

Machine Learning Fundamentals: Interview Questions
Deep Dive in Data Science Fundamentals

Today we do something a bit different! I am going over a few typical interview questions about Machine Learning fundamentals I have seen during my career. I present the questions in the first part and the solutions in the second. We cover the following subjects:
Decision trees
The K-Nearest Neighbor (K-NN) algorithm
Learning XOR with a Perceptron model
The right subset of the data
The area under the receiver operating characteristic curve
Clustering: the K-mean algorithm
Maximum likelihood estimation for linear regression
Feature selection with LASSO
The bias-variance trade off
All the solutions

This Deep Dive is part of the Data Science Fundamentals series.
By the way, if you like the following article, feel free to click the ❤️ button on this post so more people can discover it on Substack 🙏. Thank you!
Questions
Decision Trees
We have some training data here. The "classification" column is the target we are learning. "X1" and "X2" are the training data features.

Recall that entropy is the average information yielded by a random variable and is defined as follows:
Where C is the set of classes (+ and - in our case). Consider the entropy of this collection of training examples with respect to the target function "classification". We will split the data into 2 subsets according to one of the features ("True" goes left, "False" on the right). Each subset ends up in one of the children nodes of the following binary tree:
Question 1
From this data, estimate
Question 2
What feature yields a split with the most information gain from the root node to the children nodes? We define information gain as
where P(left) and P(right) are the probabilities to go left or right respectively.
Question 3
Based on question 1 and question 2, provide P1, P2, P3 and P4, the probabilities to be + in leaf node 1, 2, 3 or 4 in the following decision tree:

We use one of the variables for the first split (as given in question 2) and the other for the second split.
The k-Nearest Neighbor (k-NN) algorithm
Consider the following training data for k-NN algorithm:

When we want to classify an instance, we just need to compute the "distance" of this new instance from the instances in the training data and classify this new instance as its set of k nearest neighbors. To measure a distance, we use here the Euclidean distance.
Question 1
Let's consider this new instance: {7, 1323, NO, 1.7}. Compute the Euclidean distance of this instance from the training data instances. You can convert YES = 1, NO = 0. What class would you predict for this instance if you looked at the closest training data instance (k = 1)?
Question 2
You may have noticed that most of the distance comes from the variable X2 due to the scale on which this variable lives. For k-NN it is important to rescale the variables. Recompute the Euclidean distance but this time rescale X1, X2 and X4 (X3 is more well behaved) by their standard deviation. What class would you predict for this instance if you looked at the closest training data instance with these normalized axes?
Question 3
Let's now consider k = 3. Find the 3 nearest neighbors to the newly created instance described above. What class would you predict if you compared the new instance to its 3 nearest neighbors?
Question 4
In general do you think it is better to choose k as odd or even? Why?
Learning XOR with a Perceptron model
We define the AND and OR operators such that

We can represent those operators graphically where the green dot represents outcome 1 and the red dot represents outcome 0:

We consider a single layer perceptron model that classifies data points. Let's consider M input variables {X1, X2, …, XM} with each example outcome associated with a binary variable Y ∈ {T, F}. We want to learn the weights {w1, w2, w3, …, wM} such that
and
where w0 is the intercept.
Question 1
Find values for w0, w1 and w2 to classify correctly outcomes of the AND operator in the case M = 2.
Question 2
Find values for w0, w1 and w2 to classify correctly outcomes of the OR operator In the case M = 2.
Question 3
Let's now define the XOR operator such that

Represent on a 2D-graph the outcomes of this operator.
Question 4
We are unable to classify the results of this operator by simply tracing a line on the graph. We say that XOR outcomes are not linearly separable. To be able to learn XOR, we need to induce non-linearity by introducing a "hidden layer" to the model:
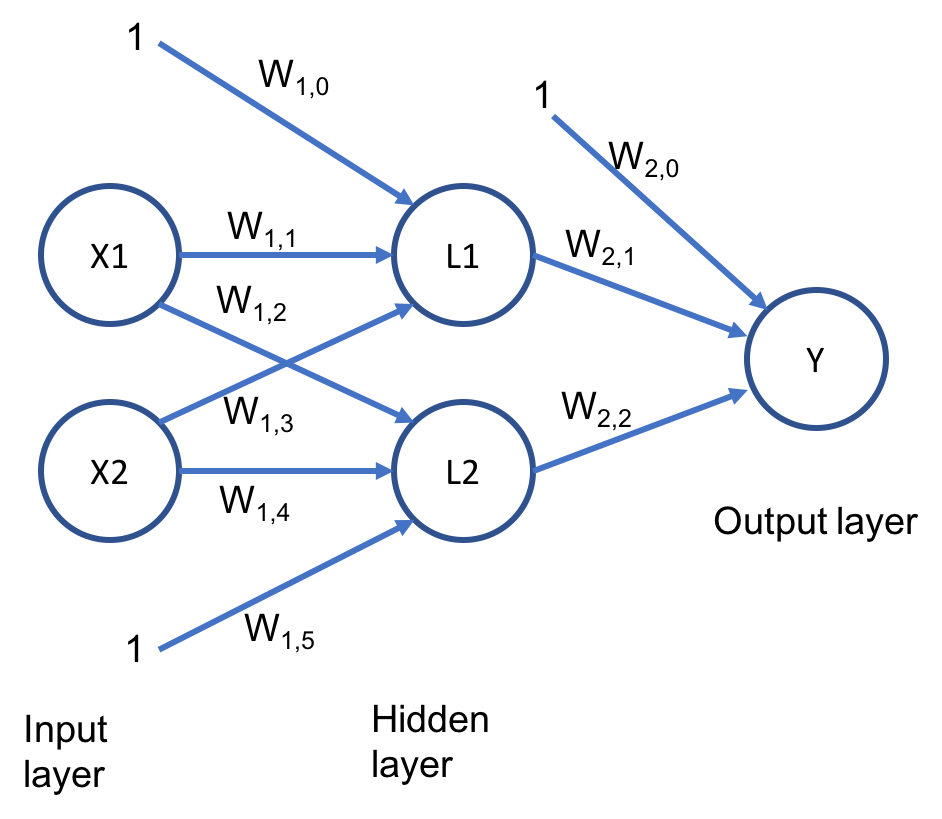
The rules of this more complex model are quite similar. On the input layer, the output in L1 is such that
