

The Tools Landscape for LLM Pipelines Orchestration (Part 1)
Micro-orchestration VS Macro-orchestration

Micro-Orchestration
Prompt Management
Input preprocessing and output postprocessing
Handling of model-specific parameters and configurations
Chaining of multiple LLM calls within a single logical operation
Integration of external tools or APIs at a task-specific level
Tracing and Logging
Macro-Orchestration
Complex Graphical Applications
Stateful Application
Agentic Design

For a long time, I was in love with LangChain, mostly because the documentation was structured to educate the users about LLM pipeline orchestration and showcased how they approached building a solution for implementing those pipelines. To some extent, all the existing frameworks took their own opinionated approach to provide solutions to the complexities around LLM pipeline orchestration.
Getting a wide overview of the different capabilities provided by those frameworks is a real learning experience in terms of what it means to build LLM applications, what the typical difficulties are, and how to address those. There are many overlaps in the capabilities of the different frameworks, but I tend to separate those by their specialties:
Micro-orchestration: I refer to Micro-orchestration as the fine-grained coordination and management of individual LLM interactions and related processes. It is more about the granular details of how data flows into, through, and out of LLM within a single task or a small set of related tasks.
Macro-orchestration: it is more about the high-level design, coordination, and management of complex workflows that may incorporate multiple LLM interactions, as well as other AI and non-AI components. It focuses on the overall structure and flow of larger systems or applications.
Agentic Design Frameworks: These frameworks focus on creating and managing autonomous or semi-autonomous AI agents that can perform complex tasks, often involving multiple steps, decision-making, and interaction with other agents or systems:
Optimizer frameworks: These frameworks use algorithmic approaches, often inspired by techniques like backpropagation, to optimize prompts, outputs, and overall system performance in LLM applications. The optimization process is typically guided by specific performance metrics or objectives.

As time went on, I realized it tends to be easier to implement myself the different utilities provided by micro-orchestration frameworks. They tend to over-complicate things, and it can take longer to debug those frameworks for a custom use-case than to implement everything from scratch by using the underlying APIs. However, It is important to not overlook the capabilities provided for tracing and logging of the different LLM calls.
I believe, however, that it is critical to look at the macro-orchestration frameworks more closely as they provide a higher level of control that is fundamental for building large applications.
Nevertheless, let’s review the utilities provided by micro and macro orchestration frameworks!
Micro-Orchestration
I refer to Micro-orchestration in LLM pipelines as the fine-grained coordination and management of individual LLM interactions and related processes. It is more about the granular details of how data flows into, through, and out of language models within a single task or a small set of closely related tasks. It can involve things like:
Prompt Management
Input preprocessing and output postprocessing
Data connection
Handling of model-specific parameters and configurations
Chaining of multiple LLM calls within a single logical operation
Integration of external tools or APIs at a task-specific level
The best examples of that are LangChain, LlamaIndex, Haystack, Semantic Kernel, and AdalFlow.
Prompt Management

All those frameworks, for the better or worse, have a way to structure the prompt inputs to a model. For example, in LangChain, we can wrap a string with the PromptTemplate class:
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a joke about {topic}"
)
prompt_template.invoke({"topic": "cats"})
> StringPromptValue(text='Tell me a joke about cats')For example, AdalFlow and Haystack use the Jinja2 package as the templating engine:
from jinja2 import Template
prompt_template = Template("Tell me a joke about {{ topic }}")
prompt_template.render(topic="cats")
> 'Tell me a joke about cats'This may seem unnecessary in some cases, as we can do pretty much the same thing with the default Python string:
prompt = "Tell me a joke about {topic}"
prompt.format(topic="cats")
> 'Tell me a joke about cats'However, this can help with maintenance and safer handling of user inputs as it allows for the enforcement of all the required variables. Let’s take, for example, how we create messages in Haystack:
from haystack.dataclasses import ChatMessage
ChatMessage.from_user("Tell me a joke about {topic}")
> ChatMessage(content='Tell me a joke about {topic}', role=<ChatRole.USER: 'user'>, name=None, meta={})It is a Python data class that provides a more robust Python object to validate the text input than the simpler:
message = {
"content": "Tell me a joke about {topic}",
"role": "user"
}For example, in Langchain, we can create ChatPrompTemplate object that will parse all the information:
from langchain_core.prompts import ChatPromptTemplate
messages = [
("system", "You are an AI assistant."),
("user", "Tell me a joke about {topic}"),
]
prompt = ChatPromptTemplate.from_messages(messages)
> ChatPromptTemplate(input_variables=['topic'], messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are an AI assistant.')), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['topic'], template='Tell me a joke about {topic}'))])And it becomes easier to manipulate the underlying data. For example, I can more easily access the input variables:
prompt.input_variables
> ['topic']Also, the class is going to throw an error if the wrong role is injected:
messages = [
("system", "You are an AI assistant."),
("wrong_role", "Tell me a joke about {topic}"),
]
prompt = ChatPromptTemplate.from_messages(messages)
Although it is not groundbreaking, it provides intermediary checks across the code for data validation, so bugs are easier to detect.
In most cases, this allows for better integration of the prompting aspect with the rest of the software. For example, it is used in Langchain to integrate with the other components, such as models:
from langchain_openai import ChatOpenAI
model = ChatOpenAI()
chain = prompt | model
chain.invoke('cat')
> AIMessage(content="Sure, here's a cat joke for you:\n\nWhy was the cat sitting on the computer?\n\nBecause it wanted to keep an eye on the mouse!", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 30, 'prompt_tokens': 23, 'total_tokens': 53, 'completion_tokens_details': {'audio_tokens': 0, 'reasoning_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-040b7a4e-472a-45bc-8881-6dccf689cf74-0', usage_metadata={'input_tokens': 23, 'output_tokens': 30, 'total_tokens': 53})This provides a shorthand notation for injecting prompts into a model in a controlled manner.
Having more control over the prompt object allows the implementation of prompt-specific operations. For example, here is how we can build a few-shots example prompt in Langchain:
from langchain_core.prompts import FewShotPromptTemplate
from langchain_core.prompts import PromptTemplate
# Define the example template
example_prompt = PromptTemplate.from_template(
"Question: {question}\n{answer}"
)
# Examples
examples = [
{"question": "What's 2+2?", "answer": "2+2 = 4"},
{"question": "What's 3+3?", "answer": "3+3 = 6"}
]
# Build the prompt
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"],
)
prompt.invoke({"input": "What's 5+2?"}).to_string()
> Question: What's 2+2?
2+2 = 4
Question: What's 3+3?
3+3 = 6
Question: What's 5+2?And here is how you would do the same thing in Jinja2:
from jinja2 import Template
# Define the example template
example_template = Template("Question: {{ question }}\n{{ answer }}")
# Define the full prompt template
prompt_template = Template(
"""{% for example in examples %}
{{ example_template.render(question=example.question, answer=example.answer) }}
{% endfor %}
Question: {{ input }}"""
)
# Render the prompt
prompt = prompt_template.render(
examples=examples,
example_template=example_template,
input="What's 5+2?"
)Input preprocessing and output postprocessing

Another important aspect of micro-orchestration is the set of utility functions available to preprocess and post-process the data coming in and out of models. Most frameworks provide functionalities to load local data:
# LlamaIndex
from llama_index.core import SimpleDirectoryReader
loader = SimpleDirectoryReader("./book")
documents = loader.load_data()
# LangChain
from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader("./book")
documents = loader.load()
# Haystack
from haystack.components.converters import TextFileToDocument
from pathlib import Path
text_converter = TextFileToDocument()
documents = text_converter.run(
sources=[str(p) for p in Path("./book").glob("*.txt")]
)
> {'documents': [Document(id=cdd554d8c6fb6987d37481b471114eadce6457a2ced36dbdc821d8f0dfdb4b32, content: '
Chapter I.]
It is a truth universally acknowledged, that a single man in possession
of a goo...', meta: {'file_path': 'book/pride-and-prejudice.txt'})]}Those frameworks provide support for a wide variety of data types and file extentions such as .txt, .pdf, .HTML, .md, .json, .csv, .docx, .xlsx, .pptx, … and they make it easy to inject data in the application. All those frameworks maintain a framework-specific Document class to handle text data and its metadata moving around. All those frameworks provide text splitters capabilities to split the text in smaller manageable chunks of text that can be passed to LLMs:
# LangChain
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = splitter.split_documents(documents)
# LlamaIndex
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(chunk_size=1200, chunk_overlap=100)
nodes = splitter.get_nodes_from_documents(documents)
# Haystack
from haystack.components.preprocessors import DocumentSplitter
splitter = DocumentSplitter(split_by="sentence", split_length=3)
docs = splitter.run(documents['documents'])
# AdalFlow
from adalflow.components.data_process.text_splitter import TextSplitter
splitter = TextSplitter(split_by="word",chunk_size=50, chunk_overlap=1)
docs = splitter.call(documents=docs)None of those methods are hard to implement, but they are often useful utilities that are worth using.
Post-processors can be very useful to convert the free-form text output of LLMs into structured data that can be used programmatically. All those frameworks contain multiple types of parser. Here, for example, how we could parse a JSON formatted string into a Pydantic model in LangChain and LlamaIndex:
from pydantic import BaseModel, Field
from typing import List
class Actor(BaseModel):
name: str = Field(description="name of an actor")
film_names: List[str] = Field(description="list of names of films they starred in")
json_str = '{"name": "Tom Hanks", "film_names": ["Forrest Gump"]}'
# Langchain
from langchain_core.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Actor)
parser.parse(json_str)
# llamaindex
from llama_index.core.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(output_cls=Actor)
parsed = parser.parse(json_str)
> Actor(name='Tom Hanks', film_names=['Forrest Gump'])In Langchain, we can even use the help of another LLM to correct the format in case the previous misformatted the output. For example, the following is not a correct jSON string:
misformatted = "{'name': 'Tom Hanks', 'film_names': 'Forrest Gump']"But we can create a new parser to reformat the output correctly:
from langchain.output_parsers import OutputFixingParser
new_parser = OutputFixingParser.from_llm(
parser=parser, llm=ChatOpenAI()
)
new_parser.parse(misformatted)
> Actor(name='Tom Hanks', film_names=['Forrest Gump'])Another useful post-processing is when we need to rerank the documents coming from a datastore retrieval, for example.
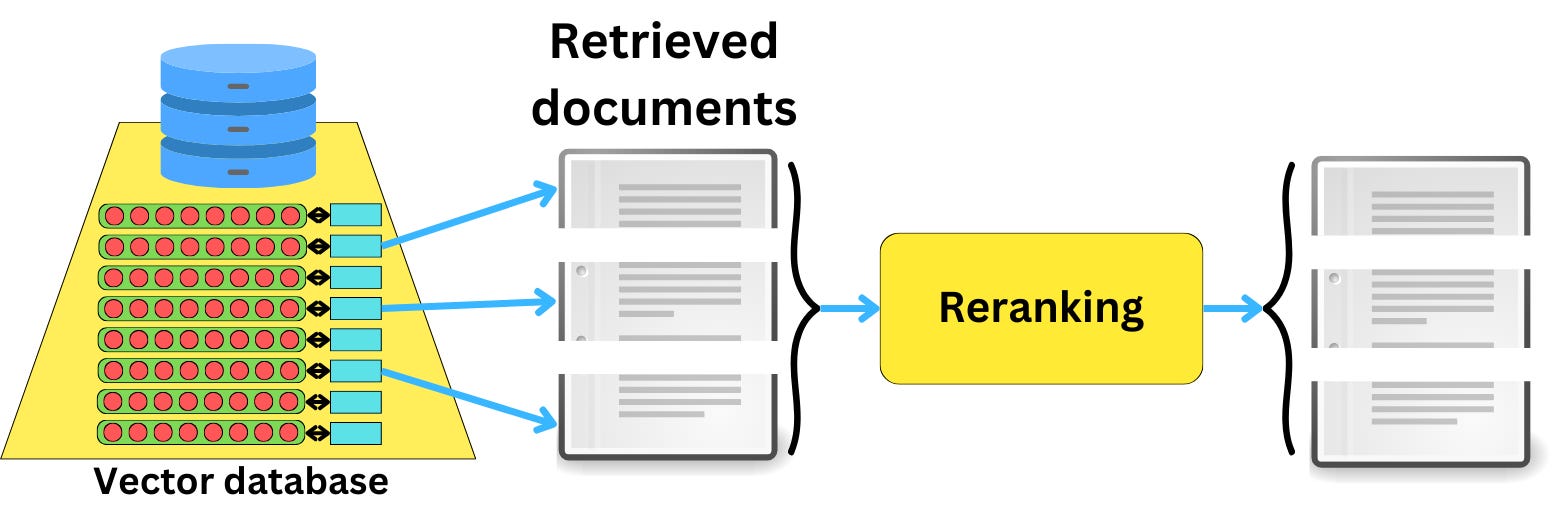
Here is how we can rerank documents in Haystack to induce more diversity in the provided document based on a specific query:
from haystack.components.rankers import SentenceTransformersDiversityRanker
ranker = SentenceTransformersDiversityRanker(
model="sentence-transformers/all-MiniLM-L6-v2",
similarity="cosine"
)
ranker.warm_up()
query = "How can I maintain physical fitness?"
docs = ranker.run(query=query, documents=docs['documents'])Handling of model-specific parameters and configurations
One important aspect of those frameworks is to abstract away the specificity of the third-party APIs or models you chose to build your pipelines. The way the models are used is uniformized across the different APIs. For example, in LangChain, we can instantiate an LLM object interacting with the OpenAI API:
from langchain_openai import ChatOpenAI
# OpenAI model
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.7,
) but we can do the same thing for a local model when using Llama.cpp:
from langchain_community.llms import LlamaCpp
# Local model using llama.cpp
llm = LlamaCpp(
model_path="./models/mistral-7b.gguf",
temperature=0.7,
max_tokens=500,
n_ctx=2048,
n_gpu_layers=1 # Number of layers to offload to GPU
)As far as the rest of the code is concerned, we just use an LLM object that is independent from the underlying model, and we can predict without thinking of the specific API:
chain = prompt | llm
chain.invoke('cat') That is where the value of those frameworks becomes interesting. When we build pipelines, we need to integrate multiple tools together, such as LLM APIs or datastore, and we want to use different LLMs or tools for different cases without needing to adapt the code for it. So, those frameworks provide a uniformized platform that will take away the complexity of integration. Most of those frameworks support those LLM providers:
Those integrations will be able to handle the model-specific configurations when instantiating.
