

The AiEdge+: How to fine-tune Large Language Models with Intermediary models
How do we go from GPT-3 to ChatGPT

If we focus on training Large Language Models to predict the next word, this is unlikely to lead to human-like conversational tools. Moreover LLM can be racist, sexist or politically biased due to the specific training set. How do we deal with that? Today we look at methods to de-bias language models and fine-tune for more human-like behaviors:
Improving Fairness in Large Language Models
Reinforcement Learning from Human Feedback (RLHF)
Learn more about fine-tuning LLMs: articles, YouTube videos and GitHub repositories

Improving Fairness in Large Language Models
Large language models can be racist, sexist or politically biased. I wouldn't blame them, they just tell us what they learned from their training data. As an example, a language model might associate being a doctor with being a man and being a nurse with being a woman. A biased society generates biased data, and in turn, generates biased AI. With tools like ChatGPT that are doomed to engender a lot of future internet data, we are in for a nice feedback loop! Fortunately, new methods are constantly being created!
For example, DeepMind and UCLA came up with an algorithmic method to reduce the bias generated by LLM (“Reducing Sentiment Bias in Language Models via Counterfactual Evaluation“). The idea is simple: train a model such that you penalize the loss function if there is a high difference in "sentiment" between 2 values of a sensitive attribute (eg: male and female for gender). This will lead the model to learn word representations that result in similar sentiments when they are used in a sentence. Here is the way they are doing it:
Train a language model by learning to predict the next token. They used a TransformerXL architecture (“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context“). Their training set is composed of Wikipedia articles (wikitext) and english news articles (wmt19).
Train a sentiment classifier that takes as input the latent representation of the text generated by the Language model, and as output, the sentiment score generated by the Google Cloud sentiment API. The last layer in the classifier can be thought of as a sentiment representation of the original text. For 2 different sentences, you can now measure the cosine similarity between their sentiment representations. This effectively measures how similar the resulting sentiments are.
Continue to train the Language model, but penalize the Loss function (typical cross-entropy to predict the next token) with a regularization term that uses the sentiment classifier. They sample sentences where they change the value of the attributes (eg: "Men could be doctors" + "Women could be doctors"). The more the sentiment similarity is low, the more the loss function is penalized. This will debias the language model in having similar sentiments with respect to men and women when it comes to potentially becoming doctors (for this specific example).
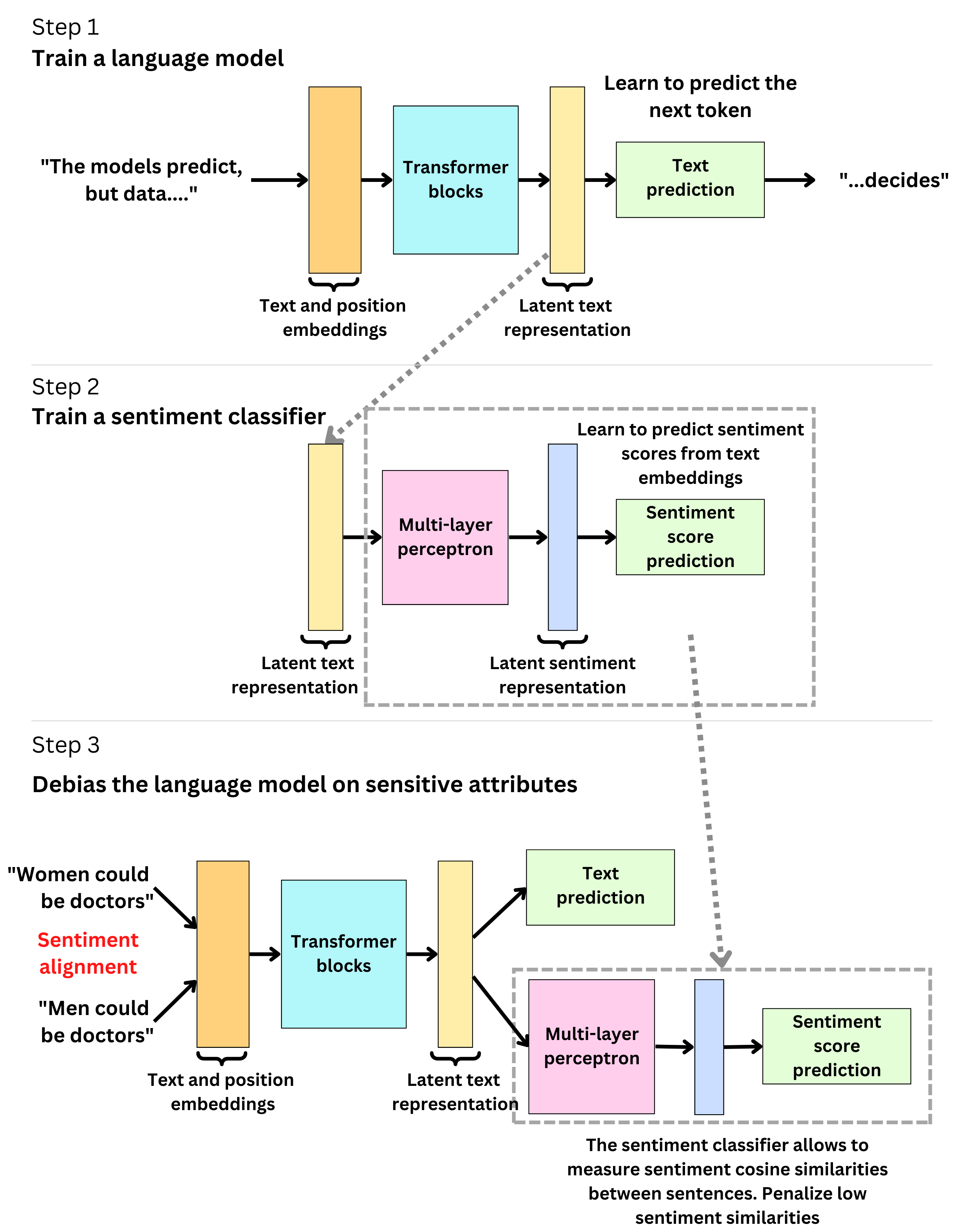
This process increases fairness while keeping model performance high. Fortunately, as we are making impressive progress in NLP, there are also researchers that are working toward mitigating the harm that those models could produce! However, it is also important to realize that the medicine may become the disease! The concept of fairness is subjective and the technique described above could be used to push some ideas while discarding others.
