

The LLM APIs Landscape
How to make a choice?

Text completion
Structured Output
Tool use
Prompt caching
Embeddings
Vision understanding
Audio understanding
Fine-tuning
Tomorrow will be the last day to get the early-bird pricing for the live Machine Learning Fundamentals Bootcamp starting February 12th!

If you want to build LLM pipelines, it is important to understand the full capabilities offered by the different LLM API providers. It is not always about the specific performance or the cost of a model but also the different functionalities provided by the APIs. There are many providers, but I am just going to focus on the following one:
I am leaving out a few other providers and trying to focus on the bigger ones. There are many features provided by those APIs, but I am going to focus on the following important ones:
Text completion
Structured output
Tool use
Prompt caching
PDF parsing
Embeddings
Multimodal embeddings
Vision understanding
Audio understanding
Fine-tuning

Text completion
Text completion is the most obvious capability expected from an API provider. Most providers offer similarly performant models with slight differences. For example, here is the quality index calculated by Artificial Analysis. They compute this quality index as the normalized average of benchmark metrics computed for the different models:

When building LLM pipelines, we care much less about model performance and all the typical benchmark metrics because the game is much more about orchestrating very simple natural language tasks within robust software than exploring edge cases. Considering that all the different LLM API providers offer more or less similarly performant models, the discriminative factors become cost and speed when it comes to building software! On average, the Google LLM models are by far the most cost-effective ones right now! The latency and cost of their models are far lower than their competitors!

While OpenAI is focused on marketing AGI, Google is focused on building useful products for building software. To quote a comment found on social media:
While OpenAI wants to build a Ferrari, Google is the Honda Civic of LLM's
When it comes to cost, Google doesn’t have much competition, and they most likely greatly subsidize their inference cost to capture as much of the market as possible.

