

The AiEdge+: Model Compression Techniques
Reducing the cost of Machine Learning

Today we dive into the subject of Model Compression. For widespread adoption and further development of generative ML, we first need to make those models more manageable to deploy and fine-tune. The cost associated with those large models makes model compression one of the most critical research areas in Machine Learning today. We cover:
Model Compression Methods
Knowledge distillation
Learn more about Model Compression Methods

Model Compression Methods
Not too long ago, the biggest Machine Learning models most people would deal with, merely reached a few GB in memory size. Now, every new generative model coming out is between 100B and 1T parameters! To get a sense of the scale, one float parameter that's 32 bits or 4 bytes, so those new models scale between 400 GB to 4 TB in memory, each running on expensive hardware. Because of the massive scale increase, there has been quite a bit of research to reduce the model size while keeping performance up. There are 5 main techniques to compress the model size.
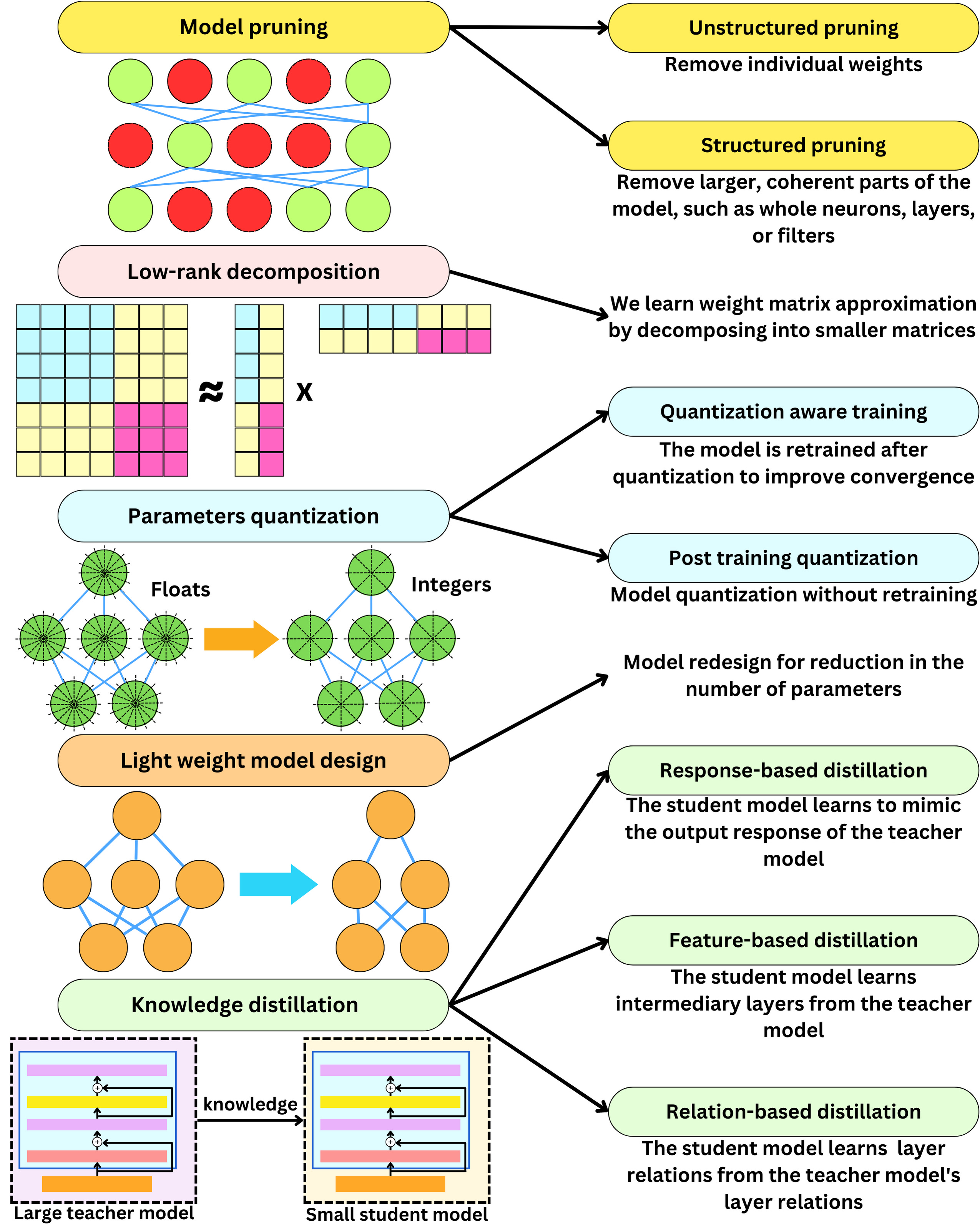
Model pruning is about removing unimportant weights from the network. The game is to understand what "important" means in that context. A typical approach is to measure the impact to the loss function of each weight. This can be done easily by looking at the gradients that approximate the loss variation when varying the weights. In 1989, Yann LeCun established a classic method by computing the second order derivative for improved results. Another way to do it is to use L1 or L2 regularization and get rid of the low magnitude weights. When removing weights across the network following those methods, we reduce model size but the time complexity remains more or less the same due to the way matrix multiplications are parallelized. Removing whole neurons, layers or filters is called "structured pruning" and is more efficient when it comes to inference speed.
Model quantization is about decreasing parameter precision, typically by moving from float (32 bits) to integer (8 bits). That's 4X model compression. Quantizing parameters tends to cause the model to deviate from its convergence point so it is typical to fine-tune it with additional training data to keep model performance high. We call this "Quantization aware training". When we avoid this last step, it is called "Post training quantization", and additional heuristic modifications to the weights can be performed to help performance.
Low-rank decomposition comes from the fact that neural network weight matrices can be approximated by products of low-dimension matrices. A N x N matrix can be approximately decomposed into a product of 2 N x 1 matrices. That's an O(N^2) -> O(N) space complexity gain!
Knowledge distillation is about transferring knowledge from one model to another. Typically from a large model to a smaller one. When the student model learns to produce similar output responses, that is response-based distillation. When the student model learns to reproduce similar intermediate layers, it is called feature-based distillation. When the student model learns to reproduce the interaction between layers, it is called relation-based distillation.
Lightweight model design is about using knowledge from empirical results to design more efficient architectures. That is probably one of the most used methods in LLM research.
I would advise to read the following article to learn more about those methods: “Model Compression for Deep Neural Networks: A Survey“.
Knowledge distillation
In this new Machine Learning era dominated by LLMs, knowledge Distillation is going to be at the forefront of LLMOps. For widespread adoption and further development of generative ML, we first need to make those models more manageable to deploy and fine-tune.
