

The Gradient Boosted Algorithm Explained!

2013 marks the advent of XGBoost. Xgboost is a gradient boosted algorithm that changed the face of data science! Suddenly, everybody had access to a high-performing ML algorithm that could scale to large datasets. A little after, it gave rise to its little siblings, like LightGBM and CatBoost.
So here, I want to talk about gradient boosting and the way it works. This will give good foundations to address more complex algorithms like Xgboost and its siblings. Let's get into it!
The gradient-boosted trees algorithm is an iterative algorithm. In the first iteration, we need to construct an initial simple learning on the training data. This gives our base tree.

By using that base tree, we can then use it to predict on the same training data, which will lead to predictions from that training data.

Now, we can compare that prediction to the target. We can look at the error we are making by predicting on the training data, and this time, we are going to use the error as a new target for a new tree we are going to train.

The full model now becomes the additive ensemble of trees, and we can use that updated model to generate new predictions on the training data.
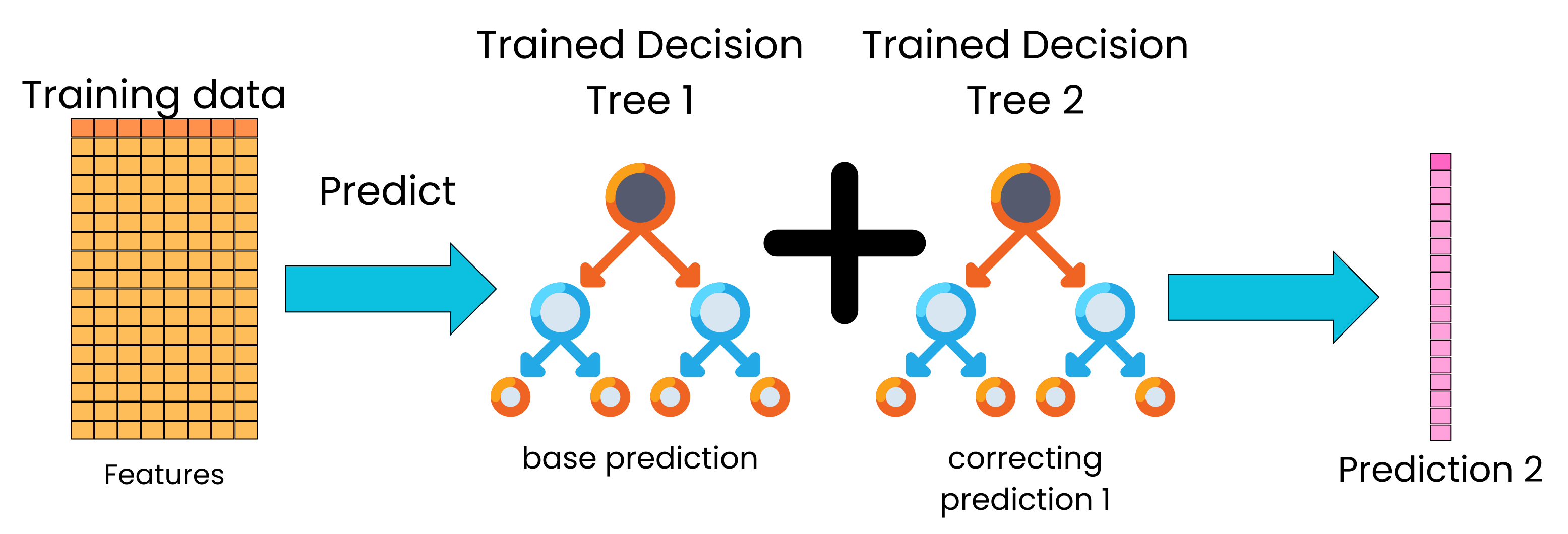