To query those APIs, it is basically the same command for most of them:
from openai import OpenAI
from anthropic import Anthropic
import google.generativeai as genai
from cohere import ClientV2
openai_client = OpenAI(api_key=OPENAI_API_KEY)
anthropic_client = Anthropic(api_key=ANTHROPIC_API_KEY)
genai.configure(api_key=GEMINI_API_KEY)
cohere_client = ClientV2(api_key=COHERE_API_KEY)
system_instruction = "You are a helpful assistant."
user_prompt = "Write a haiku about recursion in programming."
# OpenAI
response1 = openai_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_instruction},
{"role": "user", "content": user_prompt}
]
)
# Anthropic
response2 = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
system=system_instruction,
messages=[{"role": "user", "content": user_prompt}]
)
# Google
model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
system_instruction=system_instruction
)
response3 = model.generate_content(user_prompt)
# Cohere
response4 = cohere_client.chat(
model="command-r-plus-08-2024",
messages=[
{"role": "system", "content": system_instruction},
{"role": "user", "content": user_prompt}
]
)Grok and DeepSeek don’t have a dedicated Python package, so we need to rely on the OpenAI Python package that provides an interface to interact with those APIs:
xai_client = OpenAI(base_url="https://api.x.ai/v1", api_key=XAI_API_KEY)
ds_client = OpenAI(
base_url="https://api.deepseek.com",
api_key=DEEPSEEK_API_KEY
)
# Grok
response5 = xai_client.chat.completions.create(
model="grok-2-latest",
messages=[
{"role": "system", "content": system_instruction},
{"role": "user", "content": user_prompt}
]
)
# DeepSeek
response6 = ds_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_instruction},
{"role": "user", "content": user_prompt}
]
)The Google API even provides a memory functionality to remember the conversation:
chat = model.start_chat()
response = chat.send_message(user_prompt)
print(response.text)
response = chat.send_message('Try another one')
print(response.text)
> Function calls self,
Smaller problems it creates,
Base case ends the loop.
A mirror's reflection,
Code calls itself again, deep,
Until it sees base.Structured Output
The ability to return structured output is, in my opinion, one of the most important features provided by an API. It ensures internal data output quality checks and prevents us from having to implement ad-hoc parsers. Agentic patterns like ReAct, for example, require a very specific format of the LLM output:
...
Thought: I need to find out Harry Styles' age.
Action: Search
Action Input: "Harry Styles age"
Observation: 29 years
...Older models like GPT-3.5-Turbo had a tendency to fail in following that template, leading to parsing errors. With structured output, we have much more certainty in what the API actually returns, and since the LLM is guided by the function signature, it is constrained to fill in relevant fields instead of generating tangential text.
For example, let’s imagine we want to build a UI in HTML. HTML follows a very strict format, and we cannot afford any formatting errors. OpenAI allows to define the output format with Pydantic:
from enum import Enum
from typing import List
from pydantic import BaseModel
class UIType(str, Enum):
div = "div"
button = "button"
header = "header"
section = "section"
field = "field"
form = "form"
class Attribute(BaseModel):
name: str
value: str
class UI(BaseModel):
type: UIType
label: str
children: List["UI"]
attributes: List[Attribute]
UI.model_rebuild() # This is required to enable recursive types
class Response(BaseModel):
ui: UINow, we can use this format to make a call with instructions:
from openai import OpenAI
client = OpenAI(api_key=OPENAI_API_KEY)
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a UI generator AI. Convert the user input into a UI."},
{"role": "user", "content": "Make a User Profile Form"}
],
response_format=UI,
)
ui = completion.choices[0].message.parsed
