

Last Week to Register: Build Production-Ready Agentic-RAG Applications From Scratch Course!
Project-Based Course

This is the last week to register for the Build Production-Ready Agentic-RAG Applications From Scratch course! This is a fully hands-on course where we are going to implement step-by-step from scratch a production-ready Agentic-RAG application with LangGraph, FastAPI, and React!
What we are going to build
We are going to build a fun web application where we can demonstrate how to orchestrate a robust RAG application using LangGraph, FastAPI, and React. Here is what we are going to build:
A user can pass a GitHub repository URL
The files of the related repository are scraped and indexed in a vector database
Now the code is available for the user to ask questions about.
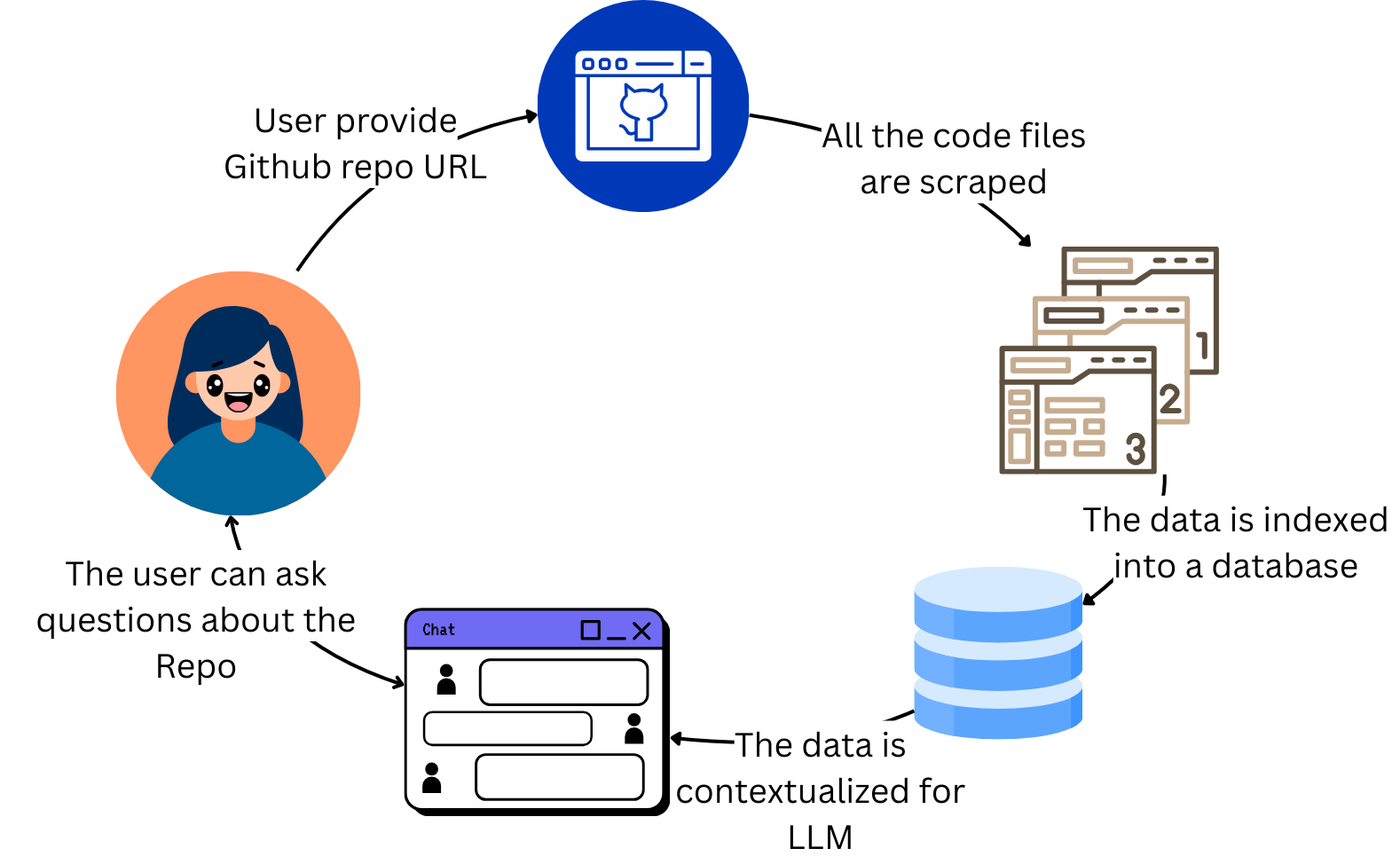
On the frontend, we will need two main functionalities:
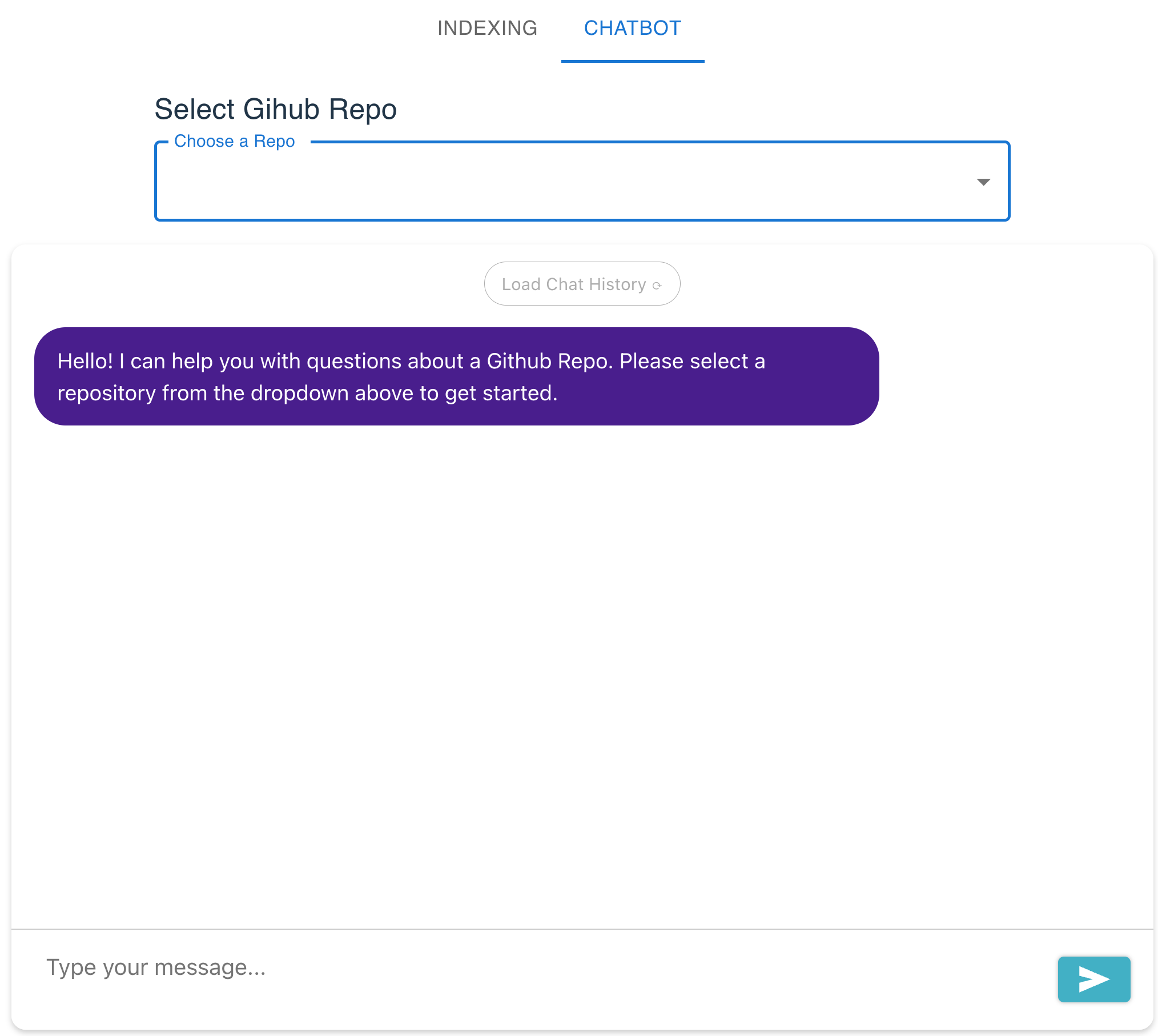
A page where we can input the repository URL and start the crawling and indexing processes:

And a chatbot interface to ask questions about the code in the repository:
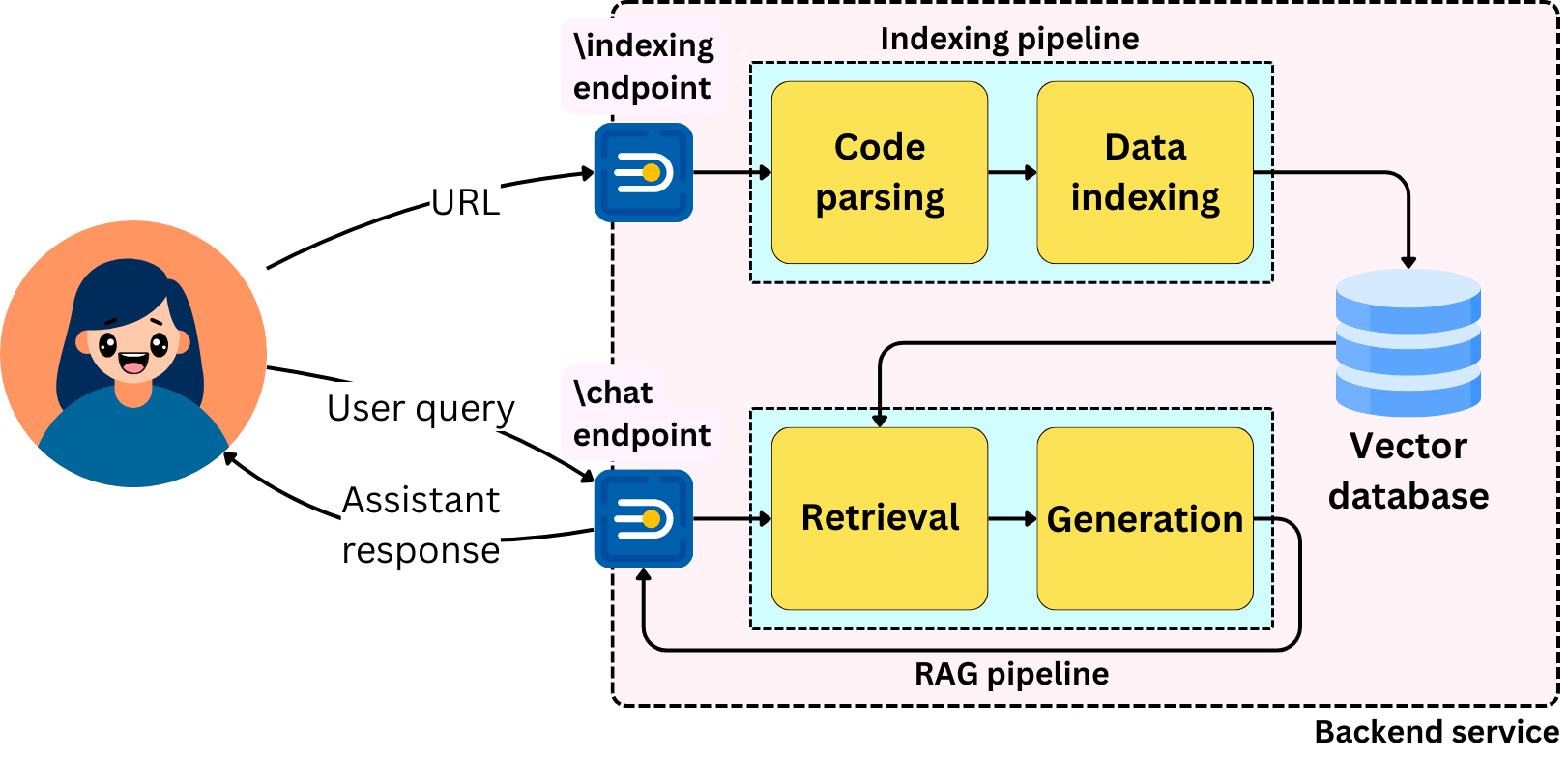
On the backend, we will need the related endpoints:
The indexing endpoint will respond to the provided GitHub repository URL and the “crawl“ action to start the crawling and indexing processes.
