine Learning')
We can also feed the chain with multiple inputs:
input_list = [
{'category': 'food'},
{'category': 'country'},
{'category': 'colors'}
]
response = chain.apply(input_list)
response[2]['text']
Simple Sequence
We can also compose chains. Here we are creating a pipeline of chains, where the output of one chain is used as input in the next one. We create 2 chains: a title chain and a synopsis to automate the process of writing a play. First, we have a title chain:
title_template = """
You are a writer. Given a subject,
your job is to return a fun title for a play.
Subject: {subject}
Title:"""
title_chain = LLMChain.from_string(
llm=chat_model,
template=title_template
)
title_chain.run('Machine Learning')
> '"The Algorithmic Adventure: A Machine Learning Marvel"'And a synopsis chain:
synopsis_template = """
You are a writer.
Given a title, write a synopsis for a play.
Title: {title}
Synopsis:"""
synopsis_chain = LLMChain.from_string(
llm=chat_model,
template=synopsis_template
)
title = "The Algorithmic Adventure: A Machine Learning Marvel"
synopsis_chain.run(title)
Let’s now combine those 2 chains by passing them as a list to the simple sequential chain:
from langchain.chains import SimpleSequentialChain
chain = SimpleSequentialChain(
chains=[title_chain, synopsis_chain],
verbose=True
)
chain.run('Machine Learning')

Potentially an interesting play! This concludes our introduction to LangChain basics. I hope you had some fun!
