The ChatGPT Models Family
The language model household that changed the public perception

ChatGPT really changed the public perception when it comes to Large Language Models, for the better and for the worse! Let’s dig deeper into the models that led to ChatGPT and the alternative models that nobody talks about:
The GPT-3 Family
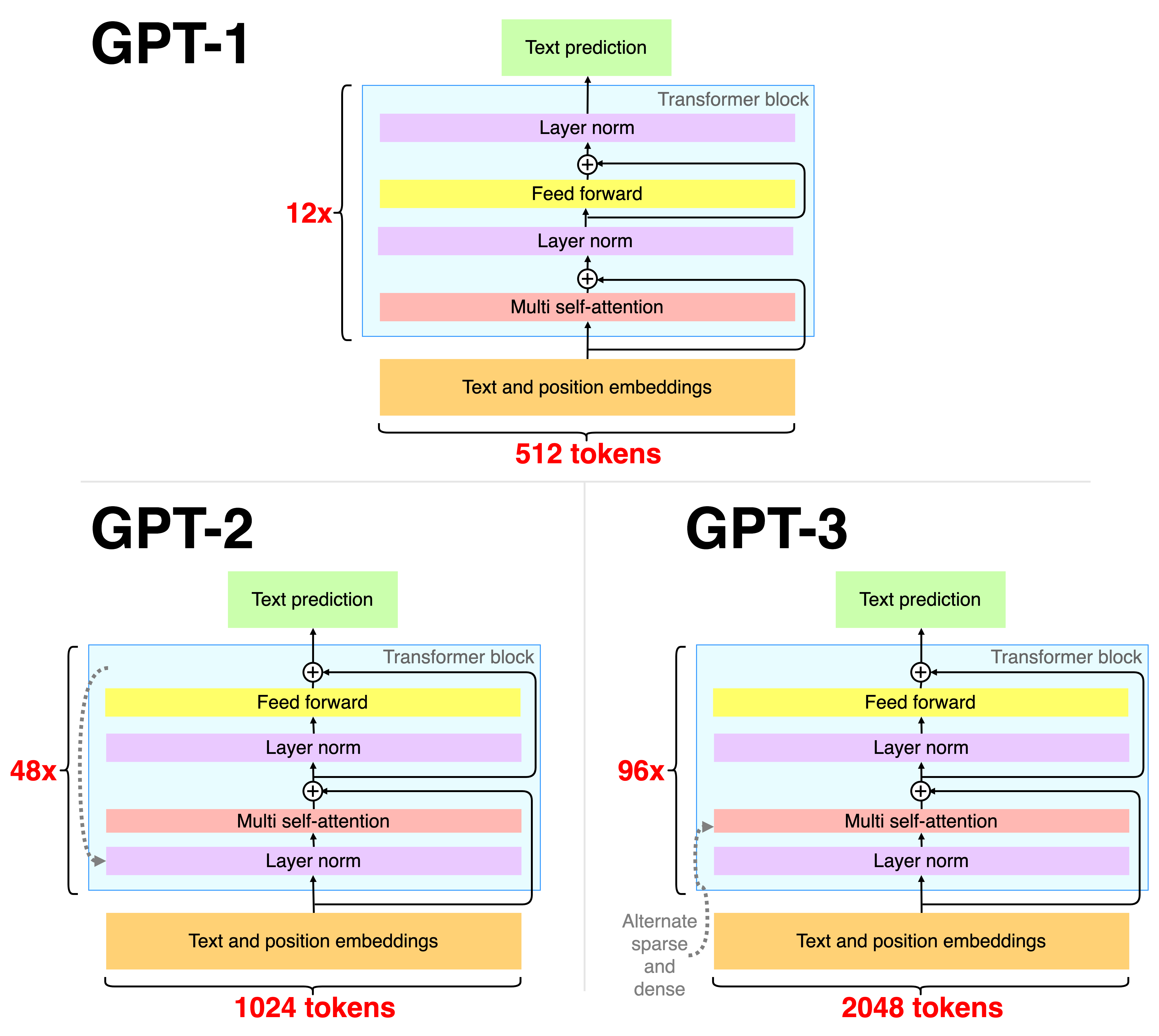
GPT-1 vs GPT-2 vs GPT-3
ChatGPT’s competitors

The GPT-3 Family
There is more to GPT-3 than just GPT-3! In the OpenAI available API [1], GPT-3 represents a fleet of different models that distinguish themselves by size, the data used and the training strategy. The core GPT-3 model [2] is the source of all those derived models.

When it comes to size, OpenAI offers different models that balance the quality of Natural Language Generation and inference speed. The models are labeled with the names of scientists or inventors:
Davinci: 175B parameters
Curie: 6.7B parameters
Babbage: 1B parameters
Cushman: 12B parameters
I am missing "Ada", which is supposed to be faster (so I guess smaller) but they don't document its size.
The models can be fine-tuned in a supervised learning manner with different datasets. The Codex family is specifically designed to generate code by fine-tuning on public Github repos' data [3]. Most of the text generation models (text-davinci-001, text-davinci-002, text-curie-001, text-babbage-001) are actually GPT-3 models fine-tuned with human labeled data as well as with the distillation of the best completions from all of their models. OpenAI actually described those models to be InstructGPT models [4], although the training process is slightly different from the one described in the paper. Text-davinci-002 is specifically described by OpenAI as being fine-tuned with text data from the Codex model code-davinci-002, presumably performing well on both code and text data. Text-davinci-003 is a full InstructGPT model as it is the text-davinci-002 model further refined with a Proximal Policy Optimization algorithm (PPO) [5], a Reinforcement Learning algorithm.
The "GPT-3.5" label refers to models that have been trained on a blend of text and code from before Q4 2021 as opposed to October 2019 for the other models.
OpenAI has been using GPT-3 for many specific applications. For example, they trained text and code alignment models (text-similarity-davinci-001, text-similarity-curie-001) to learn embedding representations of those data [6] in a similar manner to the CLIP model powering DALL-E 2 and Stable Diffusion. They developed a model to summarize text with labeled data in a very similar manner to InstructGPT [7]. They also provide a way to extract the latent representation provided by GPT-like models (text-embedding-ada-002). And we know that ChatGPT is a sibling model to InstructGPT trained from GPT-3.5 so it is probably using Text-davinci-003 as a seed.
GPT-1 vs GPT-2 vs GPT-3
It is actually trivial to build a GPT-3 model! ~100 lines of code would do it. Training that thing is another story though! GPT-1, GPT-2 and GPT-3 are actually very similar in terms of architecture and differ mostly on the data and its size used for training and the number of transformer blocks with the number of incoming tokens.