

The Different Ways to Fine-Tune LLMs

How do you prepare the data for different training / fine-tuning tasks?
For Language modeling
For Sentence prediction
For Text classification
For Token classification
For Text encoding
For Language Modeling
Masked language modeling
In the following, we are going to ignore the difference between “Words” and “Tokens”. Tokens are essentially pieces of words but it doesn’t change the explanations in the following if we conflate the two.
The first step in any training process is to tokenize the data and add padding tokens to get every data sample to be the same length. The size of the input data is the maximum number of tokens that can be ingested into the LLM at once.
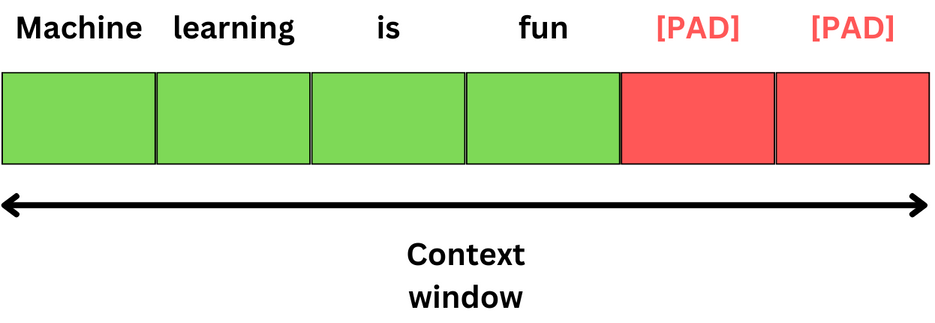
In the context of masked Language modeling, we mask some tokens of the input data, and we want to predict what were those masked tokens. This has been the original way to train transformers since BERT.

We want to train the model to learn what are the probabilities of the words in the sequence. The prediction matrix for each sample in a batch has a dimension [Sequence size, Vocabulary size]. For each position in the token sequence, we have a probability for each token in the vocabulary. Of course, what interests us the most are the positions where the words are masked in the input data.
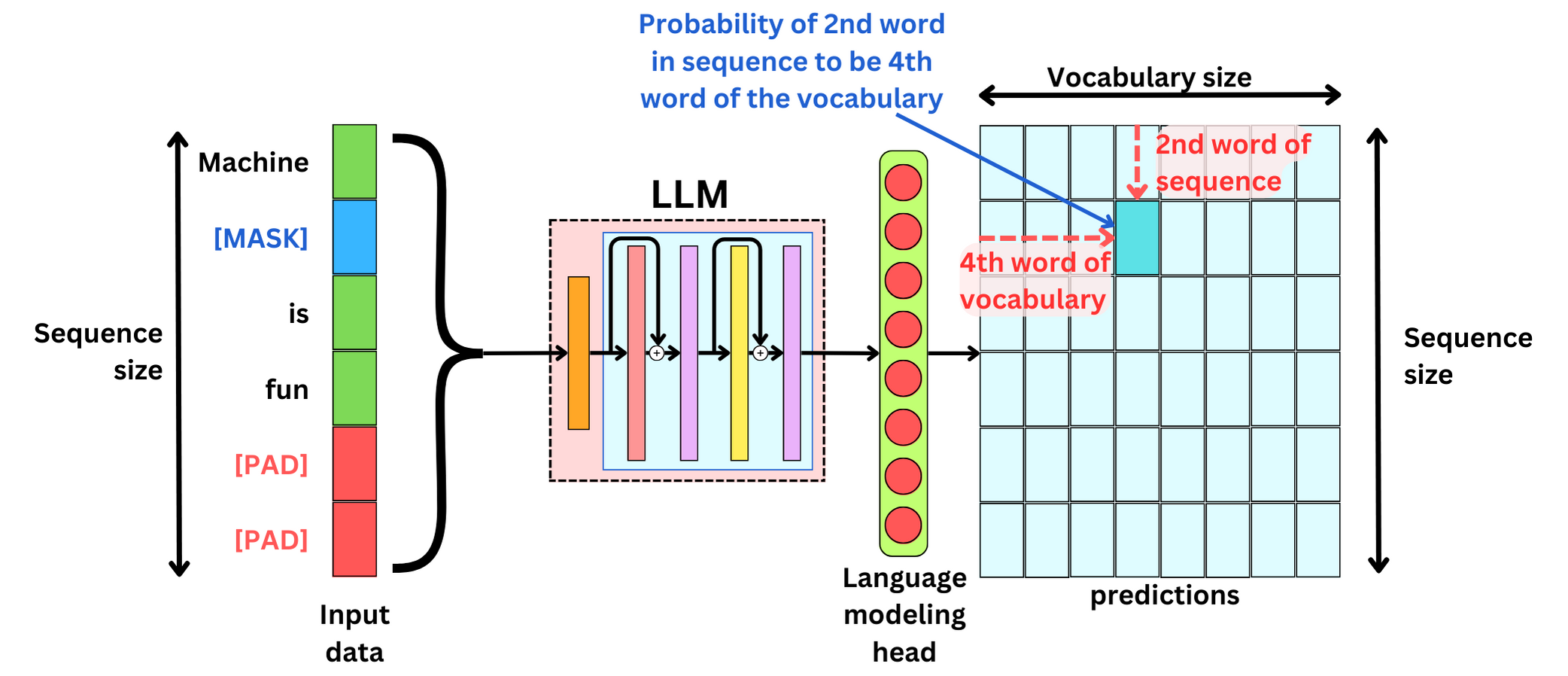
To get the prediction matrix with this dimension, we need to be careful about the prediction head we are using. For each input in the sequence, we get a hidden state coming out of the LLM. For each sample within a batch, the resulting tensor coming out of the LLM has a dimension [Sequence size, Hidden state size]. Therefore, the Language modeling head is a simple linear layer with the number of input features to be Hidden state size and the number of output features to be Vocabulary size. Think about the linear layer as a projection matrix of size [Hidden state size, Vocabulary size] that will resize the hidden state to the vocabulary size.

To train the model, we simply need to compare the predictions for the words that are masked and all the other words are ignored. Typically, we use the cross-entropy loss function for the LLM to learn to predict the masked words.

To generate a sequence at inference time, there might be multiple strategies. The simplest one is to choose the word with the highest predicted probability and to auto-regress. Let’s say we have the first word being “Machine“ as input. Using this as input, we choose the second word in the sequence with the highest probability. Let’s say it is “learning“; now the sequence becomes “Machine learning“. Using those two words as input, we choose the word with the highest probability for the 3rd word in the sequence. We iterate this process until we meet an ending condition, such as the maximum number of tokens or an <END SEQUENCE> token.
Causal language modeling
With Causal Language Modeling, the model learns the language statistics by focusing on predicting the next word in a sequence. This is the more common way to perform Language modeling nowadays and it has been the approach taken in GPT-1, GPT2, and GPT-3.