Chaining of multiple LLM calls within a single logical operation
One of the novel ideas, when micro-orchestration came around, was the ability to pipe multiple LLM calls in sequence or in parallel to solve more complex problems.
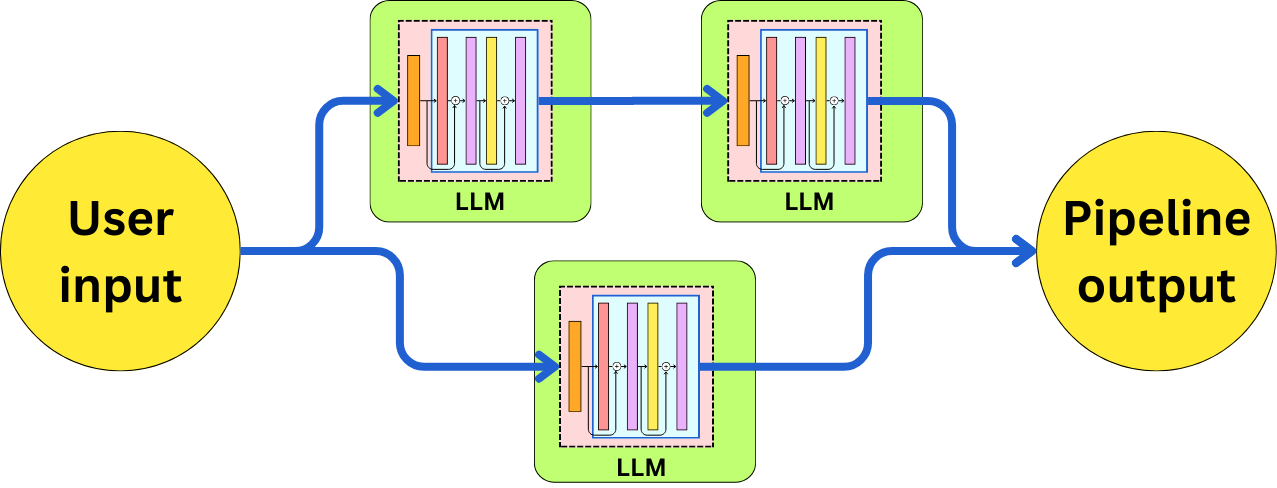
For example, imagine we wanted to implement a pipeline to write a movie review about a comment about a movie. We could imagine that first, we need to extract the movie information from the comment. Let’s do that in AdalFlow:
from adalflow.core import Component, Generator
from adalflow.components.model_client import OpenAIClient
extractor_template = "Extract the movie title and year from: {{ text }}"
class Extractor(Component):
def __init__(self):
super().__init__()
self.doc = Generator(
template=extractor_template,
model_client=OpenAIClient(),
model_kwargs={"model": "gpt-4o-mini"},
)
def call(self, query: str) -> str:
return self.doc(prompt_kwargs={"text": query}).data
extractor = Extractor()
extractor("I watched Oppenheimer last weekend")
> 'The movie title is "Oppenheimer" and it was released in 2023.'And then we could have a call to write a review from the movie information:
reviewer_template = "Write a review for the movie: {{ movie_details }}"
class Reviewer(Component):
def __init__(self):
super().__init__()
self.doc = Generator(
template=reviewer_template,
model_client=OpenAIClient(),
model_kwargs={"model": "gpt-4o-mini"},
)
def call(self, query: str) -> str:
return self.doc(prompt_kwargs={"movie_details": query}).data
reviewer = Reviewer()
reviewer(extracted)
> Title: "Oppenheimer" (2023) - A Cinematic Masterpiece
Rating: ★★★★★ (5/5)
Christopher Nolan’s "Oppenheimer" holds a special place in the realm of biographical dramas, delivering a profound, thought-provoking, and visually stunning depiction of one of history’s most complicated figures, J. Robert Oppenheimer. The film, which chronicles the life and moral dilemmas faced by the father of the atomic bomb, is nothing short of a cinematic tour de force.
From the very first frame, Nolan effortlessly engages the audience in a world riddled with moral ambiguity and ethical questions surrounding scientific advancement. The screenplay, laden with sharp dialogue and rich character development, is crafted with the precision of a well-tuned instrument, echoing the themes of genius and guilt that haunt Oppenheimer throughout his life...Instead of calling two different functions, we may want to combine them into one:
sequence = Sequential(Extractor(), Reviewer())
sequence("I watched Oppenheimer last weekend")
> Title: "Oppenheimer" (2023) - A Cinematic Masterpiece
Rating: ★★★★★ (5/5)
Christopher Nolan’s "Oppenheimer" holds a special place in the realm of biographical dramas, delivering a profound, thought-provoking, and visually stunning depiction of one of history’s most complicated figures, J. Robert Oppenheimer. The film, which chronicles the life and moral dilemmas faced by the father of the atomic bomb, is nothing short of a cinematic tour de force.
From the very first frame, Nolan effortlessly engages the audience in a world riddled with moral ambiguity and ethical questions surrounding scientific advancement. The screenplay, laden with sharp dialogue and rich character development, is crafted with the precision of a well-tuned instrument, echoing the themes of genius and guilt that haunt Oppenheimer throughout his life...The sequence object will behave as if it were any component that takes an input and generates an output.

Here is how we could do the same thing in Haystack:
from haystack import Pipeline
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
# Create components
extractor_prompt = PromptBuilder(template=extractor_template)
reviewer_prompt = PromptBuilder(template=reviewer_template)
extractor = OpenAIGenerator(model="gpt-4o-mini")
reviewer = OpenAIGenerator(model="gpt-4o-mini")
# Build pipeline
pipe = Pipeline()
pipe.add_component("extractor_prompt", extractor_prompt)
pipe.add_component("extractor", extractor)
pipe.add_component("reviewer_prompt", reviewer_prompt)
pipe.add_component("reviewer", reviewer)
# Connect components
pipe.connect("extractor_prompt.prompt", "extractor.prompt")
pipe.connect("extractor.replies", "reviewer_prompt.movie_details")
pipe.connect("reviewer_prompt.prompt", "reviewer.prompt")
# Run pipeline
result = pipe.run({
"extractor_prompt": {
"text": "I watched Oppenheimer last weekend"
}
})
result['reviewer']['replies'][0]
> Title: "Oppenheimer" (2023) - A Cinematic Masterpiece
Rating: ★★★★★ (5/5)
Christopher Nolan’s "Oppenheimer" holds a special place in the realm of biographical dramas, delivering a profound, thought-provoking, and visually stunning depiction of one of history’s most complicated figures, J. Robert Oppenheimer. The film, which chronicles the life and moral dilemmas faced by the father of the atomic bomb, is nothing short of a cinematic tour de force.
From the very first frame, Nolan effortlessly engages the audience in a world riddled with moral ambiguity and ethical questions surrounding scientific advancement. The screenplay, laden with sharp dialogue and rich character development, is crafted with the precision of a well-tuned instrument, echoing the themes of genius and guilt that haunt Oppenheimer throughout his life...In principle, we can write components and compose them to build arbitrarily complex pipelines. For example, let’s assume we want to extract the movie information and we want to write a technical analysis and an artistic analysis:
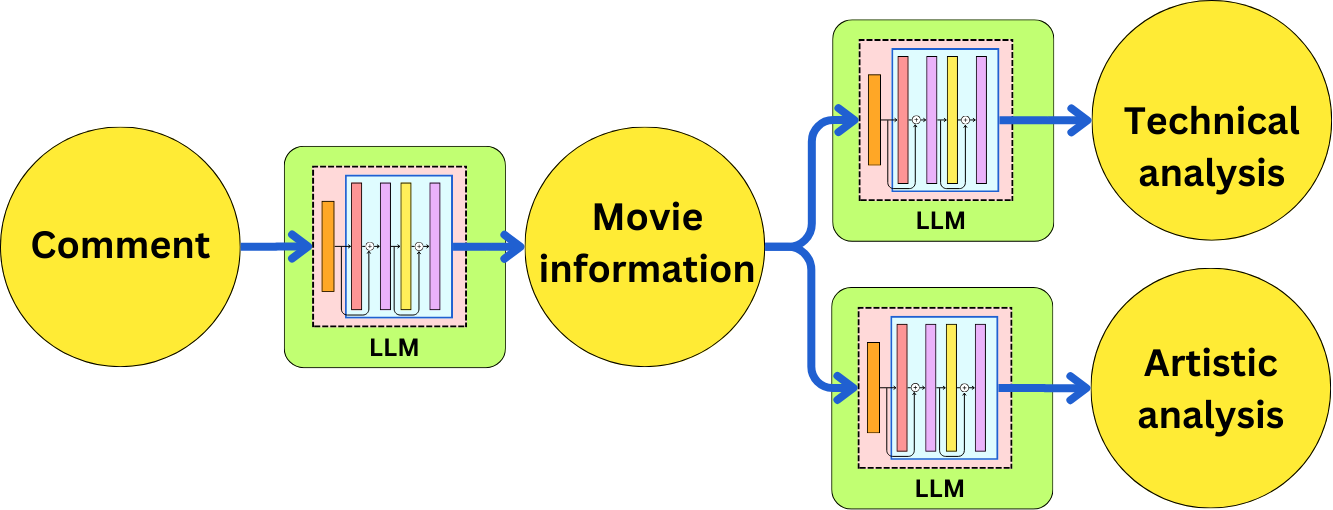
Here is how we could do that in LangChain. Let’s first get the prompts and a data model for the movie information:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
llm = ChatOpenAI(model="gpt-4o-mini")
class MovieInfo(BaseModel):
title: str = Field(description="Movie title")
year: int = Field(description="Release year")
movie_prompt = ChatPromptTemplate.from_template(
"Extract the movie title and year from: {text}"
)
technical_prompt = ChatPromptTemplate.from_template(
"Movie: {title} ({year})\nWrite a technical analysis of the film's production."
)
artistic_prompt = ChatPromptTemplate.from_template(
"Movie: {title} ({year})\nWrite an artistic analysis of the film's themes."
)And then, let’s write the chain to orchestrate the calls:
from langchain_core.runnables import chain
from langchain_core.output_parsers import StrOutputParser
@chain
def movie_chain(inputs):
info_chain = movie_prompt | llm.with_structured_output(MovieInfo)
technical_chain = technical_prompt | llm | StrOutputParser()
artistic_chain = artistic_prompt | llm | StrOutputParser()
movie_info = info_chain.invoke(inputs)
return {
"technical": technical_chain.invoke(movie_info.dict()),
"artistic": artistic_chain.invoke(movie_info.dict())
}
movie_chain.invoke("I watched Oppenheimer last weekend")
> {'technical': "Oppenheimer," directed by Christopher ...,
'artistic': Christopher Nolan's "Oppenheimer" (2023) is a masterful...}This new chain just becomes a component that could be used as a subcomponent of an even bigger chain.