The chat endpoint that will respond to messages sent by the user from the chatbot interface.
We are going to use the following tools:
React for the frontend
FastAPI for the backend
LangGraph for the agentic orchestration
Pinecone for the vector database
Langsmith for observability
Deploy everything on Google Cloud!
Project-based course
We will focus on building the project from the ground up, as we would on the job. Here is how we are going to structure the project development:
Introduction
What we want to build
Setting up the environment
The RAG Application
The Data Parsing Pipeline
The Indexing Pipeline
The Basic RAG Pipeline
Adding Observability to the Pipeline with Langsmith
Going Agentic
The Backend Application
The Indexing API Endpoint
Adding Memory
Administering the Database Data
The Frontend Application
The Indexing Page
The Chatbot Page
Deploying to GCP
Each session will be a live, hands-on coding session where we are going to implement every component from scratch
Going Agentic
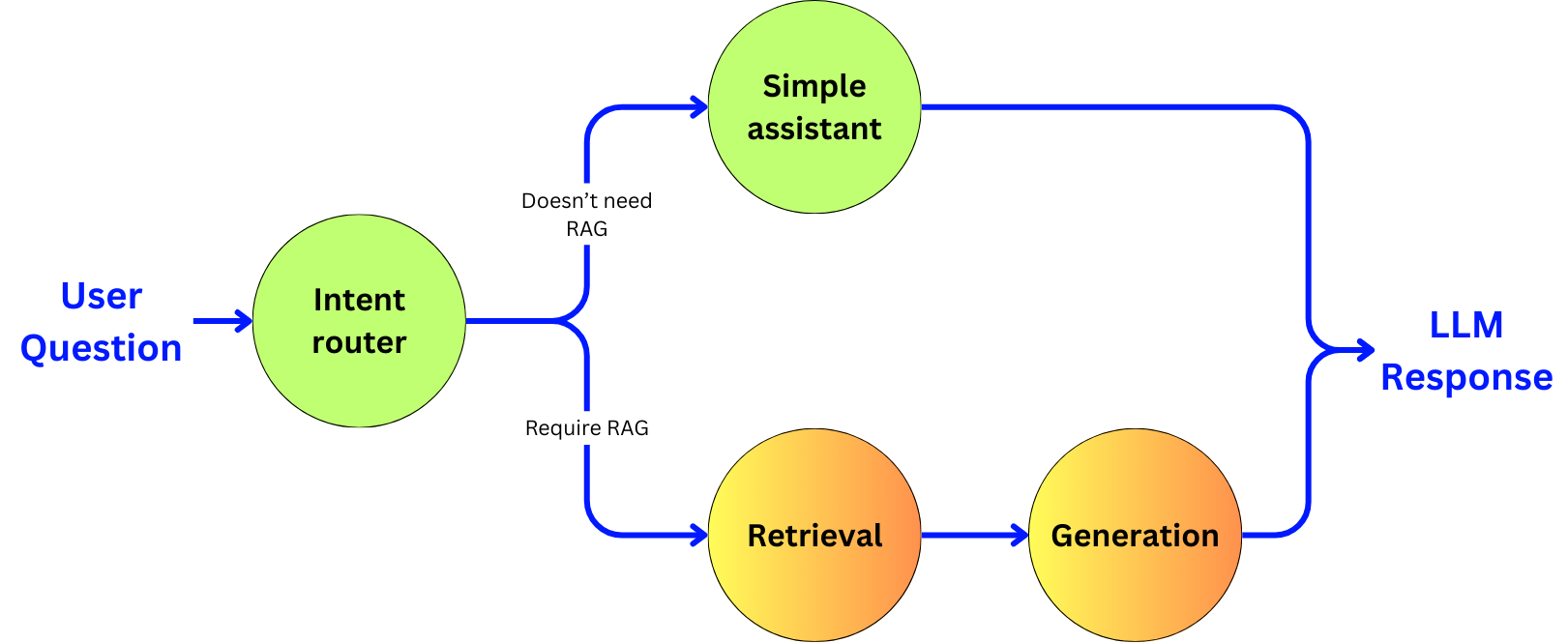
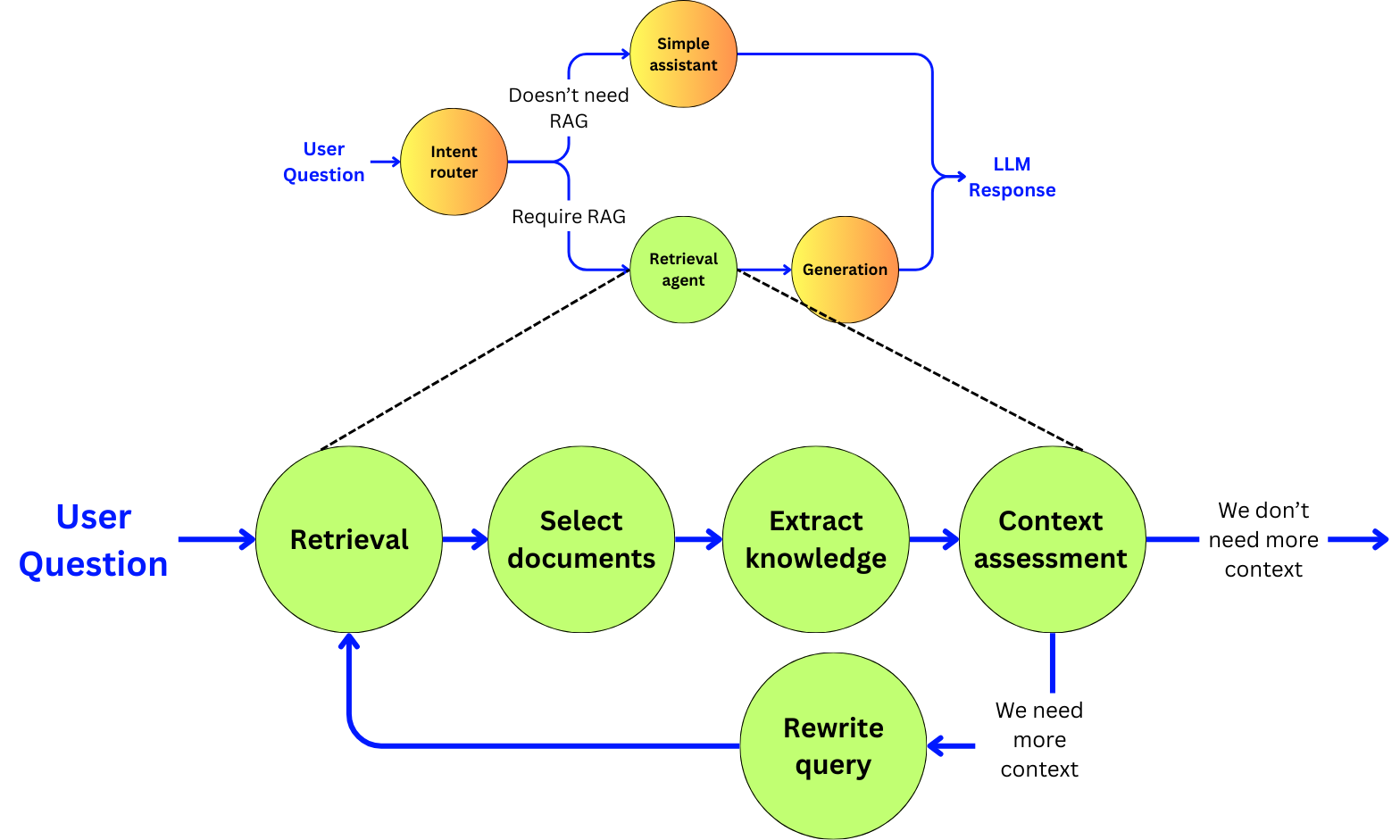
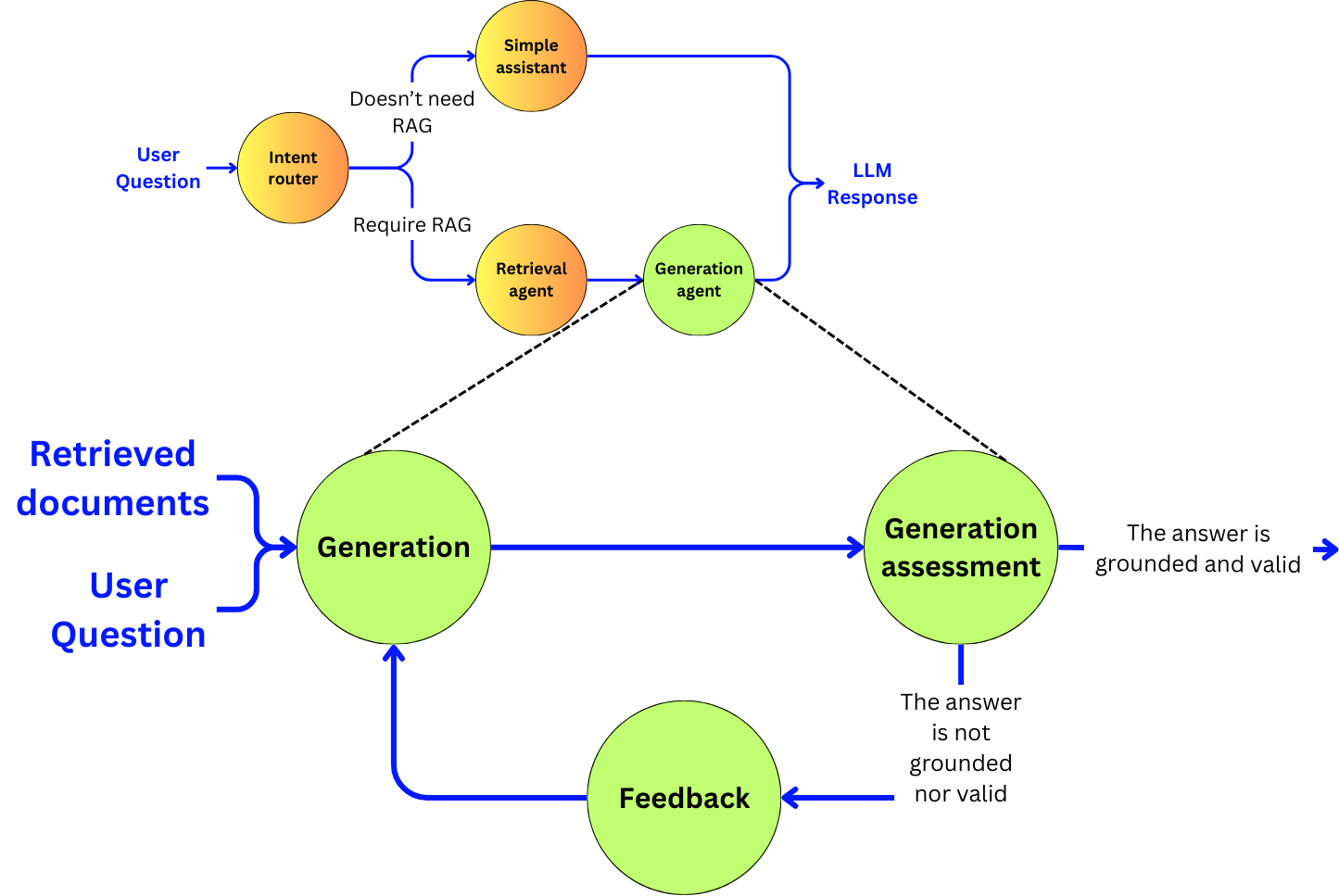
