TheAiEdge+: When Machine Learning Goes Wrong!

As opposed to typical software, the data dependency makes it easy for Machine Learning systems to break! Even with typical unit or integration tests and shadow or canary deployments, you won’t be able to catch those problems if a bug is injected within the data pipelines. Data and Machine Learning can go wrong, but fortunately, there are ways to mitigate those problems. Today we cover:
Data gone wrong
Fallback mechanisms: Predict no matter what!
Learn more about when Machine Learning goes wrong
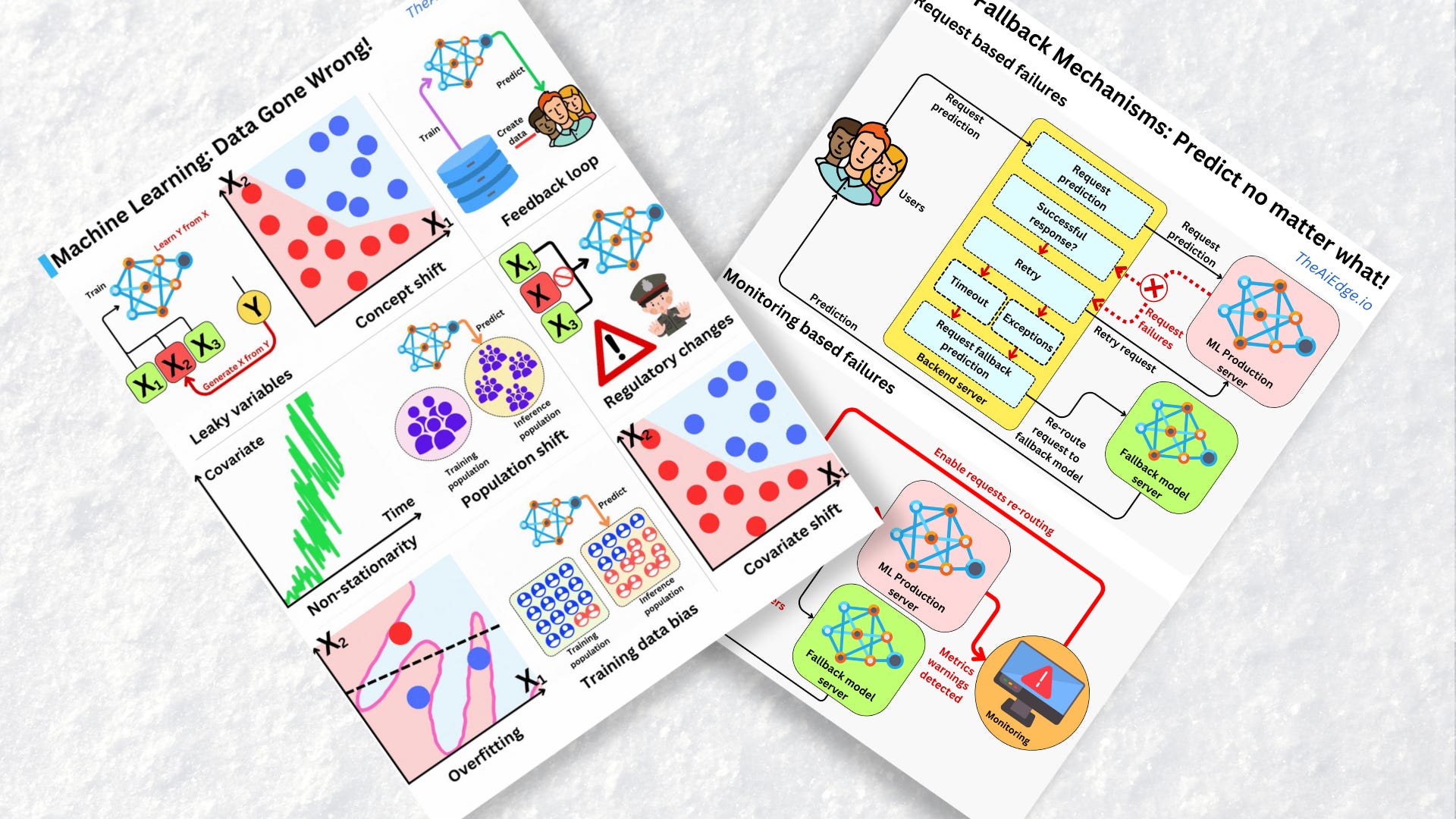
Data gone wrong
There definitively is no shortage of ways Data can go wrong when it comes to Machine Learning! There are no magic tricks to avoid those but there are ways to mitigate them to some degree.
Leaky variables are when you are using information you could not have known at the time of prediction in your training data. In a sense, you are including what you are trying to predict as part of your feature set which leads to seemingly overperforming models. Besides high data governance, that is where correctly defining train / val / test datasets is critical.

Leaky variables Concept drift is when the distribution of the underlying input variables remains the same but their relationships to the target variable change. That is why it is important to have periodic retraining or continuous training strategies in place.

Concept shift Feedback loops are when the current model's predictions are used to accumulate future training data. Because of it, it leads to selection bias with the future models trained on data that do not represent well production data. That happens a lot in recommender engines! That can actually tend to lead to better models but it also can reinforce mistakes made by previous models.

Feedback loop Stationarity is a fundamental assumption in statistical learning as we assume that samples are identically distributed. If their probability distribution evolves over time (non-stationary), the identical distribution assumption is violated. That is why it is critical to build features that are as stationary as possible. For example dollar amount is not a good feature (because of inflation), but relative dollar changes (Δ$ / $) may be better.