Datastore connections
One of the most important applications supported in micro-orchestration is the Retrieval Augmented Generation (RAG). In fact, LlamaIndex and AdalFlow were originally focused solely on it. The idea is to connect LLMs with different data sources to augment its context when answering user questions. All of those frameworks provide integrations to most vector stores, graph databases, NoSQL, and SQL databases. For example, here is the long list of vector stores supported by Langchain: https://python.langchain.com/docs/integrations/vectorstores/
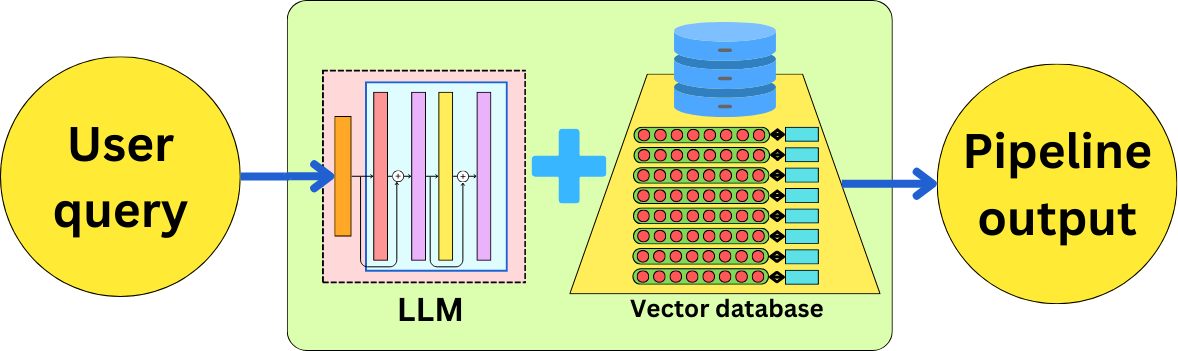
For example, in Haystack, I can integrate an Elasticsearch datastore:
from haystack import Pipeline
from haystack_integrations.components.retrievers.elasticsearch import (
ElasticsearchBM25Retriever
)
from haystack_integrations.document_stores.elasticsearch import (
ElasticsearchDocumentStore
)
document_store = ElasticsearchDocumentStore(
hosts= "http://localhost:9200/"
)
retriever = ElasticsearchBM25Retriever(document_store=document_store)
pipeline = Pipeline()
pipeline.add_component("retriever", retriever)
result = pipeline.run({"retriever": {"query": "Your question"}})We set up a basic search pipeline by creating an Elasticsearch document store connection to a local instance and Initializing a BM25 retriever (a keyword-based search algorithm) connected to that store.
However, I could seemingly replace this Elasticsearch store with a Weaviate store and a different embedding without having to change the way it integrates with the rest of the codebase:
from haystack_integrations.document_stores.weaviate.document_store import WeaviateDocumentStore
from haystack_integrations.components.retrievers.weaviate import WeaviateEmbeddingRetriever
document_store = WeaviateDocumentStore(url="http://localhost:8080")
retriever = WeaviateEmbeddingRetriever(document_store=document_store)
pipeline = Pipeline()
pipeline.add_component("retriever", retriever)
result = pipeline.run({"retriever": {"query": "Your question"}})The pipeline becomes independent of the specific implementation of the data store, and we can focus on architecting the pipeline instead of the integration. It is often comfortable to not have to learn the specific data store API to integrate it
For example, here is how we can integrate a Neo4j graph database into an RAG pipeline in LlamaIndex:
from llama_index.graph_stores.neo4j import Neo4jPropertyGraphStore
from llama_index.core import PropertyGraphIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
graph_store = Neo4jPropertyGraphStore(
username="neo4j",
password="llamaindex",
url="bolt://localhost:7687",
)
index = PropertyGraphIndex(
llm=OpenAI(model="gpt-4o-mini"),
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
property_graph_store=graph_store,
)
query_engine = index.as_query_engine(include_text=True)
response = query_engine.query("What is this data about?")Note that we didn’t have to write any Neo4j cypher query to retrieve the data and pass it to an LLM.
Another very critical application of database connectivity is the ability to capture the history of a chatbot conversation. We cannot implement a chatbot without providing as context the previous messages of the conversation. For example, here is how we can capture the conversation history in a PostgreSQL database in LangChain:
from langchain_community.chat_message_histories import (
PostgresChatMessageHistory,
)
url = "postgresql://postgres:mypassword@localhost/chat_history"
history = PostgresChatMessageHistory(
connection_string=url,
session_id=str(uuid.uuid4()),
)
history.add_user_message("hi!")
history.add_ai_message("whats up?")And we can easily retrieve them for context:
history.messages Integration of external tools or APIs at a task-specific level
Besides data stores, we may want to augment LLMs with tools. This is usually the most basic use case for LLM-based agents. We feed into the prompts the information on what tools are available, what syntax we need to use to interact with the tools, and what output we expect from them.
Most of those frameworks have integrations with many different tools. Check out LangChain’s list of tools: https://python.langchain.com/docs/integrations/tools/
I am going to prepare three tools in LangChain: Wolfram Alpha, Google Search, and Wikipedia. Here is how I can get the LLM to tell me which tool I should use based on the query
from langchain_community.utilities import (
WolframAlphaAPIWrapper,
WikipediaAPIWrapper,
)
from langchain_google_community import GoogleSearchAPIWrapper
from langchain_community.tools import (
WikipediaQueryRun,
WolframAlphaQueryRun,
)
from langchain_core.tools import Tool
from langchain_openai import ChatOpenAI
search = GoogleSearchAPIWrapper()
wolfram = WolframAlphaQueryRun(api_wrapper=WolframAlphaAPIWrapper())
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
tools = [
wikipedia,
wolfram,
Tool(
name="google_search",
description="Search Google for recent results.",
func=search.run,
)
]
llm = ChatOpenAI(model="gpt-4o-mini")
llm_with_tools = llm.bind_tools(tools)
response = llm_with_tools.invoke("What is the latest version of Langchain?")
response.tool_calls
> [{'name': 'google_search',
'args': {'__arg1': 'latest version of Langchain'},
'id': 'call_MGyRE3fKK9K38g55wahq8k4G',
'type': 'tool_call'}]Here, we just provided the LLM the way to query those tools, and it responds with its choice for the query. The content is empty and it suggests to use Google Search with the argument “latest version of Langchain“.
Of course, we can go a bit further and use the more autonomous (agentic) function to directly execute the tool commands. For example, here is how we do that in LlamaIndex by using a ReAct agent:
from llama_index.tools.google import GoogleSearchToolSpec
from llama_index.tools.wolfram_alpha import WolframAlphaToolSpec
from llama_index.tools.wikipedia import WikipediaToolSpec
from llama_index.core.agent import ReActAgent
from llama_index.llms.openai import OpenAI
search = GoogleSearchToolSpec().to_tool_list()
wolfram = WolframAlphaToolSpec().to_tool_list()
wikipedia = WikipediaToolSpec().to_tool_list()
llm = OpenAI(model="gpt-4o-mini")
agent = ReActAgent.from_tools(
tools=search + wolfram + wikipedia,
llm=llm,
)
agent.query("What is the latest version of Langchain?")
# query google search
> Response(response='The latest version of Langchain is 0.3.7, released on November 1.', source_nodes=[], metadata=None)Tracing and Logging
When you are building an LLM pipeline, a lot of the data flowing around will be model input and output, including prompts, warnings, and error traces, and it becomes important to capture that data for debugging, evaluation, or optimization purposes. LangChain, LlamIndex, and Haystack invested quite a bit of effort in making sure they provided production-grade applications that could be monitored effectively.
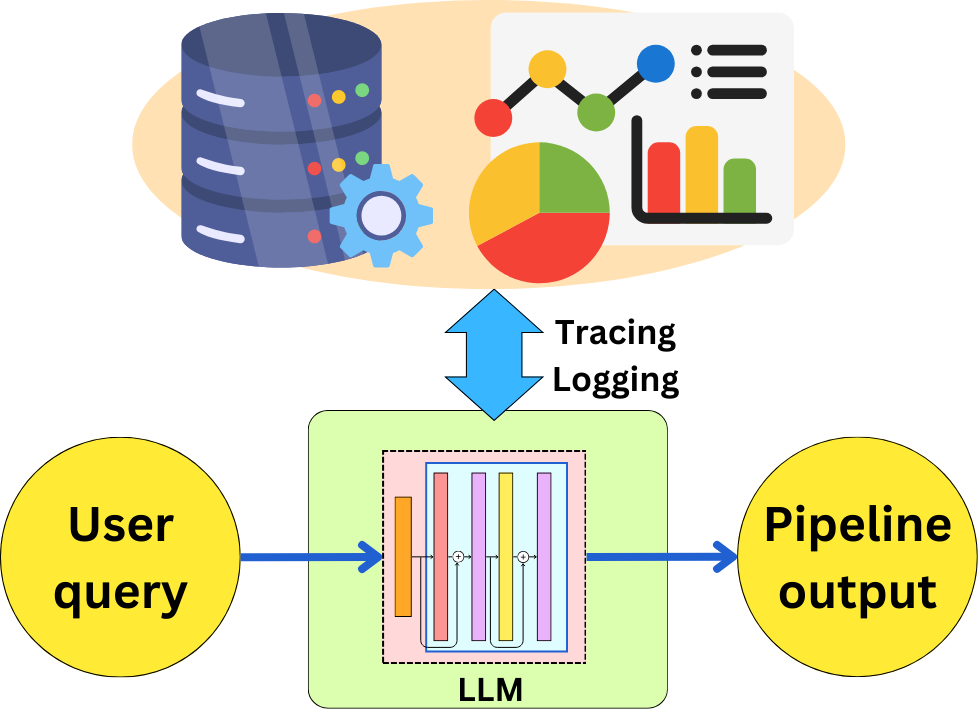
LlamaIndex and Haystack proposed a few integrations with third-party monitoring tools. As an example, let’s build a basic RAG pipeline in Haystack and integrate it with LangFuse. As a retriever, let’s get an in-memory datastore:
from haystack.document_stores.in_memory import InMemoryDocumentStore
document_store = InMemoryDocumentStore()Let’s load a simple dataset into it:
from datasets import load_dataset
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack.components.retrievers import InMemoryEmbeddingRetriever
dataset = load_dataset("bilgeyucel/seven-wonders", split="train")
embedder = SentenceTransformersDocumentEmbedder(
"sentence-transformers/all-MiniLM-L6-v2"
)
embedder.warm_up()
docs_with_embeddings = embedder.run([
Document(**ds) for ds in dataset]
).get("documents")
document_store.write_documents(docs_with_embeddings)
retriever = InMemoryEmbeddingRetriever(
document_store=document_store, top_k=2
)Let’s now add this retriever to a pipeline:
from haystack import Pipeline
basic_rag_pipeline = Pipeline()
basic_rag_pipeline.add_component("retriever", retriever)Now we need a generator. For the generator, we first need an embedder to convert the text into an embedding:
from haystack.components.embedders import SentenceTransformersTextEmbedder
basic_rag_pipeline.add_component(
"text_embedder",
SentenceTransformersTextEmbedder(
model="sentence-transformers/all-MiniLM-L6-v2"
)
)Then we need a prompt and an LLM:
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
template = """
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
prompt_builder = PromptBuilder(template=template)
basic_rag_pipeline.add_component("prompt_builder", prompt_builder)
basic_rag_pipeline.add_component("llm",
OpenAIGenerator(model="gpt-4o-mini", generation_kwargs={"n": 2})
)Let’s connect the different components of the pipeline:
The output of the text embedder is used as input to the retriever
The output of the retriever is used as input to the prompt
The final prompt is used as input to the LLM
basic_rag_pipeline.connect(
"text_embedder.embedding", "retriever.query_embedding"
)
basic_rag_pipeline.connect("retriever", "prompt_builder.documents")
basic_rag_pipeline.connect("prompt_builder", "llm")Finally, let’s add the tracer:
from haystack_integrations.components.connectors.langfuse import (
LangfuseConnector
)
basic_rag_pipeline.add_component(
"tracer", LangfuseConnector("Basic RAG Pipeline")
)We can visualize that pipeline:
pipeline.draw(path="pipeline.png")
Now, we can ask a question:
question = "What does Rhodes Statue look like?"
response = basic_rag_pipeline.run({
"text_embedder": {"text": question},
"prompt_builder": {"question": question}}
)After logging in to the LangFuse dashboard and passing the API keys:
import os
os.environ["LANGFUSE_SECRET_KEY"] = ...
os.environ["LANGFUSE_PUBLIC_KEY"] = ...
