

The AiEdge+: How to Manage Machine Learning Projects for Maximum ROI
Machine learning is not only about developing models!

Machine learning is all about developing models? Think again! Machine learning is risky and costly and we cannot start a project without planning, coordination and collaboration. Today, we go through the different steps for successful machine learning project management. We look at:
From data to hardware
Machine learning: a bit of team work
How to manage machine learning projects for maximum ROI
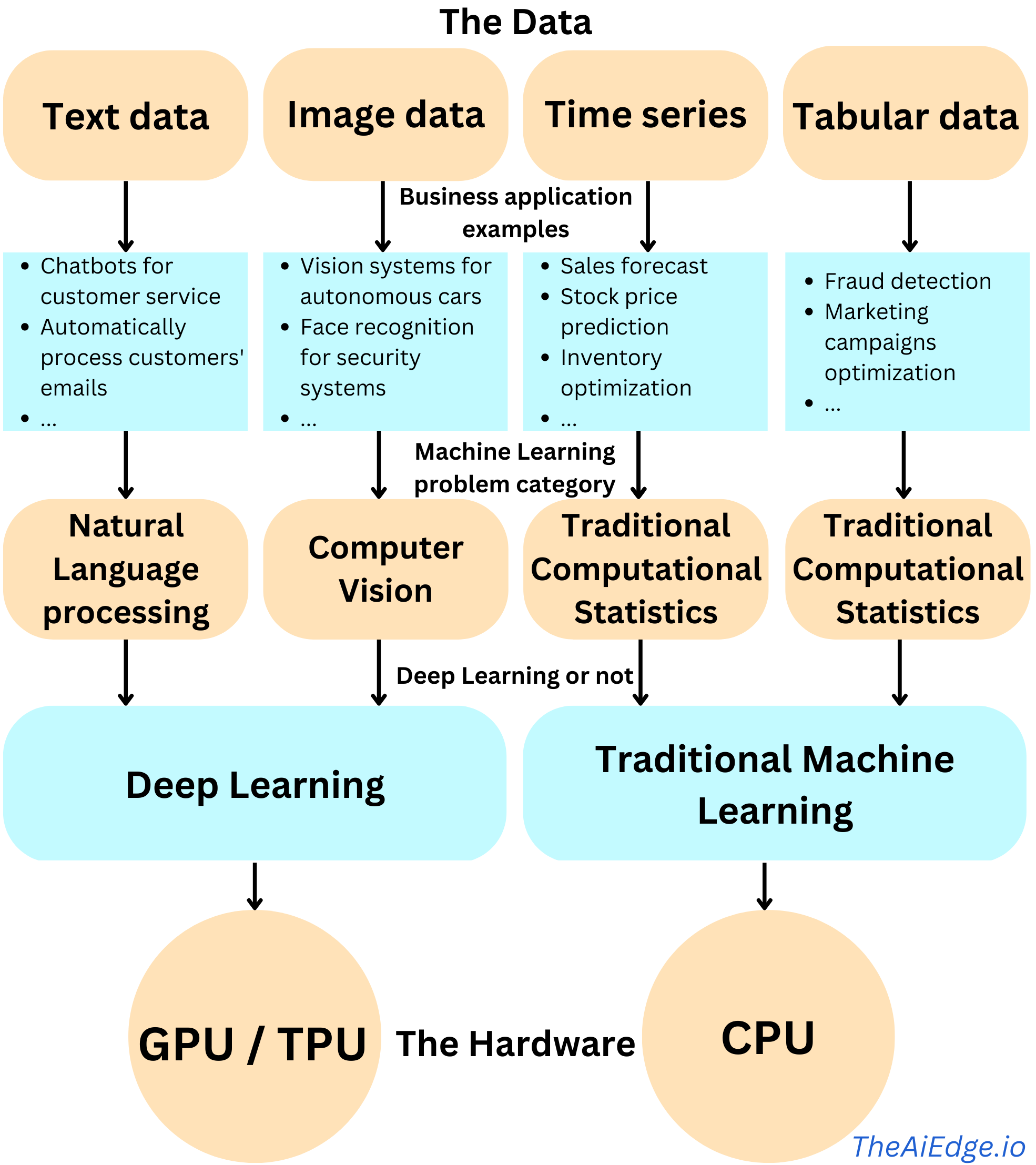
From Data to Hardware
Your data can tell you a lot about the type of Machine Learning you could do, the type of hardware you should invest in and the people you should hire. Here is a simple guide:

Text Data (building chatbots for customer service, …):
Lots of data: suitable for Deep Learning. A robust data engineering infrastructure around the data should be designed. Modeling requires highly specialized people in the domain. GPU machines should increase modeling speed
Small amount of data: Should probably explore first pre-trained DL models. Engineering infrastructure is less important. Modeling could be performed by a less specialized workforce. GPU machines may not be necessary
Image Data (face recognition for security systems, augmented reality systems, ...):
Lots of data: DL will probably generate performance beyond anything traditional techniques could produce. A robust data engineering infrastructure around the data should be designed. Modeling requires highly specialized people. GPU machines are a must.
Small amounts of data: Pre-trained DL Models could yield satisfactory results but should possibly question investing in ML in general for Computer Vision applications. Engineering infrastructure around the data is less important. Modeling could be performed by a less specialized workforce. GPU machines remain important for improving modeling speed.
Time Series Data (sales forecast, stock price prediction, ...):
Lots of data: Traditional methods like XGBoost will generally yield greater performance on time series data. A robust data engineering infrastructure around the data should be designed. Modeling could be performed by generalist data scientists. GPU (for Transformers or LSTM for example) and CPU machines could be leveraged.
Small amounts of data: It is potentially not a problem to be solved with ML techniques. Engineering infrastructure around the data is less important. Modeling could be performed by a less specialized workforce. GPU machines are most likely unnecessary.
Tabular Data (product recommendation, customer churn prediction, ...):
Lots of data: traditional ML techniques usually outperform Deep Learning. However, in the case of recommendation engines with very sparse variables, DL has proven to bring superior performance. A robust data engineering infrastructure around the data should be designed. Modeling could be performed by generalist data scientists. GPU may not be very useful as Deep Learning is less relevant in this case (apart from in the case of Recommender Engines).
Small amount of data: It is probably not a problem to be solved with ML. Should possibly reconsider investing in advanced analytics. A robust data engineering infrastructure around the data is less important. Modeling could be performed by a less specialized workforce. GPU machines are most likely unnecessary.
Machine Learning: a bit of team work
Machine Learning, that is not a one-man job! When it comes to building ML solutions, it is important to think end-to-end: from the customer to the customer. This will help to architect, plan and execute. As part of planning, it is important to understand who will need to be involved and when. Let's run through a typical project.