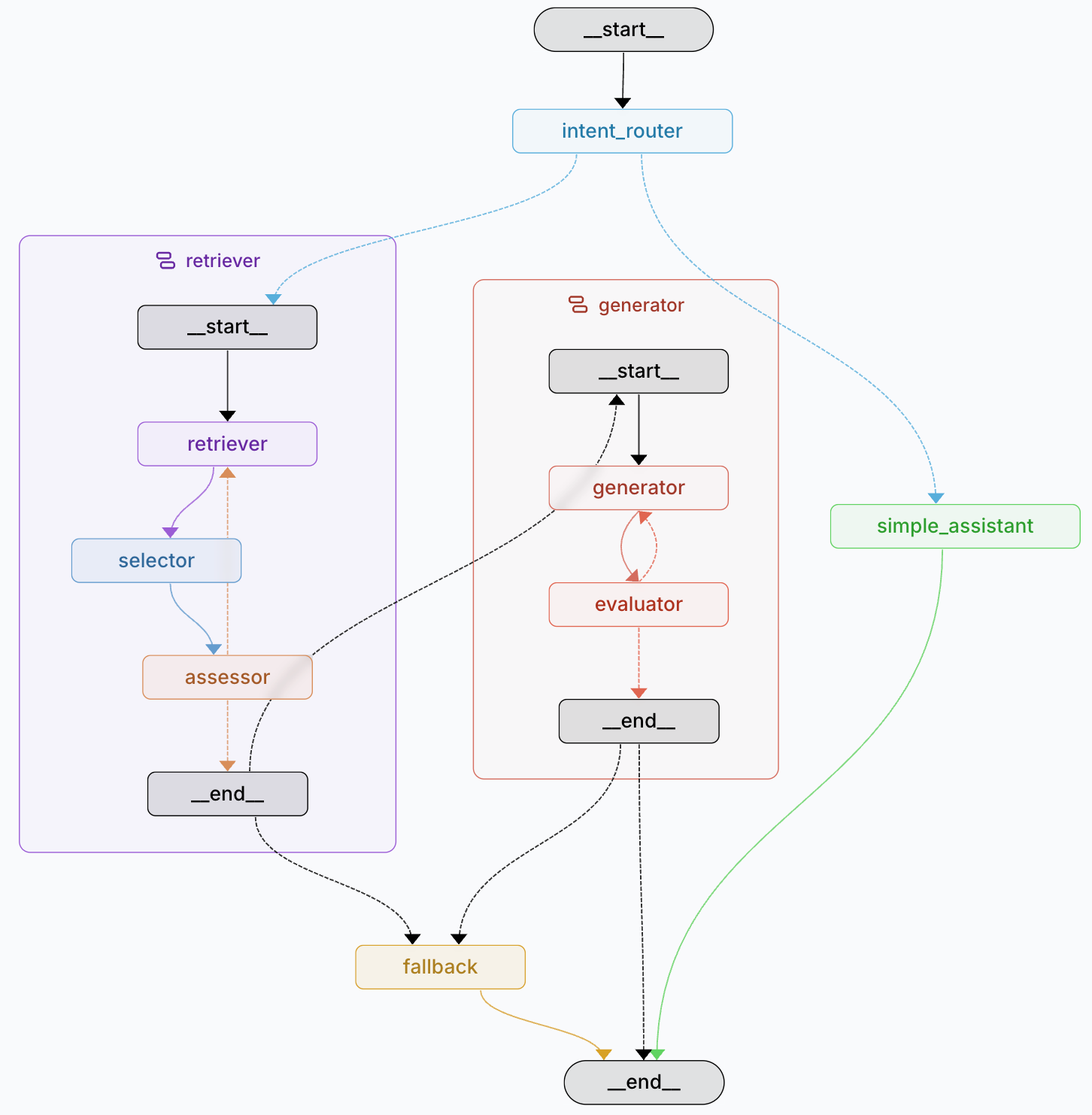
“Agentic” means that we are going to use an LLM as a decision engine to enhance the quality of our pipeline. We will focus on improving the accuracy of the pipeline at the cost of latency and cost, and discuss the opportunities to reduce those induced negative points with small language models and fine-tuning. In the RAG pipeline, we are going to build a subagent for each of the main components:
Intent router: the entry point of the pipeline that will decide if a RAG pipeline is required.