os.environ["HAYSTACK_CONTENT_TRACING_ENABLED"] = "true"We can monitor the activities related to the app:
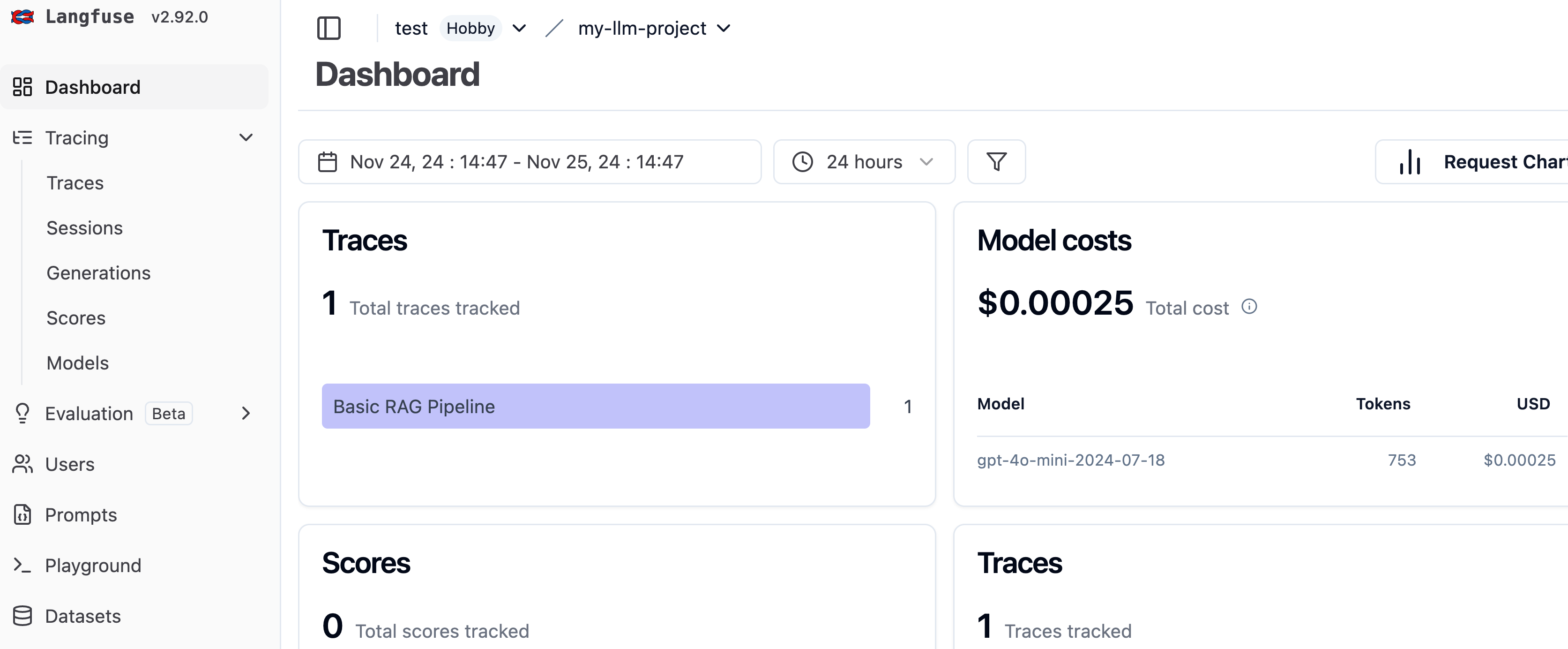
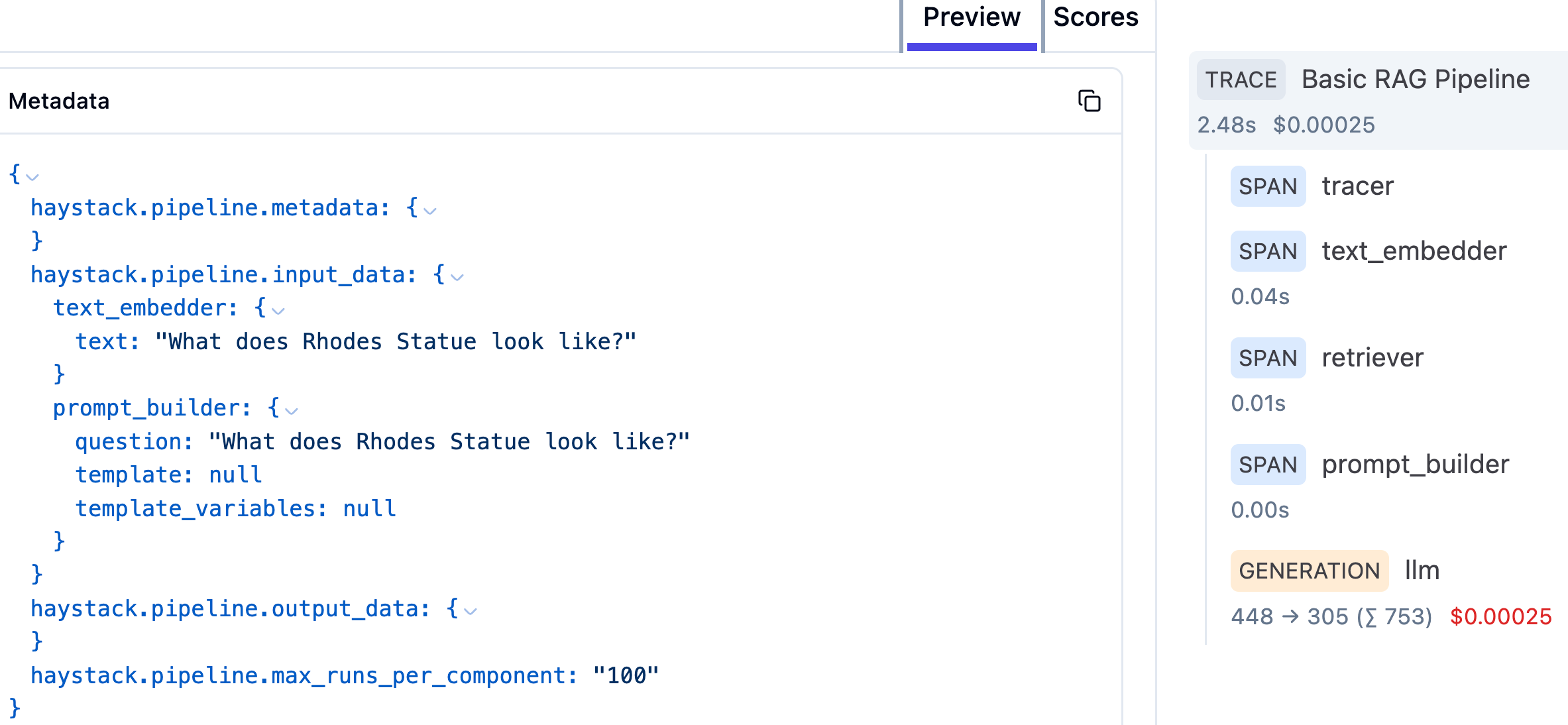
For example, we can see the metadata related to the question and the cost associated with it:
LangChain, on the other hand, implemented its own solution, LangSmith, and it is quite easy to integrate it with LangChain. To integrate it into my code, I just need to sign in to the langSmith website, get my API key, set up my environment variables,
import os
os.environ["LANGCHAIN_API_KEY"] = ...
os.environ["LANGCHAIN_PROJECT"] = "test-project"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"and execute a pipeline as usual:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
llm.invoke("Hello, world!")And the traces are available in the LangSmith dashboard:
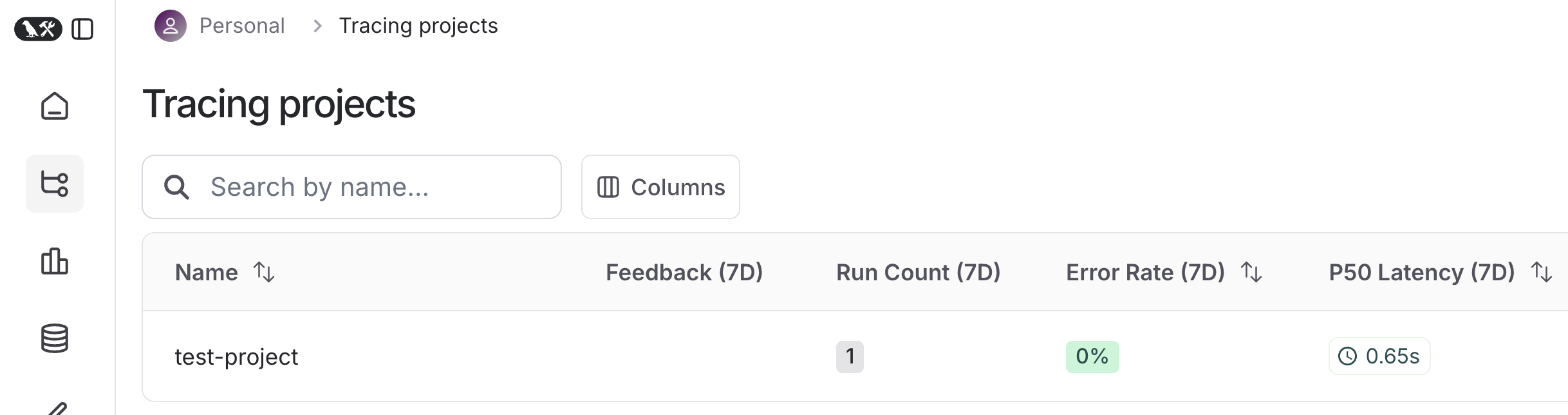
And I can easily visualize what was executed:
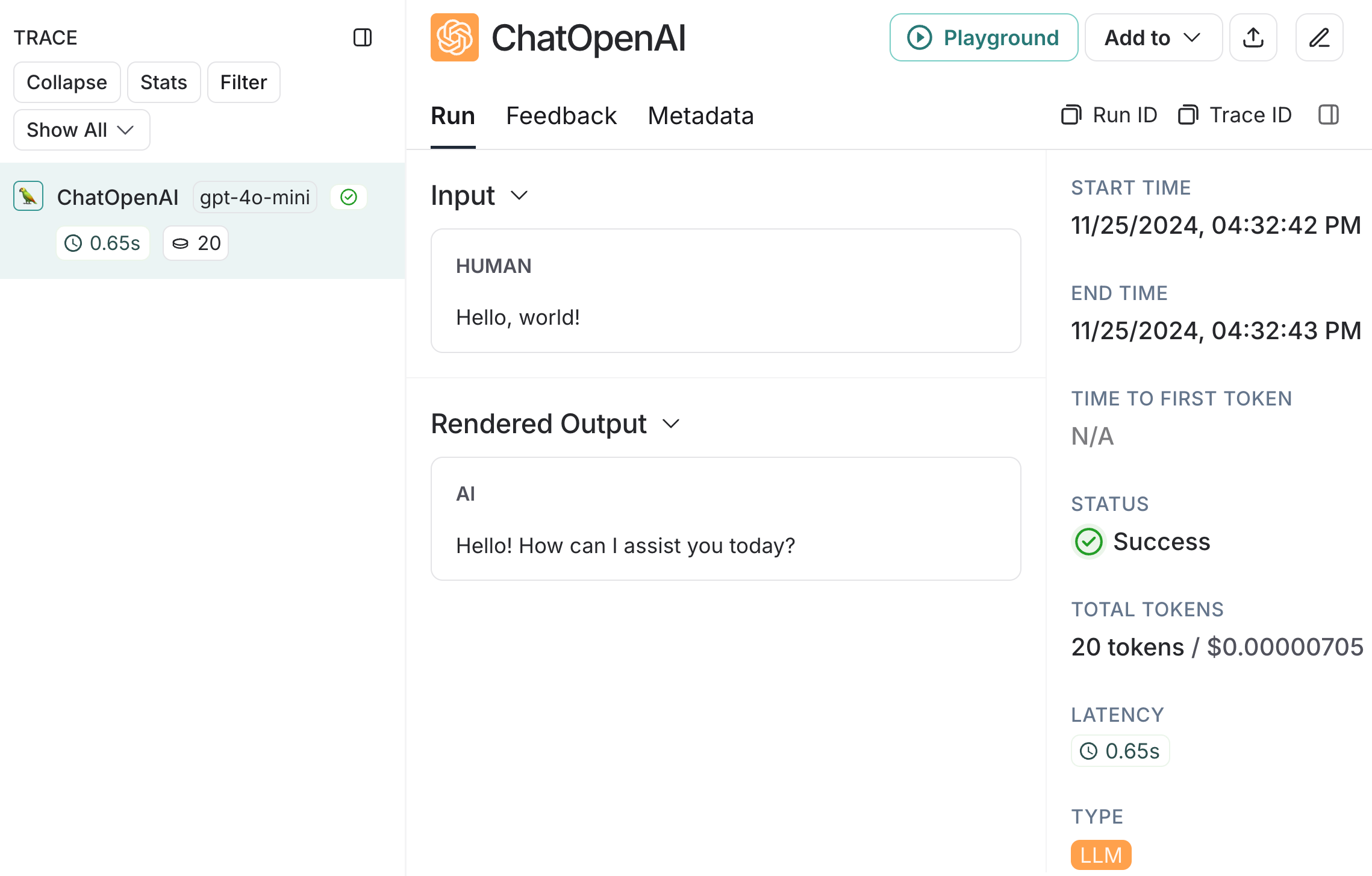
LangSmith is not LangChain specific and can be integrated with other frameworks.
Macro-Orchestration
Macro-orchestration in LLM pipelines involves the high-level design, coordination, and management of complex workflows that may incorporate multiple LLM interactions, as well as other AI and non-AI components. It focuses on the overall structure and flow of larger systems or applications. It involves things like:
Workflow design and management
State management across multiple steps or processes
Parallel processing and distributed computation
Error handling and recovery at a system level
Scalability and performance optimization of the entire pipeline
Integration of diverse AI services and traditional software components
Example operations: Multi-agent systems, long-running tasks with multiple stages, complex decision trees involving multiple LLM and non-LLM components.
In my opinion, this is the most important type of orchestration to understand for LLM pipelines. LangGraph and Haystack seem to be the most mature on that front. LangGraph is from the same company as LangChain but can work independently from it. LangChain tried to implement a simpler way to orchestrate pipelines with the LangChain Expression Language (LCEL), but it ended up being a mess! LangGraph was a way to correct that. Haystack, from the start, implemented everything with a more graphical approach to orchestration, like Frameworks such as AirFlow or KubeFlow, seemingly mixing micro-orchestration and macro-orchestration.