> UI(type=<UIType.form: 'form'>, label='User Profile Form', children=[UI(type=<UIType.field: 'field'>, label='First Name', children=[], attributes=[Attribute(name='placeholder', value='Enter your first name'), Attribute(name='required', value='true')]), UI(type=<UIType.field: 'field'>, label='Last Name', children=[], attributes=[Attribute(name='placeholder', value='Enter your last name'), Attribute(name='required', value='true')]), UI(type=<UIType.field: 'field'>, label='Email', children=[], attributes=[Attribute(name='placeholder', value='Enter your email'), Attribute(name='required', value='true'), Attribute(name='type', value='email')]), UI(type=<UIType.field: 'field'>, label='Phone Number', children=[], attributes=[Attribute(name='placeholder', value='Enter your phone number'), Attribute(name='type', value='tel')]), UI(type=<UIType.field: 'field'>, label='Password', children=[], attributes=[Attribute(name='placeholder', value='Enter your password'), Attribute(name='required', value='true'), Attribute(name='type', value='password')]), UI(type=<UIType.button: 'button'>, label='Submit', children=[], attributes=[Attribute(name='type', value='submit')])], attributes=[])We can easily programmatically parse this output to utilize its content. Internally, if formatting errors occur, the API can retry the generation multiple times. In the case the model cannot adhere to the exact format, a refusal message is provided, and we can conditionally change the flow of the application.
if completion.choices[0].message.refusal:
# do something else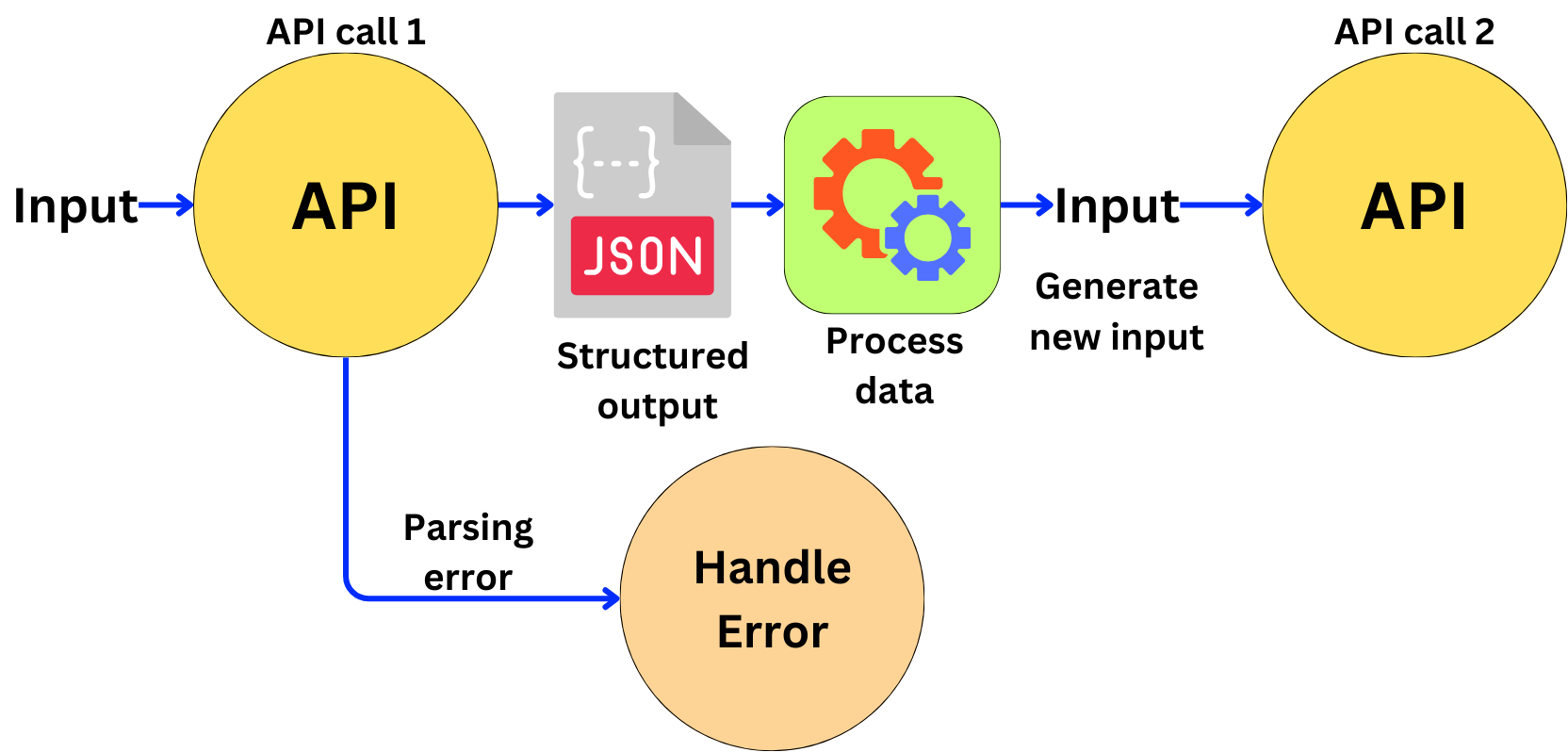
Anthropic, Grok, DeepSeek, and Cohere require to specify the format output with JSON instead of Pydantic, which may be harder to understand:
schema = {
"type": "object",
"properties": {
"ui": {
"type": "object",
"properties": {
"type": {
"type": "string",
"enum": ["div", "button", "header", "section", "field", "form"]
},
"label": {
"type": "string"
},
"children": {
"type": "array",
"items": {
"$ref": "#/properties/ui"
}
},
"attributes": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"value": {
"type": "string"
}
},
"required": ["name", "value"]
}
}
},
"required": ["type", "label", "children", "attributes"]
}
},
"required": ["ui"]
} For example, in Anthropic, the structured output is handled by using the tools argument.
from anthropic import Anthropic
client = Anthropic(api_key=ANTHROPIC_API_KEY)
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=8000,
tools=[
{
"name": "ui",
"description": "UI using well-structured JSON.",
"input_schema": schema,
}
],
tool_choice={"type": "tool", "name": "ui"},
system="You are a UI generator AI. Convert the user input into a UI.",
messages=[{"role": "user", "content": "Make a User Profile Form"}],
)
message.content[0].input
> {'ui': {'type': 'div',
'label': 'User Profile Container',
'attributes': [{'name': 'class', 'value': 'profile-container'}],
'children': [{'type': 'header',
'label': 'User Profile',
'attributes': [{'name': 'class', 'value': 'profile-header'}],
'children': []},
{'type': 'form',
'label': 'Profile Form',
'attributes': [{'name': 'class', 'value': 'profile-form'}],
'children': [{'type': 'section',
'label': 'Personal Information',
'attributes': [{'name': 'class', 'value': 'form-section'}],
'children': [{'type': 'field',
'label': 'Full Name',
'attributes': [{'name': 'type', 'value': 'text'},
{'name': 'required', 'value': 'true'}],
'children': []},
{'type': 'field',
'label': 'Email Address',
'attributes': [{'name': 'type', 'value': 'email'},
{'name': 'required', 'value': 'true'}],
'children': []},
{'type': 'field',
'label': 'Phone Number',
'attributes': [{'name': 'type', 'value': 'tel'}],
'children': []}]},
{'type': 'section',
'label': 'Address',
'attributes': [{'name': 'class', 'value': 'form-section'}],
'children': [{'type': 'field',
'label': 'Street Address',
'attributes': [{'name': 'type', 'value': 'text'}],
'children': []},
{'type': 'field',
'label': 'City',
'attributes': [{'name': 'type', 'value': 'text'}],
'children': []},
{'type': 'field',
'label': 'State/Province',
'attributes': [{'name': 'type', 'value': 'text'}],
'children': []},
{'type': 'field',
'label': 'Postal Code',
'attributes': [{'name': 'type', 'value': 'text'}],
'children': []}]},
{'type': 'button',
'label': 'Save Profile',
'attributes': [{'name': 'type', 'value': 'submit'},
{'name': 'class', 'value': 'submit-button'}],
'children': []}]}]}}The “tool” in that context is the post-processing module that parses the structured output, and the structured output is the “input” to that “tool”.
