

MLOps 101: Feature Stores, Automation, Testing and Monitoring
The fastest emerging field in Machine Learning

Today we dig in the fastest emerging field in Machine Learning: MLOps! This is potentially the best career to choose in ML those days but not enough is being written about it in my opinion. We are going to look at:
The Feature Store: The Data Throne
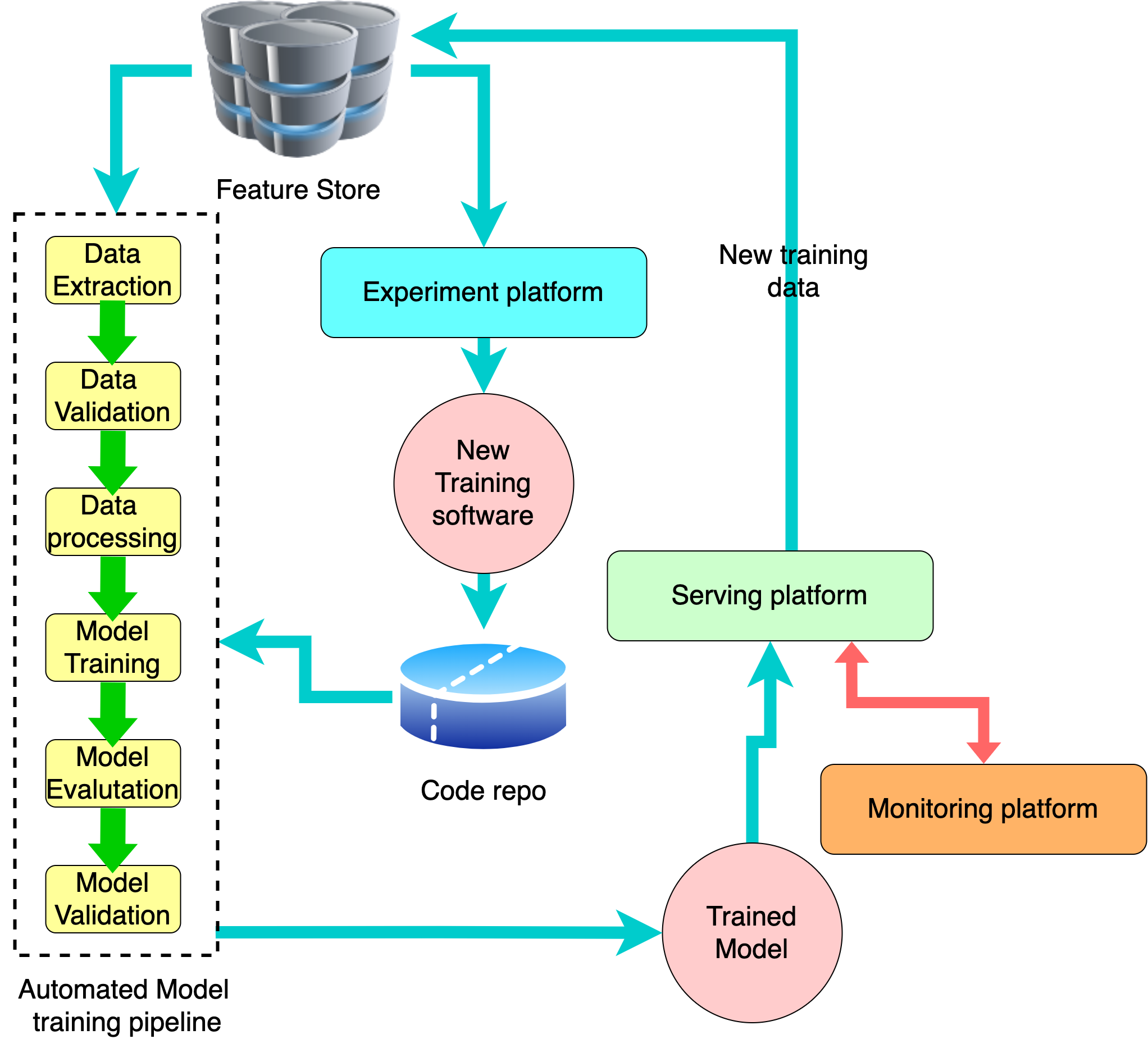
Continuous Integration - Deployment - Training (CI / CD / CT) for ML
Testing and monitoring in ML
In my opinion, MLOps is one the greatest innovations in Machine Learning of the past 10 years! Granted MLOps has actually been around for quite some time, but the processes have become more formalized, the best practices are really spreading across companies and industries in an accelerated manner that has never been seen before. The tools to monitor and automate are becoming much more common. My guess is that becoming a MLOps expert now is one of the best career bet for the years to come!
The Feature Store: The Data Throne
In Machine Learning, the data is king, and the Feature Store is its throne! Do you remember the time when each team was building their own data pipelines, when the data in production was not consistent with the one in development, and when we had no idea how half of the features were created? Those were dark times prior to the era of feature stores! To be fair, not everybody should invest in Feature Stores: if you don't need real-time inference, if you have less than ~10 models in production, or if you don't need frequent retraining, a Feature Store may not be for you.

As far as I know, Uber’s Michelangelo is the first ML platform to introduce a feature store. A feature store is exactly what it sounds like! This is a place where Data Scientists / Machine Learning engineers of different teams can browse features for their next ML development endeavor. You can rely on the quality of the data and consistency is ensured between development and production pipelines. The features originate from streaming and batch sources of data and their computations are centralized and version controlled. Typically, a feature store provides monitoring capability for concept and data drift, a registry to discover features and their metadata, offline storage for model training and batch scoring, and an online store API for real-time applications.
Let's list some of the advantages of feature stores:
The ability to share features between teams and projects
The ability to ensure consistency between training and serving pipelines
The ability to serve features at low latency
The ability to query the features at different points in time: features evolve, so we need a guarantee on the point-in-time correctness.
Ability to monitor features even before they are used in production
Provide feature governance with different levels of access control and versioning
There are tons of vendors available! Feast is an open source project from Google Cloud and Go-Jek and it integrates with KubeFlow. AWS has its own feature store as part of SageMaker. ScribbleData, Tecton, and Hopsworks provide feature stores as well and other MLOps capabilities.
You can read more about it here:
Continuous Integration - Deployment - Training (CI / CD / CT)
If you are working in a big tech company on ML projects, chances are you are working on some version of Continuous Integration / Continuous Deployment (CI/CD). It represents a high level of maturity in MLOps with Continuous Training (CT) at the top. This level of automation really helps ML engineers to solely focus on experimenting with new ideas while delegating repetitive tasks to engineering pipelines and minimizing human errors.