LlamaIndex implemented Workflows, which is also an elegant approach to that higher-level orchestration. Burr by Dagworks and GenWorlds are also interesting actors in the space, with GenWorlds having a stronger focus on Agents.
Complex Graphical Applications
One of the most important aspects is to provide a high-level process to orchestrate complex applications. Here, we represent the applications as a set of nodes where the different operations happen and edges that connect those operations.
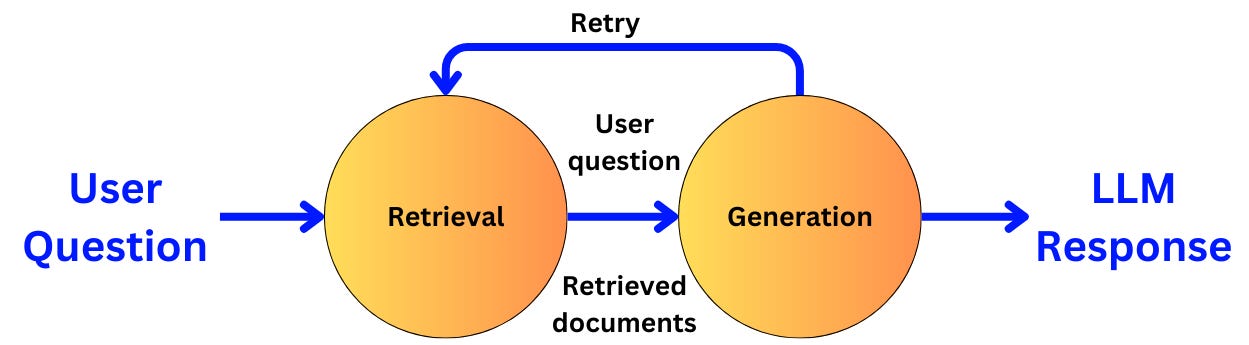
For example, in the context of RAG, we can decompose the operations into the retrieval piece and the generation piece:
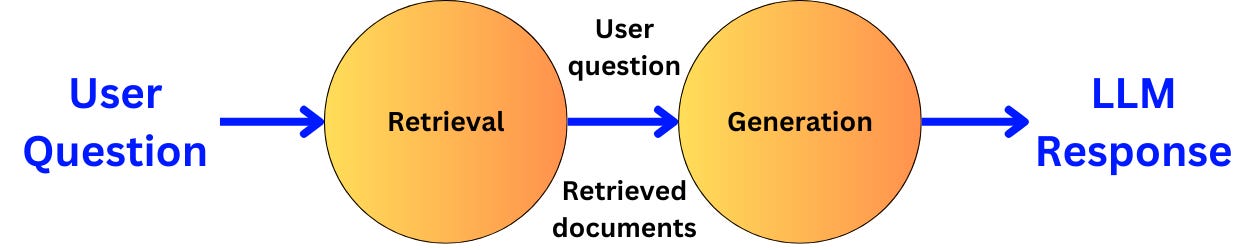
We have two operations:
The retrieval operation takes a user query and returns related documents
The generation operation takes the user query and related documents and returns an answer to the query.
The two nodes are connected by an edge that represents the causality between the two operations and the data that needs to flow from one node to the next. We have actually already implemented a similar RAG pipeline with Haystack above in the context of tracing and logging. Let’s implement a similar basic RAG pipeline with LangGraph and LangChain. First, let’s get the generation prompt:
from langchain_core.prompts import ChatPromptTemplate
system_prompt = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Only provide the answer and nothing else!
"""
human_prompt = """
Question: {question}
Context:
{context}
Answer:
"""
rag_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)Now, let’s bind this prompt to an LLM and parse the output as a string:
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
llm_engine = ChatOpenAI(model='gpt-4o-mini')
rag_chain = rag_prompt | llm_engine | StrOutputParser()We are going to establish the application state where we are going to store the different global variables like the user query, the retrieved documents, and the generated answer:
from pydantic import BaseModel
class GraphState(BaseModel):
question: Optional[str] = None
generation: Optional[str] = None
documents: List[str] = [] Let’s assume we have a retriever we use to query from the user query and implement the first node in the graph:
from data_index import retriever
def retriever_node(state: GraphState):
new_documents = retriever.invoke(state.question)
new_documents = [d.page_content for d in new_documents]
state.documents.extend(new_documents)
return {"documents": state.documents}We implement the second node where we implement the generation piece:
def generation_node(state: GraphState):
generation = rag_chain.invoke({
"context": "\n\n".join(state.documents),
"question": state.question,
})
return {"generation": generation}Now we can add the nodes to the graph:
from langgraph.graph import END, StateGraph, START
pipeline = StateGraph(GraphState)
pipeline.add_node('retrieval_node', retriever_node)
pipeline.add_node('generator_node', generation_node)Let’s connect the different nodes:
# We start by the retrieval
pipeline.add_edge(START, 'retrieval_node')
# We continue to the generation node
pipeline.add_edge('retrieval_node', 'generator_node')
# Once we generated the text, we end the pipeline
pipeline.add_edge('generator_node', END)
rag_pipeline = pipeline.compile()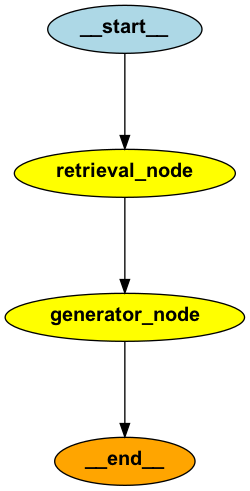
The pipeline is ready to be run:
inputs = {"question": "What is LangChain?"}
for output in rag_pipeline.stream(inputs, stream_mode='updates'):
for key in output.keys():
print(f"Node: {key}")
> Node: retrieval
Node: generator
LangChain is a framework designed for developing applications powered by large language models (LLMs). It simplifies the entire application lifecycle, including development, productionization, and deployment, through a set of open-source libraries and tools. Key components of LangChain include model I/O, retrieval strategies, and agents, enabling the creation of context-aware reasoning applications.For each operation, we abstract away the complexity behind a node and how the data flows in and out of that node. This approach allows us to build ridiculously complex applications by focusing on a node at a time every time we increase the complexity. Check out this newsletter, where I increase the complexity of an RAG pipeline little by little:

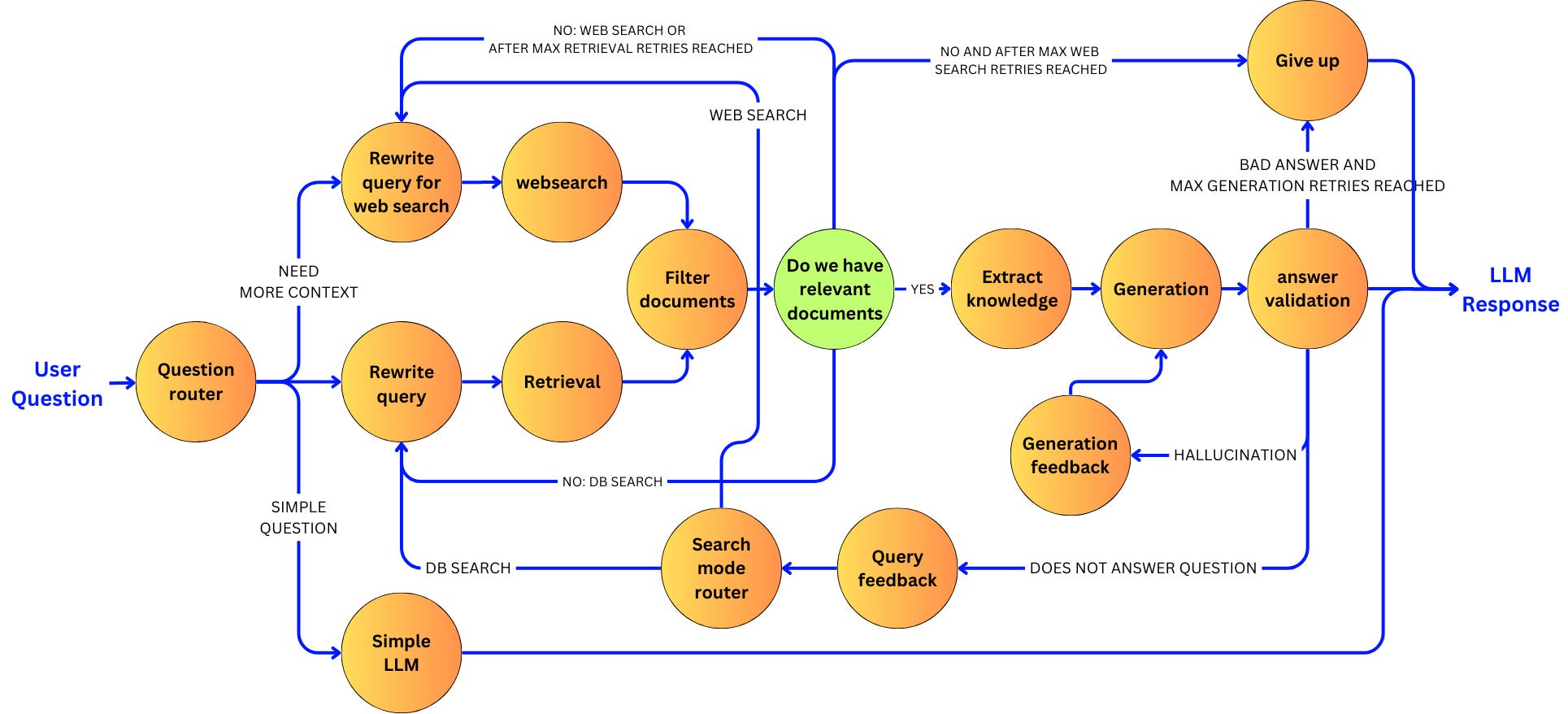
Every step of the way, every time I wanted to improve upon the current version of the pipeline, I just needed to focus on a couple of nodes. As the pipeline grows, the complexity of implementing a new feature doesn’t. This graphical approach allows me to scale the complexity of my pipeline in a robust manner without being drowned in an ocean of “if” statements to keep track of the different use cases that need to be handled.
We can grow even more complex applications by abstracting a whole graph as a node for a supergraph. This is thought to be for extremely large-scale pipelines!
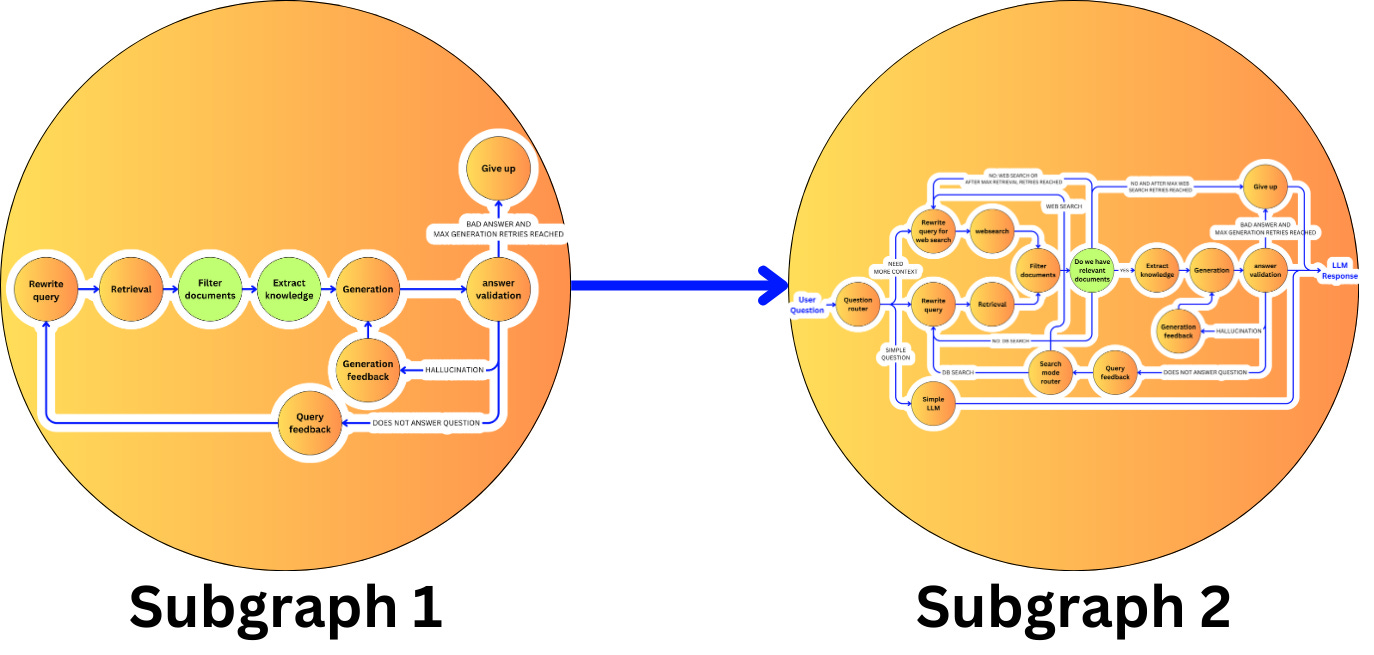
Here is the pseudo-code to achieve this in LangGraph:
subgraph_builder1 = StateGraph(SubgraphState1)
...
subgraph1 = subgraph_builder1.compile()
subgraph_builder2 = StateGraph(SubgraphState2)
...
subgraph2 = subgraph_builder2.compile()
builder = StateGraph(ParentState)
builder.add_node("node1", subgraph1)
builder.add_node("node2", subgraph2)
builder.add_edge(START, "node1")
builder.add_edge("node1", "node2")
builder.add_edge("node2", END)
graph = builder.compile()LlamaIndex Workflows have a similar approach, but the different edges are called “events” and the nodes “steps“. Let’s implement another basic RAG pipeline. An event class is going to carry the necessary information from the retrieval step to the generation step:
from llama_index.core.workflow import Event
class ContextEvent(Event):
query: str
retrieved: List[str]A workflow is the equivalent of a graph in LangGraph. We are going to give it an LLM and a fake retriever:
from llama_index.core.workflow import Workflow
class RAGPipeline(Workflow):
llm = OpenAI()
retriever = lambda query: ['test']We pass it the retrieval step:
from llama_index.core.workflow import StartEvent, step
class RAGPipeline(Workflow):
llm = OpenAI()
retriever = lambda query: ['test']
@step
async def retrieval_step(self, ev: StartEvent) -> ContextEvent:
query = ev.query
data = self.retriever(query)
return ContextEvent(query=query, retrieved=data)The StartEvent is a special event indicating the beginning of a flow. From the query, we get the retrieved data from the retriever, and we return a ContextEvent. let’s get the generation step:
from llama_index.core.workflow import StopEvent
class RAGPipeline(Workflow):
llm = OpenAI()
retriever = lambda query: ['test']
...