Again, we can compare the predictions that the current model is making to the target and use the resulting computed error as the new target for a new correcting tree.
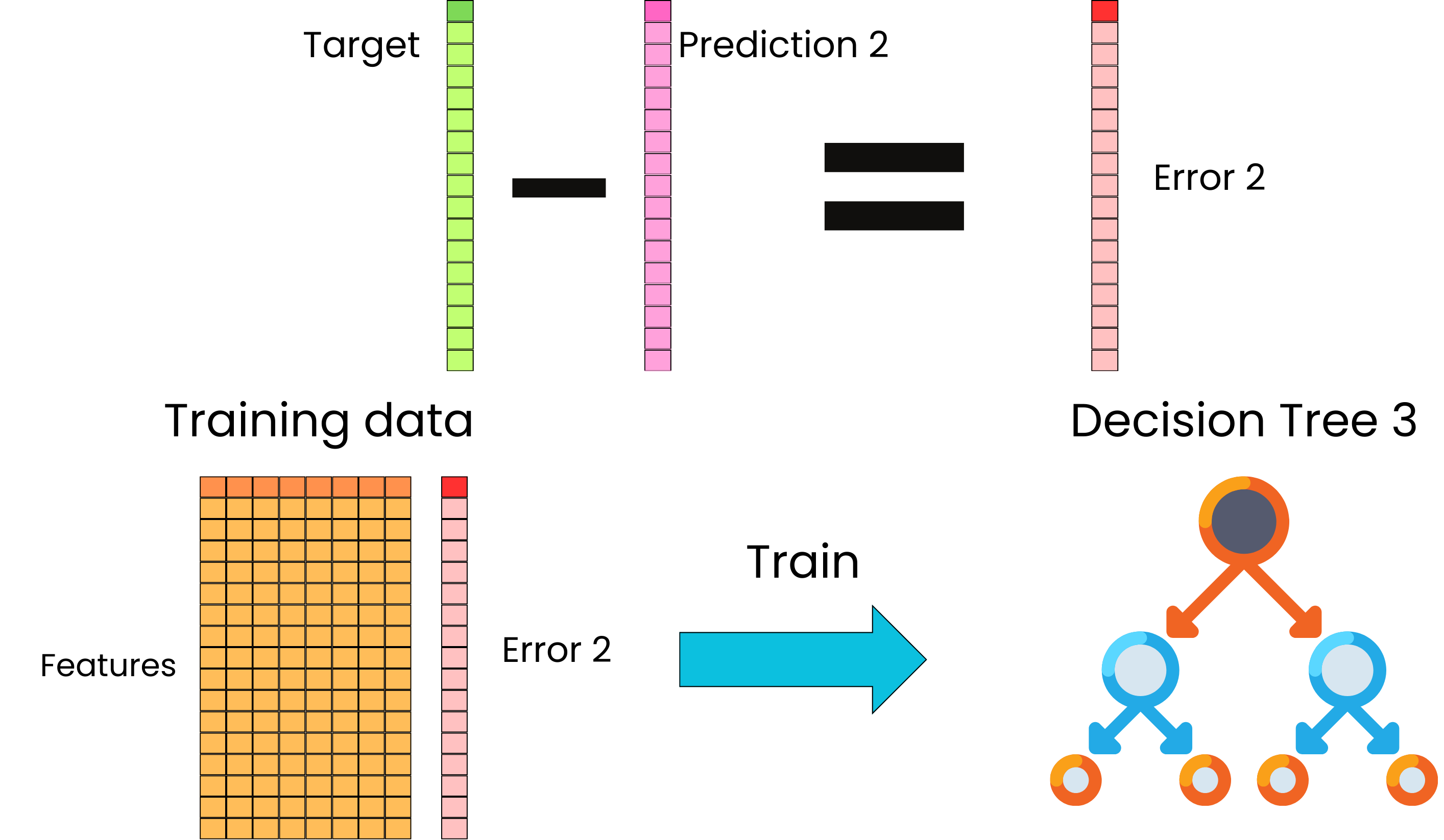
And again, we update the model by adding this new correcting tree to the full ensemble of trees to generate even better predictions.
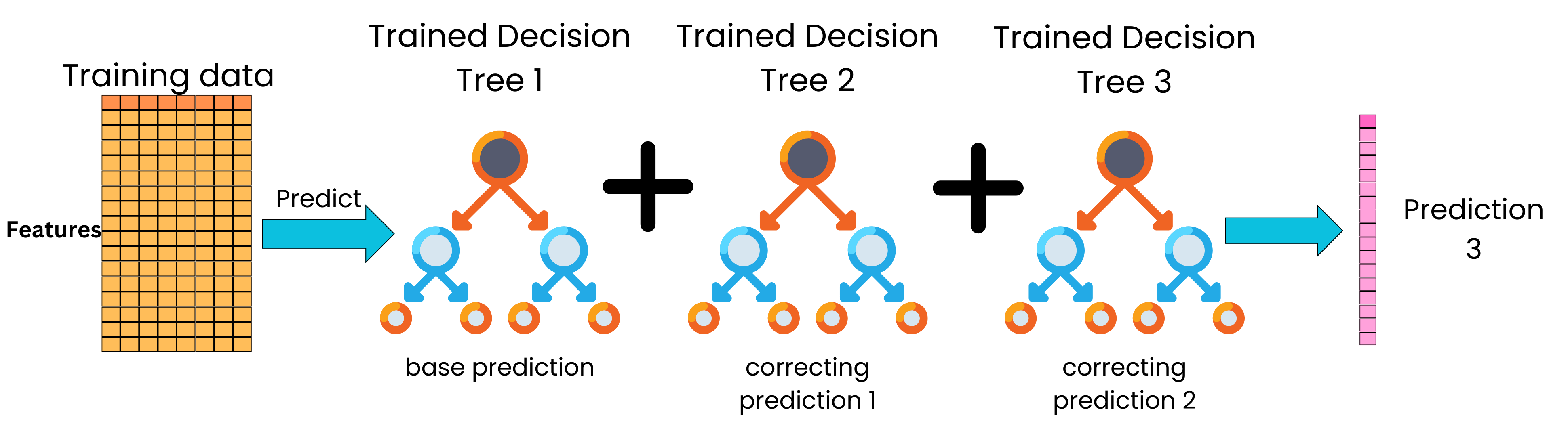
We iterate this process until we start to overfit when we look at the predictive performance on a validation dataset.

So, to summarize, in the gradient-boosted trees algorithm, we iterate the following:
We train a tree on the errors made at the previous iteration
We add the tree to the ensemble, and we predict with the new model
We compute the errors made for this iteration.
At each iteration, the new tree tries to correct the learning done by the previous tree, and we refine little by little the predictions made by the model.
Typically, to prevent overfitting, we use the method of shrinkage. We multiply the contribution of the new tree by a small factor such that the new tree does not have too much impact on the overall prediction. This is to prevent too much overfitting.

Watch the video for more information!
SPONSOR US
Get your product in front of more than 62,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - tens of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing damienb@theaiedge.io.