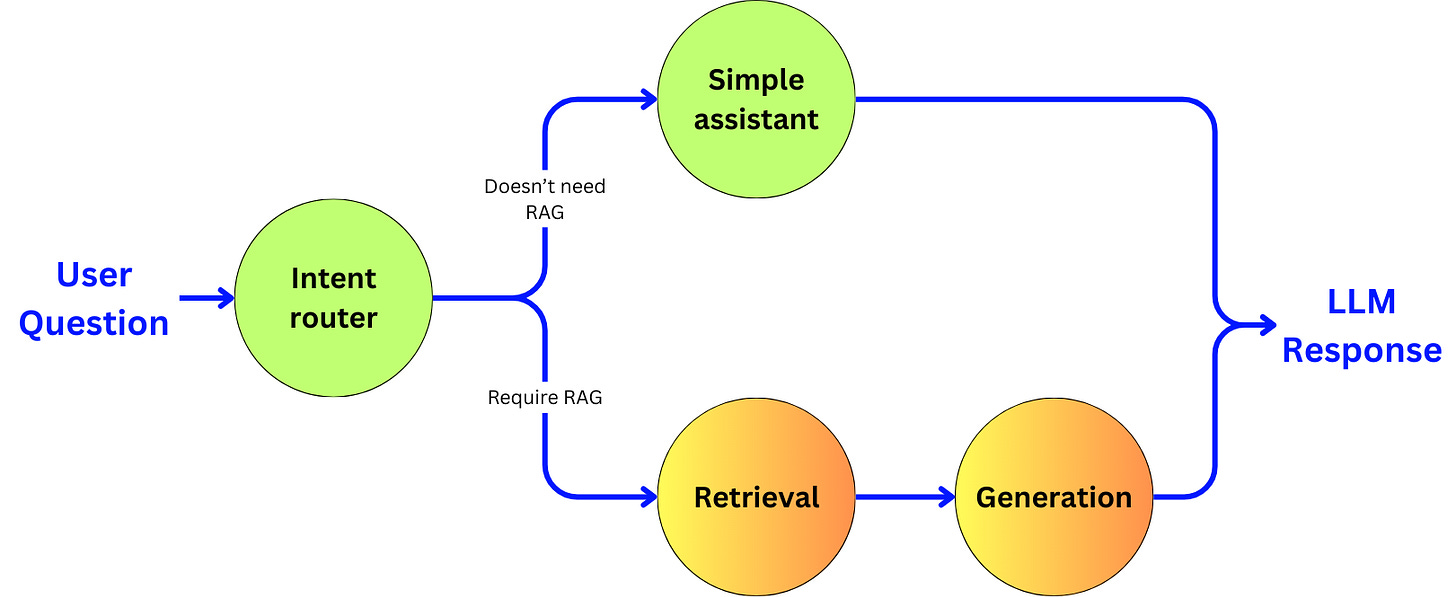
The retriever: The sub-agent that will extract the right data
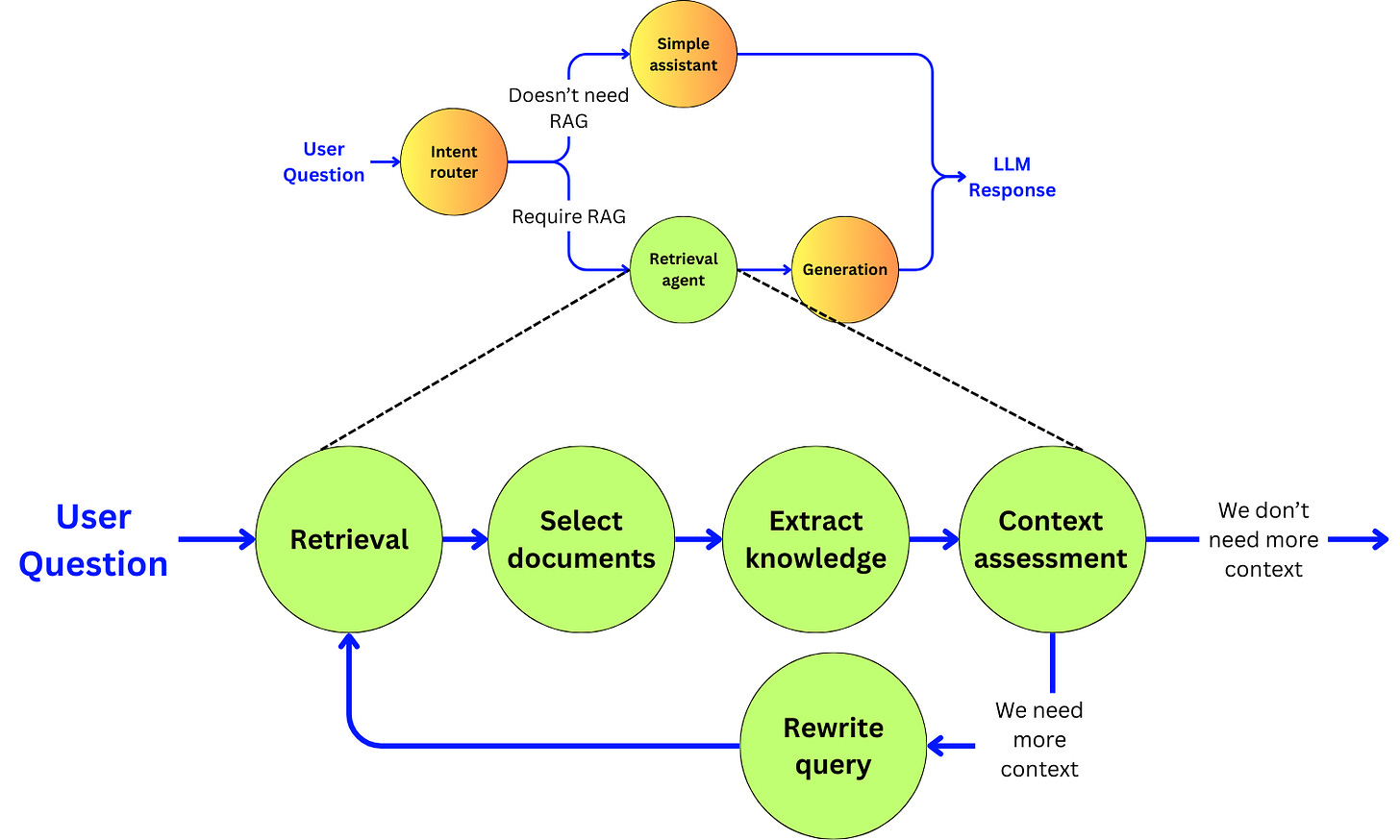
The generator: The sub-agent that will generate the response to the user
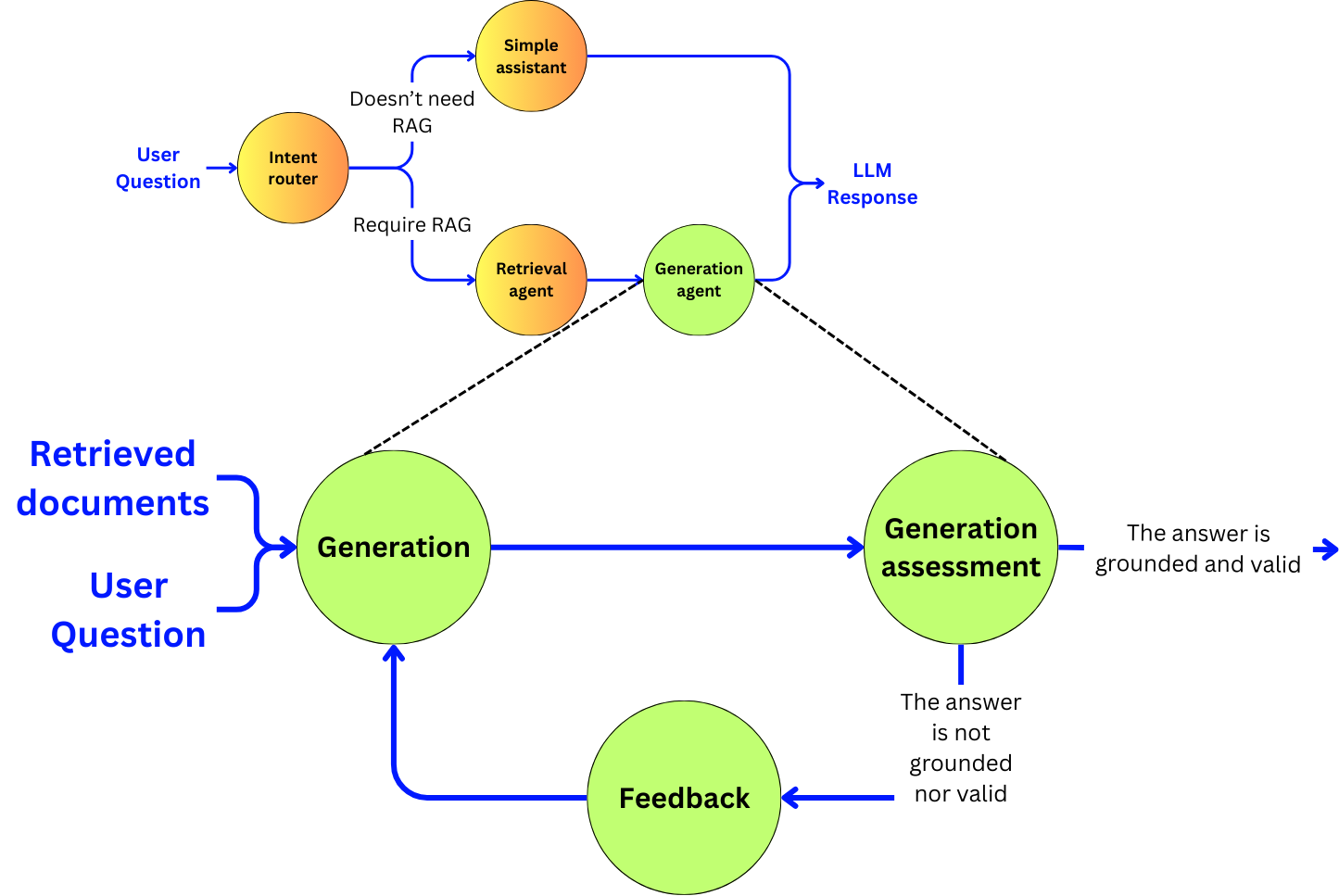
Scaling up
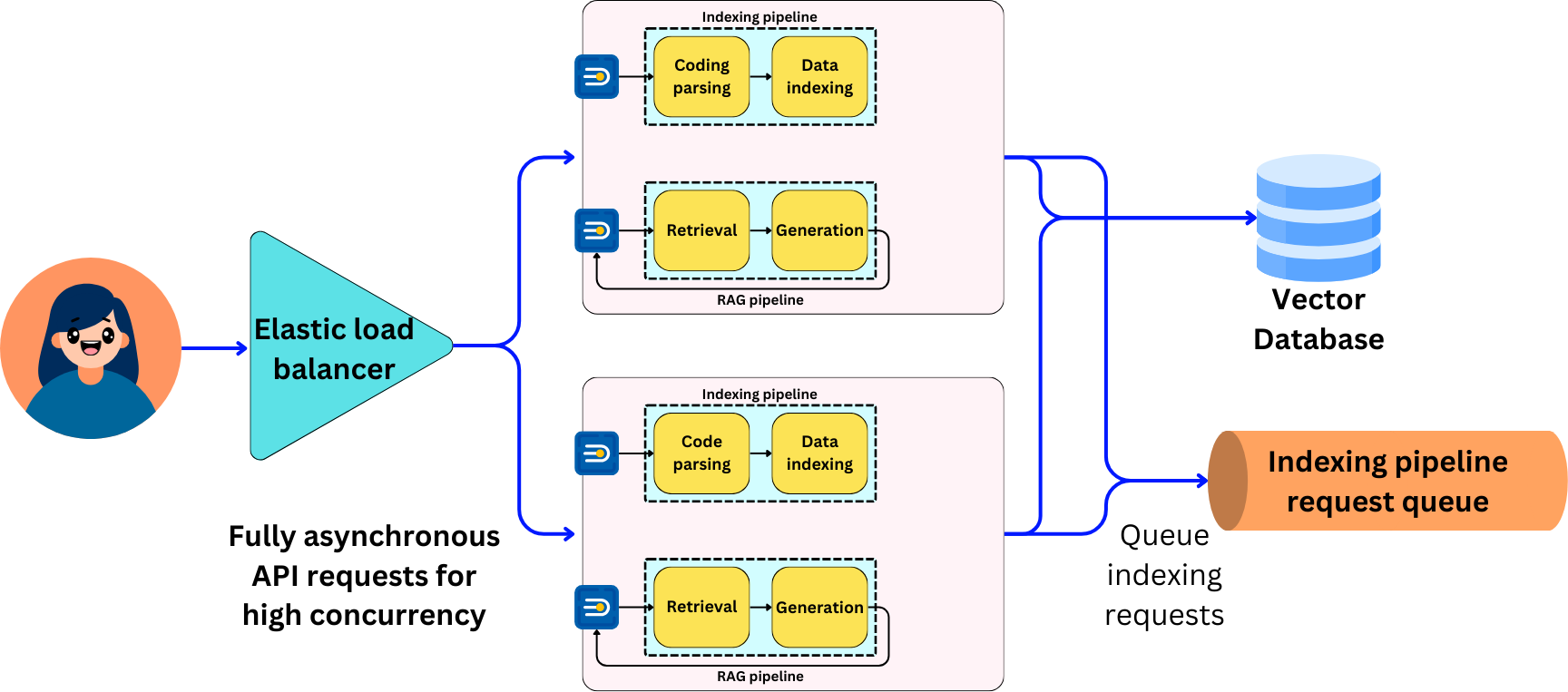
With this course, I want to focus on what we would need to do to deploy the application to 1M users. We will make sure to design every endpoint to be asynchronous, queue the indexing requests, and deploy the application with elastic load balancing to scale the application horizontally.