@step
async def generation_step(self, ev: ContextEvent) -> StopEvent:
query = ev.query
retrieved = ev.retrieved
prompt = f"""Given the following information, answer the question.
Context: {'\n\n'.join(retrieved)}
Question: {query}
"""
response = await self.llm.acomplete(prompt)
return StopEvent(result=str(response))Because the generation step takes a ContextEvent attributes, it automatically gathers the information returned by the retrieval step, and we don’t need to link the two steps explicitly. The edges are inferred from the class signature. We can run the pipeline as follows:
rag_pipeline = RAGPipeline(timeout=60, verbose=False)
result = await rag_pipeline.run(query="What are LlamaIndex Worflows")Something different from the way LangGraph handles things is the way local information and global information are treated differently. We have Events and Context:
from llama_index.core.workflow import StartEvent, step, Context
class RAGPipeline(Workflow):
@step
async def retrieval_step(
self, ctx: Context ev: StartEvent) -> ContextEvent:
# retrieve from context
query = await ctx.get("query")
data = self.retriever(query)
return ContextEvent(query=query, retrieved=data)The context is a global state that can be shared across steps, where an event only passes local information from step to step. This is helpful when the application becomes complex. In LangGraph, we have to add different attributes to the graph state as we grow the application, and this can quickly become unmanageable. On the other hand, we have to create a distinct event class for each edge in the graph, which can somewhat pollute the codebase with unnecessary lines of code.
Because Events are edges, we can directly create conditional connections from the step, which can help with the readability of the code. For example, we can decide on different paths depending on the value of the query:
class RAGPipeline(Workflow):
@step
async def retrieval_step(
self, ctx: Context ev: StartEvent) -> ContextEvent:
query = await ctx.get("query")
if not query:
return StopEvent
data = self.retriever(query)
return ContextEvent(query=query, retrieved=data)The steps can receive different types of events, allowing for conditionality using different input data. For example, imagine we have a retrial loop to restart the retrieval step:
class RAGPipeline(Workflow):
@step
async def retrieval_step(
self, ev: StartEvent | RetrialEvent) -> ContextEvent:
query = ev.query
retrieved = []
if isinstance(ev, RetrialEvent):
retrieved = ev.retrieved
retrieved.extend(self.retriever(query))
return ContextEvent(query=query, retrieved=retrieved)Stateful Application
A huge advantage of a stateful application is the ability to checkpoint a current state and recover and replay a previous one. For example, a chatbot is inherently stateful as we need to recover the history of a conversation, and for each user, it might be useful to save the current state of the pipeline execution. Execution replays allow for debugging or state recovery for better user experience in case a bug happens further down the pipeline.
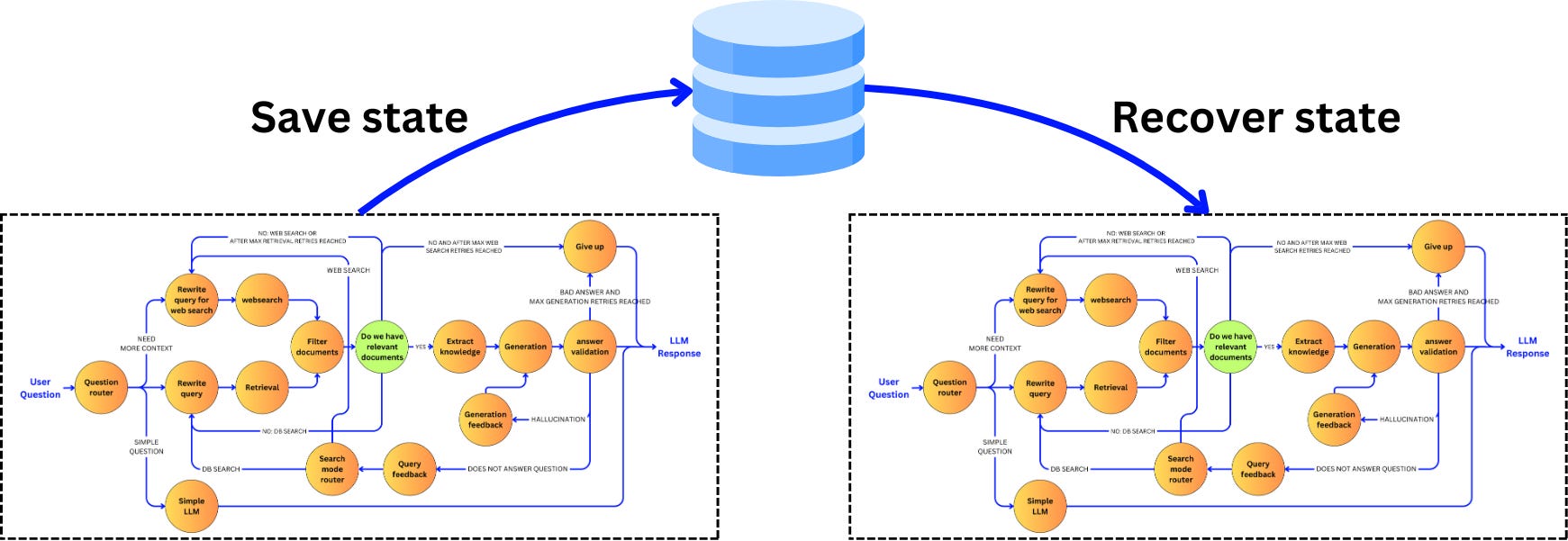
For example, let's persist states in a Postgres database with LangGraph. Let’s first establish a basic RAG pipeline:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from pydantic import BaseModel
from langgraph.graph import END, StateGraph, START
system_prompt = """
You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
"""
human_prompt = "Question: {question} \n\nContext: \n{context} \n\nAnswer:"
rag_prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("human", human_prompt)]
)
class GraphState(BaseModel):
question: Optional[str] = None
generation: Optional[str] = None
documents: List[str] = []
retriever = lambda query: ['test']
llm_engine = ChatOpenAI(model='gpt-4o-mini')
rag_chain = rag_prompt | llm_engine | StrOutputParser()
def retriever_node(state: GraphState):
new_documents = retriever(state.question)
state.documents.extend(new_documents)
return {"documents": state.documents}
def generation_node(state: GraphState):
generation = rag_chain.invoke({
"context": "\n\n".join(state.documents),
"question": state.question,
})
return {"generation": generation}
pipeline = StateGraph(GraphState)
pipeline.add_node('retrieval_node', retriever_node)
pipeline.add_node('generator_node', generation_node)
pipeline.add_edge(START, 'retrieval_node')
pipeline.add_edge('retrieval_node', 'generator_node')
pipeline.add_edge('generator_node', END)Now, let’s connect the Postgres database to the graph when compiling it:
from langgraph.checkpoint.postgres import PostgresSaver
from psycopg import Connection
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
conn = Connection.connect(DB_URI, **connection_kwargs)
checkpointer = PostgresSaver(conn)
checkpointer.setup()
rag_pipeline = pipeline.compile(checkpointer=checkpointer)Let’s say we have a user with ID user_id_1 who asks a first question:
config = {"configurable": {"thread_id": "user_id_1"}}
inputs = {"question": "First question"}
output = rag_pipeline.invoke(inputs, config)
> {'question': 'First question',
'generation': "I don't know.",
'documents': ['test']}Then it asks a second question:
config = {"configurable": {"thread_id": "user_id_1"}}
inputs = {"question": "Second question"}
output = rag_pipeline.invoke(inputs, config)
> {'question': 'Second question',
'generation': "I don't know.",
'documents': ['test', 'test']}We can now see the history of states for that particular user:
for state in rag_pipeline.get_state_history(config):
print(state)
print("--")
> StateSnapshot(values={'question': 'Second question', 'generation': "I don't know.", 'documents': ['test', 'test']}, next=(), config={'configurable': {'thread_id': 'user_id_1', 'checkpoint_ns': '', 'checkpoint_id': '1efad132-efbe-6fa2-8006-de4ad59bd69d'}}, metadata={'step': 6, 'source': 'loop', 'writes': {'generator_node': {'generation': "I don't know."}}, 'parents': {}, 'thread_id': 'user_id_1'}, created_at='2024-11-27T22:58:57.602089+00:00', parent_config={'configurable': {'thread_id': 'user_id_1', 'checkpoint_ns': '', 'checkpoint_id': '1efad132-eb9b-6bb4-8005-15b0f2cea5ae'}}, tasks=())
--
StateSnapshot(values={'question': 'Second question', 'generation': "I don't know.", 'documents': ['test', 'test']}, next=('generator_node',), config={'configurable': {'thread_id': 'user_id_1', 'checkpoint_ns': '', 'checkpoint_id': '1efad132-eb9b-6bb4-8005-15b0f2cea5ae'}}, metadata={'step': 5, 'source': 'loop', 'writes': {'retrieval_node': {'documents': ['test', 'test']}}, 'parents': {}, 'thread_id': 'user_id_1'}, created_at='2024-11-27T22:58:57.168263+00:00', parent_config={'configurable': {'thread_id': 'user_id_1', 'checkpoint_ns': '', 'checkpoint_id': '1efad132-eb99-6724-8004-f44def5dc32e'}}, tasks=(PregelTask(id='a51a63c5-df2a-9788-e1fb-b0e0e9a661ef', name='generator_node', path=('__pregel_pull', 'generator_node'), error=None, interrupts=(), state=None, result={'generation': "I don't know."}),))
--
...If I look at the history for another user, it is empty:
config = {"configurable": {"thread_id": "user_id_2"}}
for state in rag_pipeline.get_state_history(config):
print(state)
print("--")
> NoneAnd we can update the current state of the graph for that user:
branch_config = rag_pipeline.update_state(
previous_state.config,
{"question": "Better first question"}
)
branch_config
> {'configurable': {'thread_id': 'user_id_1',
'checkpoint_ns': '',
'checkpoint_id': '1efad13f-a1f8-6af4-8001-b99c45cb6990'}}And continue to execute from that branch:
inputs = {"question": "Second question"}
output = rag_pipeline.invoke(inputs, branch_config)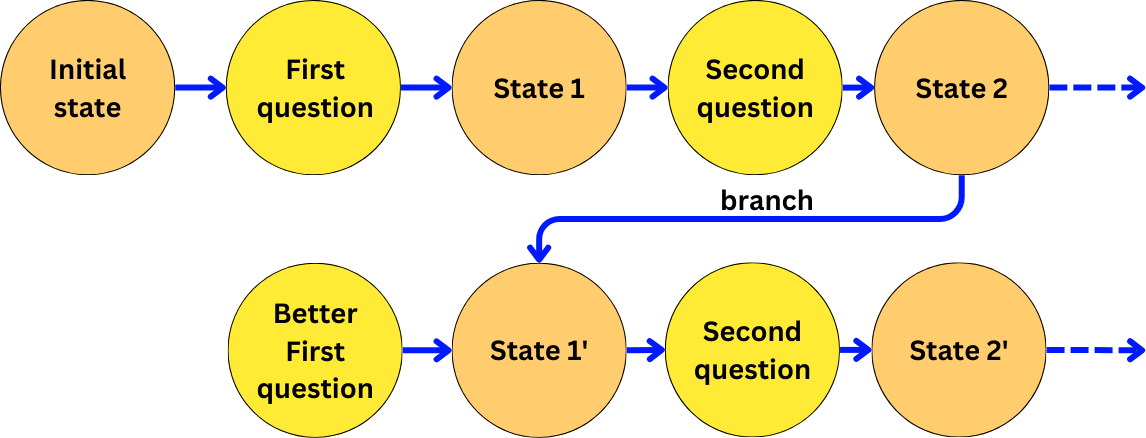
LlamaIndex provides a utility for checkpointing, but it is not clear how we can persist the states to a database:
from llama_index.core.workflow import WorkflowCheckpointer
rag_pipeline = RAGPipeline()
checkpointer = WorkflowCheckpointer(workflow=rag_pipeline)
# to checkpoint a run, use the `run` method from checkpointer
handler = checkpointer.run(query="First question")
await handler
# to view the stored checkpoints of this run
checkpointer.checkpoints[handler.run_id]
# to run from one of the checkpoints, use `run_from` method
checkpoint = checkpointer.checkpoints[handler.run_id][0]
handler = checkpointer.run_from(query="Better first question")
await handlerAgentic Design
Those macro-orchestration frameworks offer a lot of advantages for agentic design. An LLM-based agent is a system that uses LLM to make decisions on the flow of the application. To an extent, most LLM orchestration frameworks provide some solutions around the agentic design. The graph structure of those stateful frameworks allows to impose a lot of control on the behavior of the agents. Agentic design can easily output garbage if they are not well implemented, so control is critical!
