

The Position Encoding In Transformers!

Transformers and the self-attention are powerful architectures to enable large language models, but we need a mechanism for them to understand the order of the different tokens we input into the models. The position encoding is that mechanism! There are many ways to encode the positions, but let me show you the way it was developed in the "Attention is all you need" paper. Let's get into it!
Watch the video for the full content:
The position embedding is used to add the position information to the semantic information of the words. We encode each token by its semantic representation with the token embedding and by its position representation with the position embedding. We just add the two vector representations to obtain an encoding that encodes both the semantic and the position.
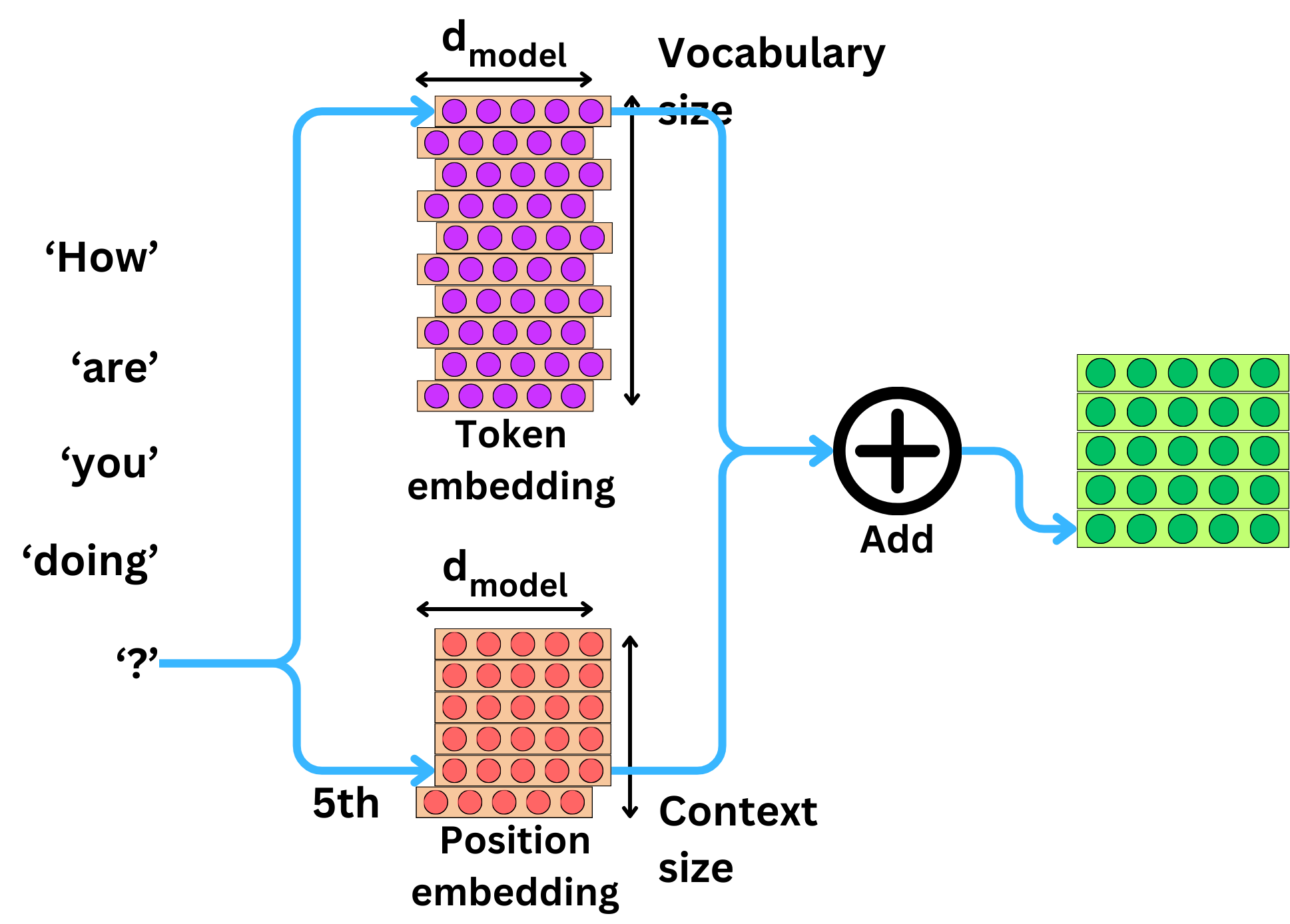
It is important because, without it, the attention layers would not be able to understand the order of the words in the sentences.
The typical way to implement the values of the embedding is by hard coding them by using a sine and cosine function of the vectors and elements’ positions. The sine and cosine functions provide smooth and continuous representations, which help in learning the relative positions effectively. For example, the encoding for positions k and k+1 will be similar, reflecting their proximity in the sequence. The frequency-based sinusoidal functions allow the encoding to generalize to sequences of arbitrary length without needing to re-learn positional information for different sequence lengths. The model can understand relative positions beyond the length of sequences seen during training. The combination of sine and cosine functions ensures that each position has a unique encoding. The orthogonality property of these functions helps in distinguishing between different positions effectively, even for long sequences. The different frequencies used in the positional encodings allow the model to capture both short-term and long-term dependencies within the sequence. Higher frequency components help in understanding local relationships, while lower frequency components help in capturing global structures.
Also, sinusoidal functions are differentiable, which is crucial for backpropagation during training. This ensures that the model can learn to use the positional encodings effectively through gradient-based optimization methods.

Along a column, we have the natural progression of a sine or cosine function with the period depending on the position of the column.

And along a row, we alternate between sine and cosine.

SPONSOR US
Get your product in front of more than 66,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - tens of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
To ensure your ad reaches this influential audience, reserve your space now by emailing damienb@theaiedge.io.