This is going to be a fun ride! Make sure to join us!
The Real-World AI Engineering Roadblocks You Face Today
👋 Prototype → Production Gap — Moving from a notebook demo to a secure, observable, multi-tenant service requires orchestration, evals, guardrails, and ops most teams lack.
👋 “Easy RAG” vs “Reliable RAG” — Anyone can retrieve-then-generate; making answers faithful, fresh, fast, and cost-controlled under real traffic is the hard part.
👋 Framework Overload — The ecosystem is noisy; you need clear criteria (maturity, extensibility, latency, cost) and reference patterns to choose confidently.
👋 It’s Software Engineering First — Success hinges on clean interfaces, tests, typed configs, tracing, CI/CD, and change management—not just prompts and models.
👋 From Laptop to 1M Users — Scaling demands streaming, batching, caching, autoscaling, and SLOs, or your p95 explodes and costs spiral.
How this course will help you
✅ Ship a real Agentic RAG app, not a demo — Stand up an end-to-end stack—LangGraph → FastAPI → React, that runs locally today and deploys via a clean, fork-and-ship monorepo.
✅ Make retrieval dependable, not lucky — Adopt schema-aware chunking, strong dense embeddings with sensible metadata filters, and context packing with citations so answers stay faithful, fresh, and concise.
✅ Harden agentic workflows — Design a typed LangGraph state and build nodes for rewrite → retrieve → rerank → synthesize → cite → safety-check, with retries and timeouts so plans don’t loop or stall.
✅ Scale the experience, not the headaches — Enable server-streaming in FastAPI, cap top-k, trim context budgets, and add early-exit rules; deploy with autoscaling so you can serve real traffic without infra fuss.
✅ See enough to fix things fast — Bake in structured logs (no vendor tracing), per-step timing counters, and UI breadcrumbs/citations to follow query → context → answer and spot common failure patterns quickly.
✅ Choose frameworks with confidence — Follow an opinionated reference architecture plus a simple choice rubric (maturity, extensibility, latency, cost, swap effort) so you know when to stick—and how to swap components without rewrites.
✅ Write maintainable RAG code — Use clean module boundaries (ingest / retrieve / rerank / synthesize), typed configs (Pydantic Settings), and sensible secrets/env management so your team can extend it safely.
You’ll walk away with
✨ A running Agentic RAG app (LangGraph + FastAPI + React) in a fork-and-ship monorepo.
✨ An ingestion/indexing pipeline with metadata, hybrid retrieval, and optional re-ranking.
✨ A chat UI with citations, source previews, and conversation memory that behaves.
✨ Deploy scripts and env templates to go live right after class.
✨ A framework choice memo + adapters to swap models/vector stores without starting over.
Bottom line: this isn’t a vitamin, it’s a blueprint you can put in production.
What you’ll get out of this course
Orchestrate complex RAG pipelines with LangGraph and OpenAI API: Build a typed LangGraph that routes rewrite → retrieve → rerank → synthesize → cite → self-check with retries, timeouts, early-exit rules, and real tool calls, exposed as a clean HTTP API.
Build scalable asynchronous applications with FastAPI: Ship async FastAPI endpoints, well-typed request/response models, input validation, and sensible timeouts, ready to run locally and deploy to production.
Implement chatbot interfaces with React: Create a chat UI that shows citations and source previews, lets users scope queries, preserves safe chat history, and handles transient API errors gracefully.
Mitigate hallucinations with LLM judges, structured output, and context engineering: Cut errors via schema-aware chunking, dedupe and budgeted context packing, plus lightweight LLM checks and schema-constrained outputs to verify claims and enforce citations before responding.
Design effective LLM prompts for high-level control on generation output: Write prompts that steer behavior: system prompts, task decomposition, Pydantic/JSON-schema constraints, and clear rules for tone, citations, and safe refusals.
Develop end-to-end RAG applications using the software engineering best practices: Produce a maintainable codebase: clean module boundaries (ingest/retrieve/rerank/synthesize), typed configs, secrets/env management, reproducible local dev, and deploy that mirrors local.
This is great. I’ve built 1-2 RAG agents, and this is really nice. Wish I had this before I had to experiment myself for so long :)
Great and valuable content. Is there anywhere we can re-watch this?
Thnx