Frameworks like LangGraph can provide robust control, whereas a framework like Autogen might be too autonomous to implement production-level software.

As an example, let’s implement a router in Langgraph. Imagine we have a RAG system with user queries. Instead of sending all the questions to a vector store, we are going to route the query based on its difficulty. Let’s get a Langchain chain for doing that:
from pydantic import BaseModel, Field
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
class RouteQuery(BaseModel):
route: Literal["vectorstore", "websearch", "QA_LM"] = Field(
description="Given a user question choose to route it to web search (websearch), a vectorstore (vectorstore), or a QA language model (QA_LM).",
)
system_prompt = """
You are an expert at routing a user question to a vectorstore, a websearch or a simple QA language model.
The vectorstore contains documents related to Langchain.
If you can answer the question without any additional context or if a websearch could not provide additional context, route it to the QA language model.
If you need additional context and it is a question about Langchain, use the vectorstore, otherwise, use websearch.
"""
router_prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("human", "{question}")]
)
router = router_prompt | llm_engine.with_structured_output(RouteQuery)Now, let’s define the node:
def router_node(state: GraphState):
route_query = question_router.invoke(state.question)
return route_query.routeFinally, we can build the graph where we are going to take different routes depending on the LLM’s choice:
pipeline = StateGraph(GraphState)
pipeline.add_conditional_edges(
START,
router_node,
{
"vectorstore": 'db_query_rewrite_node',
"websearch": 'websearch_query_rewriting_node',
"QA_LM": 'simple_question_node'
},
)The conditional_edges allow for different flows depending on the value provided by the router node.
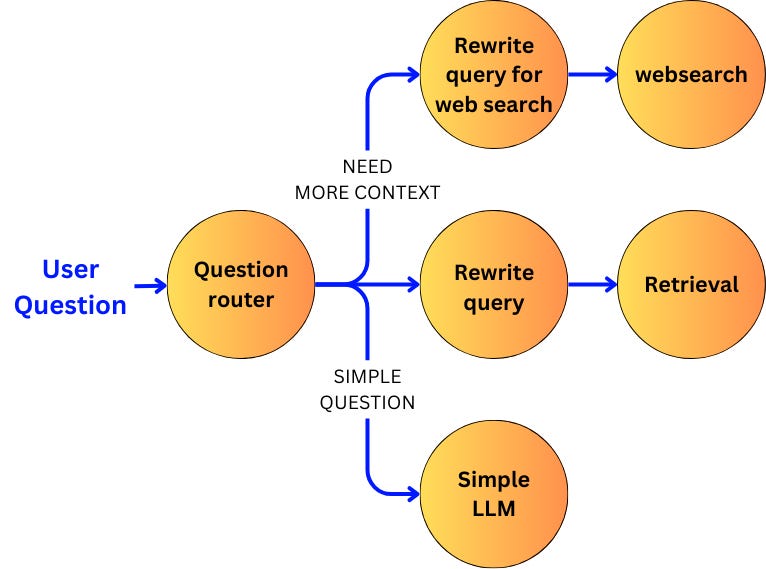
This is a basic decision taken by the LLM with a low level of risk.
Implementing a working design for agents can be tough, that is why there a few tricks to follow. When we build software involving LLMs, we want to avoid use cases where LLMs are not performing well and utilize their capabilities on tasks they are known to be good at! When we think about agentic design, we need to think about a combination of multiple LLM actors with limited agency and human domain expertise to architect the way agents interact alongside software that is going to impose a rigid structure between the different agent interactions. In the following newsletter, I output some of the main patterns for agentic design:

The way agents interact needs to be simple to be able to convey the information to agents in a less confusing manner. Those are typical ways agents could interact:
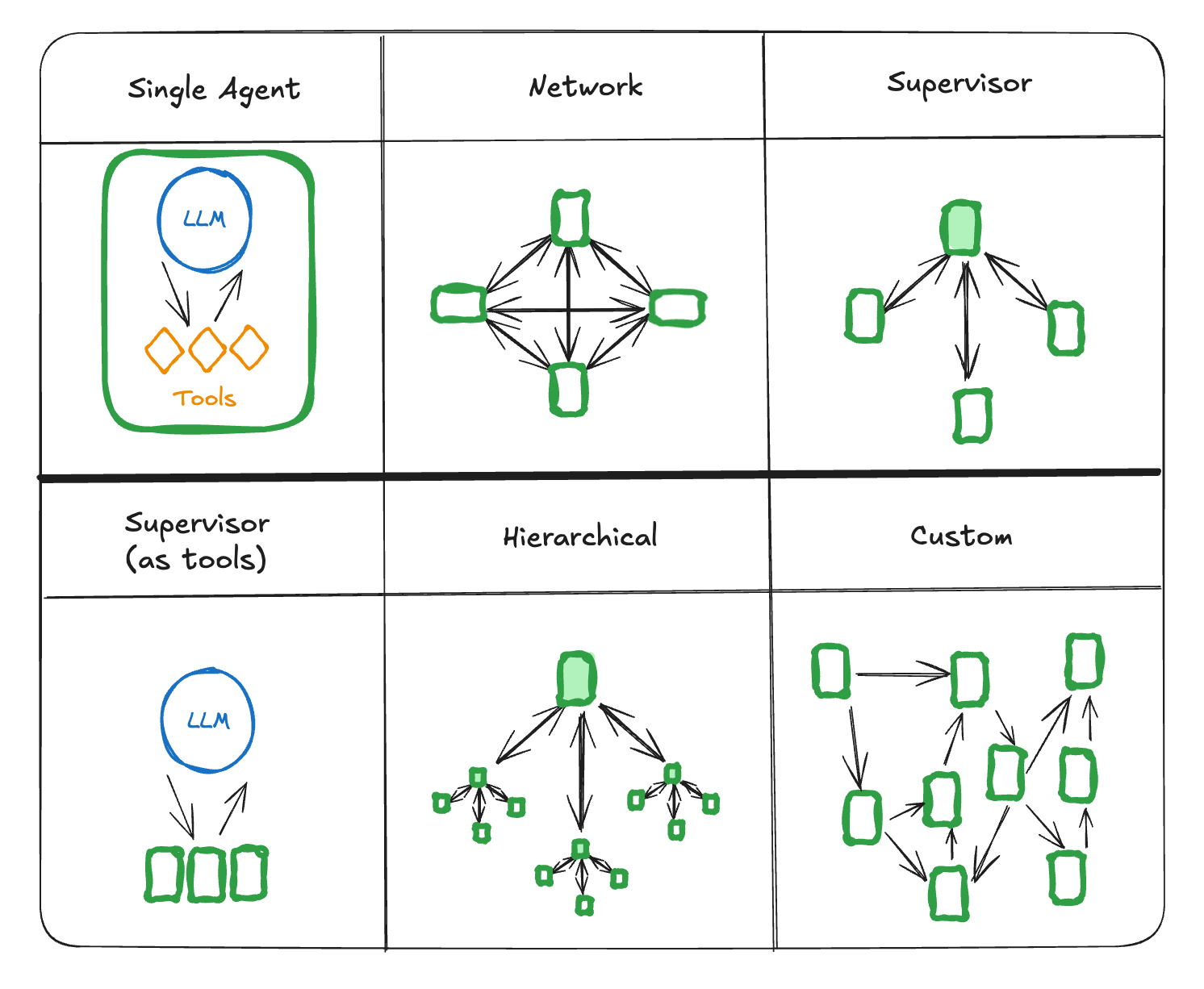
For example, let’s implement a supervisor pattern in LangGraph. Let’s have a supervisor that assigns tasks and reviews the results. We have subordinates:
Researcher: Gathers and synthesizes information from the knowledge base using retrieval tools and provides well-cited findings.
Analyst: Processes the gathered information to identify patterns, trends, and key insights from the researcher's findings.
Writer: Creates polished, coherent content by transforming the analyst's insights and researcher's data into well-structured reports or documents.
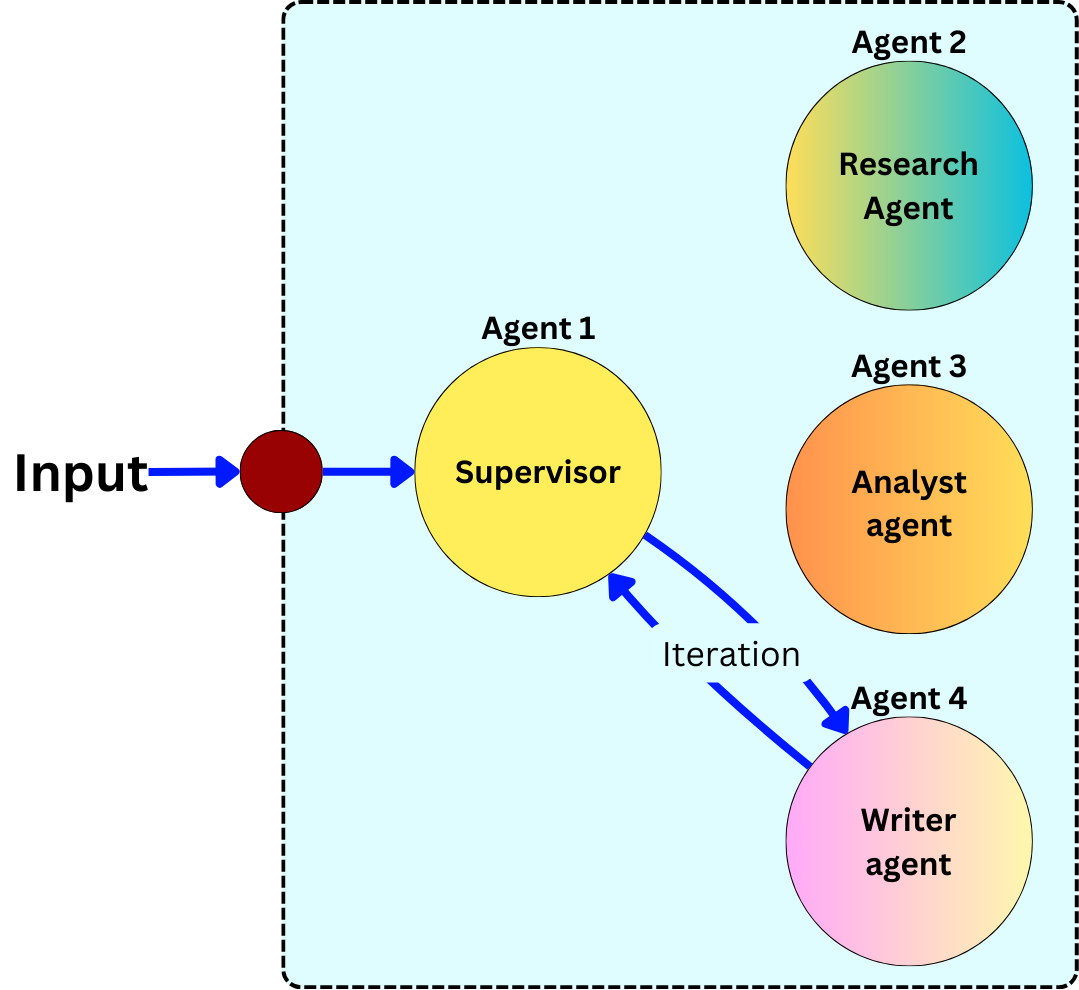
Let’s get a supervisor chain:
from langchain_core.messages import SystemMessage
from langchain_core.prompts import (
ChatPromptTemplate, MessagesPlaceholder
)
from langchain_openai import ChatOpenAI
supervisor_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="""You are a supervisor agent responsible for:
1. Breaking down complex tasks into smaller subtasks
2. Assigning tasks to appropriate worker agents
3. Evaluating work quality and requesting revisions if needed
4. Synthesizing results into final outputs
Available worker agents:
- researcher: Finds and extracts relevant information
- analyst: Analyzes data and identifies patterns
- writer: Creates well-written content
"""),
MessagesPlaceholder(variable_name="messages"),
("human", "{input}"),
])
supervisor_chain = supervisor_prompt | ChatOpenAI(temperature=0)And the agent node would look something like this:
class AgentState(TypedDict):
messages: Annotated[Sequence[Dict], "Chat messages"]
task_queue: Annotated[List[str], "Queue of pending tasks"]
current_task: Annotated[str, "Current task being processed"]
results: Annotated[Dict, "Results from worker agents"]
status: Annotated[str, "Current workflow status"]
# Agent functions
def supervisor_agent(state: AgentState) -> AgentState:
"""Supervisor agent that manages the workflow"""
messages = state["messages"]
# If this is the start of a new task, break it down
if state["status"] == "start":
response = supervisor_chain.invoke({
"messages": messages,
"input": "Break down this task into subtasks and assign them to appropriate workers."
})
# Parse subtasks from response
# (in practice, you'd want more robust parsing)
subtasks = [
"research: gather information",
"analyze: process findings",
"write: create report"
]
state["task_queue"] = subtasks
state["status"] = "in_progress"
state["messages"].append({
"role": "assistant", "content": str(response.content)
})
# If we have results to evaluate
elif state["status"] == "review":
response = supervisor_chain.invoke({
"messages": messages,
"input": f"Review the following results and determine if they're satisfactory: {state['results']}"
})
# For demo purposes, always mark as complete
state["status"] = "complete"
state["messages"].append({
"role": "assistant", "content": str(response.content)
})
return stateLet’s get three fake empty agents:
def researcher_agent(state: AgentState) -> AgentState:
# To implement
return state
def analyst_agent(state: AgentState) -> AgentState:
# To implement
return state
def writer_agent(state: AgentState) -> AgentState:
# To implement
return stateNow, we get a router to route the tasks to the correct agents:
# Router function
def route_next(state: AgentState) -> str:
"""Determine the next step in the workflow"""
if state["status"] == "complete":
return "end"
if not state["task_queue"] and state["status"] == "in_progress":
state["status"] = "review"
return "supervisor"
if state["task_queue"]:
current_task = state["task_queue"].pop(0)
state["current_task"] = current_task
if "research" in current_task:
return "researcher"
elif "analyze" in current_task:
return "analyst"
elif "write" in current_task:
return "writer"
return "supervisor"Now let’s compile the graph:
workflow = StateGraph(AgentState)
# Add nodes
workflow.add_node("supervisor", supervisor_agent)
workflow.add_node("researcher", researcher_agent)
workflow.add_node("analyst", analyst_agent)
workflow.add_node("writer", writer_agent)
# Add conditional edges
workflow.add_conditional_edges(
"supervisor",
route_next
)
workflow.add_conditional_edges(
"researcher",
route_next
)
workflow.add_conditional_edges(
"analyst",
route_next
)
workflow.add_conditional_edges(
"writer",
route_next
)
# Set entry point
workflow.set_entry_point("supervisor")
# Compile the graph
supervisor_app = workflow.compile()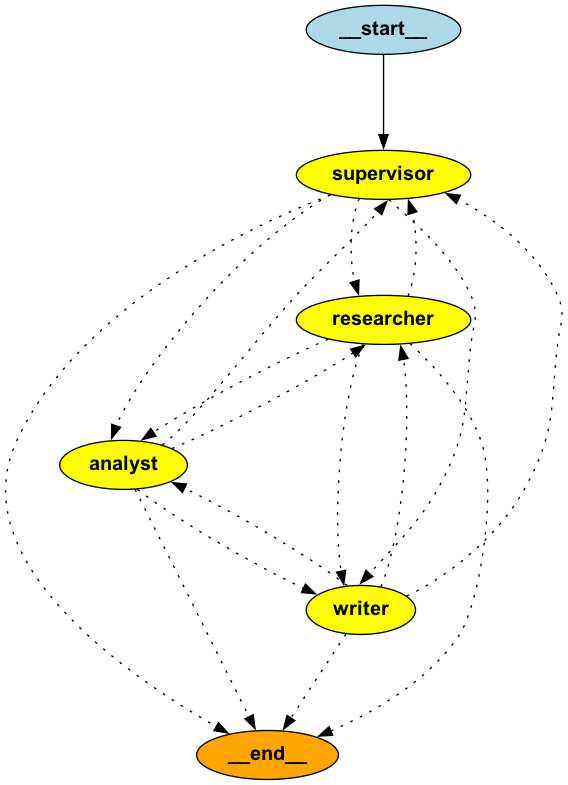
There are tasks where LLMs are very unlikely to hallucinate. For example, summarizing text, choosing between a limited set of options, and even writing very simple code. So, the game is about creating agents with very limited control and simple outputs such that hallucinations are as unlikely as possible and utilizing human domain expertise to rule how the different agents can interact with each other.
If we need to solve complex problems, then we need to include more of those simple agents, and the complexity will be offloaded on the human-designed architecture and the software needed to orchestrate the interactions. We often dismiss LLM pipelines as "Open API wrappers", but we underestimate the value of the domain expertise needed to build those wrappers to solve problems in a niche domain. For example, the previous graph could be part of a larger application as a subgraph.
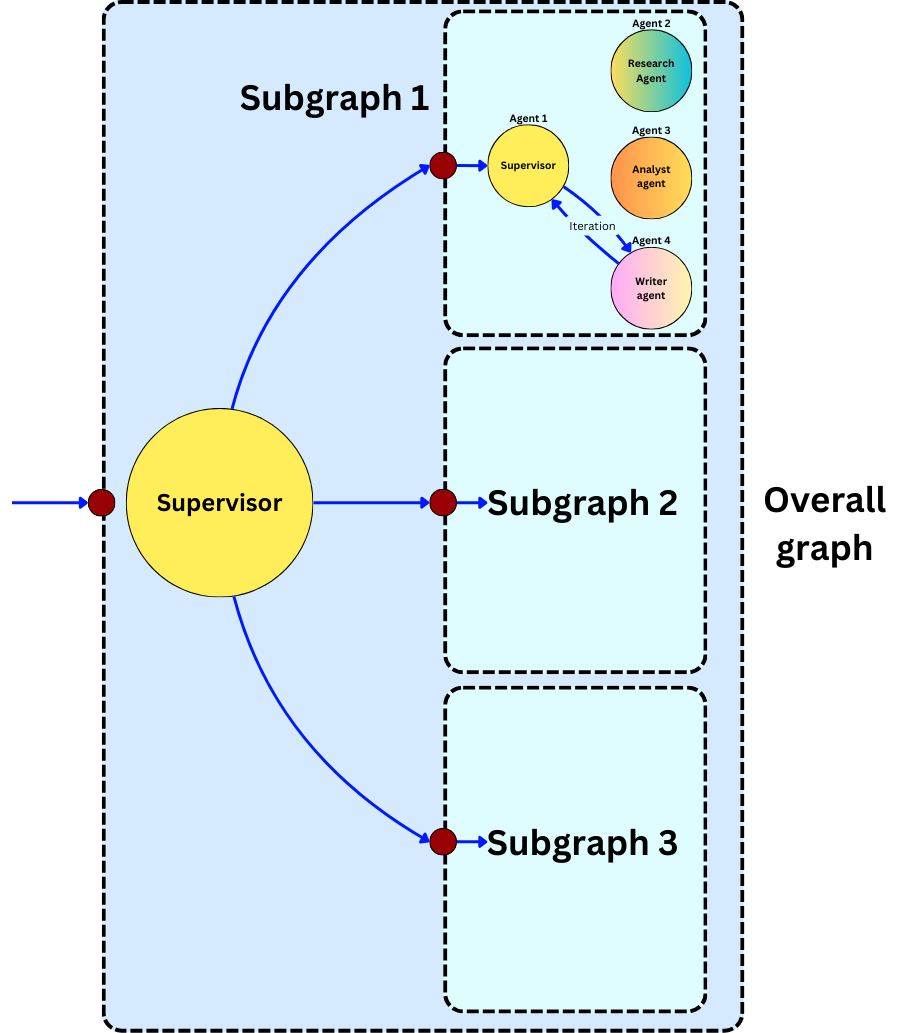
If we build those agents to only accept or emit structured data such as JSON or other data structures, and considering the limited scope of each agent, it is also much easier to build software to validate the data coming in and out of those agents. For example, if an agent is only supposed to extract keywords from text in a JSON format, we can easily programmatically check the validity of the output format and the existence of those keywords in the original text. If an agent is supposed to output code, we can directly compile it and unit test it. We can also implement the reflection pattern with feedback loops where we have special agents in charge of validating the output of other agents.
In cases where hallucinations are more likely to occur or when decisions should not be taken automatically, then it is important to implement software with humans in the loop to validate the intermediary outputs. This allows humans to provide feedback to an autonomous system and brings the system back on track if it starts to diverge from what is expected. For example, in the previous supervisor application, let’s induce human feedback:
from langchain.callbacks import AsyncIteratorCallbackHandler
# Extend our state to include human feedback
class SuperState(TypedDict):
inner_state: Annotated[AgentState, "State for the agent subgraph"]
human_feedback: Annotated[str, "Feedback from human reviewer"]
final_output: Annotated[Dict, "Final approved output"]
status: Annotated[str, "Overall process status"]
# Human-in-the-loop review function
async def human_review(state: SuperState, callback: AsyncIteratorCallbackHandler) -> SuperState:
"""Awaits human review and feedback"""
# Prepare review message
review_message = {
"type": "human_feedback_required",
"content": state["final_output"],
"instructions": """
Please review the agents' work and provide feedback:
- Approve: Type 'approve' to accept the output
- Revise: Type 'revise:' followed by specific feedback
- Reject: Type 'reject:' followed by reason
"""
}
# Send to human reviewer
await callback.on_text(json.dumps(review_message, indent=2))
# Wait for response (in real implementation,
# this would be handled by your UI)
response = await callback.on_text("Waiting for human feedback...")
state["human_feedback"] = response
# Update status based on feedback
if response.startswith("approve"):
state["status"] = "complete"
elif response.startswith("revise"):
state["status"] = "revision_needed"
elif response.startswith("reject"):
state["status"] = "rejected"
return stateLet’s say we have a node to prepare the output of the supervisor subgraph:
# Function to prepare content for human review
def prepare_review(state: SuperState) -> SuperState:
agent_state = state["inner_state"]
review_content = {
"research_findings": agent_state["results"].get("research", {}),
"analysis": agent_state["results"].get("analysis", ""),
"final_document": agent_state["results"].get("writing", ""),
"process_log": agent_state["messages"]
}
state["final_output"] = review_content
state["status"] = "review_ready"
return stateLet’s put the app together:
# Router for the super graph
def route_super(state: SuperState) -> str:
"""Determines the next step in the super graph"""
status = state["status"]
if status == "start":
return "agent_workflow"
elif status == "needs_review":
return "prepare_review"
elif status == "review_ready":
return "human_review"
elif status == "revision_needed":
return "agent_workflow"
elif status in ["complete", "rejected"]:
return END
else:
return "prepare_review"
# Create the super graph
super_workflow = StateGraph(SuperState)
# Add nodes - directly adding the compiled supervisor_app as a node
super_workflow.add_node("agent_workflow", supervisor_app)
super_workflow.add_node("prepare_review", prepare_review)
super_workflow.add_node("human_review", human_review)
# Add conditional edges
super_workflow.add_conditional_edges(
"agent_workflow",
route_super
)
super_workflow.add_conditional_edges(
"prepare_review",
route_super
)
super_workflow.add_conditional_edges(
"human_review",
route_super
)
# Set entry point
super_workflow.set_entry_point("agent_workflow")
# Compile super graph
super_app = super_workflow.compile()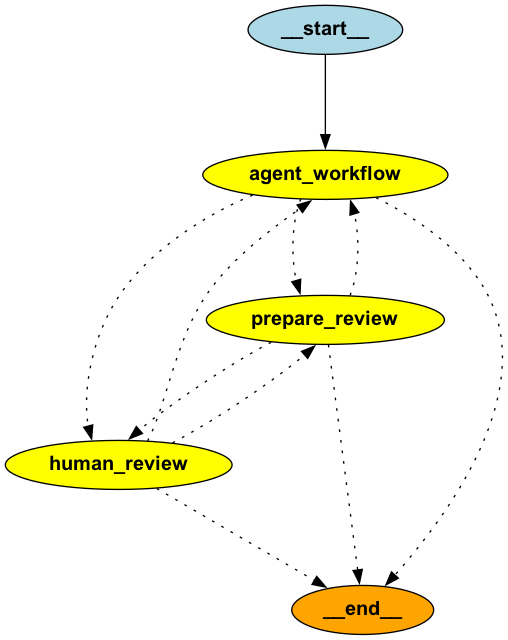
Let’s stop here!
There are too many packages and functionalities to capture everything in one newsletter! I wanted to give you here a sense of the main aspects and the differences between micro-orchestration and macro-orchestration. In my opinion, we can easily get away without relying on any of the micro-orchestration frameworks, but I believe a macro-orchestration framework is critical to building large applications.
—