

Understanding CatBoost!

Catboost might be the easiest supervised learning algorithm to use today on large tabular data. It is highly parallelizable, it automatically deals with missing values and categorical variables, and even more than Xgboost, it is built to prevent overfitting. If you throw some data into it, without much work, you are pretty much guaranteed to get state-of-the-art results. This assumes your data is training-ready, but even then, it is almost too good to be true!
I made a previous video explaining how the gradient boosting algorithm works and another explaining how Xgboost works. Catboost builds on top of those two algorithms, so make sure to check them out. Now, let's dig into how Catboost works!
CatBoost was developed by Yandex in 2017: CatBoost: unbiased boosting with categorical features. They realized that the boosting process induces a special case of data leakage. To prevent that, they developed two new techniques, the expanding mean target encoding and the ordered boosting.
A target encoding is a technique to encode a categorical variable into a numerical one. It allows the building of a variable that has a very simple and easy-to-learn relationship to the target variable. I always found Leave-One-Out (LOO) Target Encoding to be a powerful but simple method! It is also a very risky method: it is so easy to overfit! The trick is to smooth the encoding by computing a weighted mean of the category mean and the global mean and cross-validating the weighting parameter: such a pain when you need to do that for all the categorical features! Also, it is tricky to apply to the test set without data leakage. One advantage, though, is that you effectively linearize a variable that originally had a highly non-linear relationship to the target. You can read more about it here: “Getting Deeper into Categorical Encodings for Machine Learning”. Here is the category encoder Python package: “Leave One Out“.
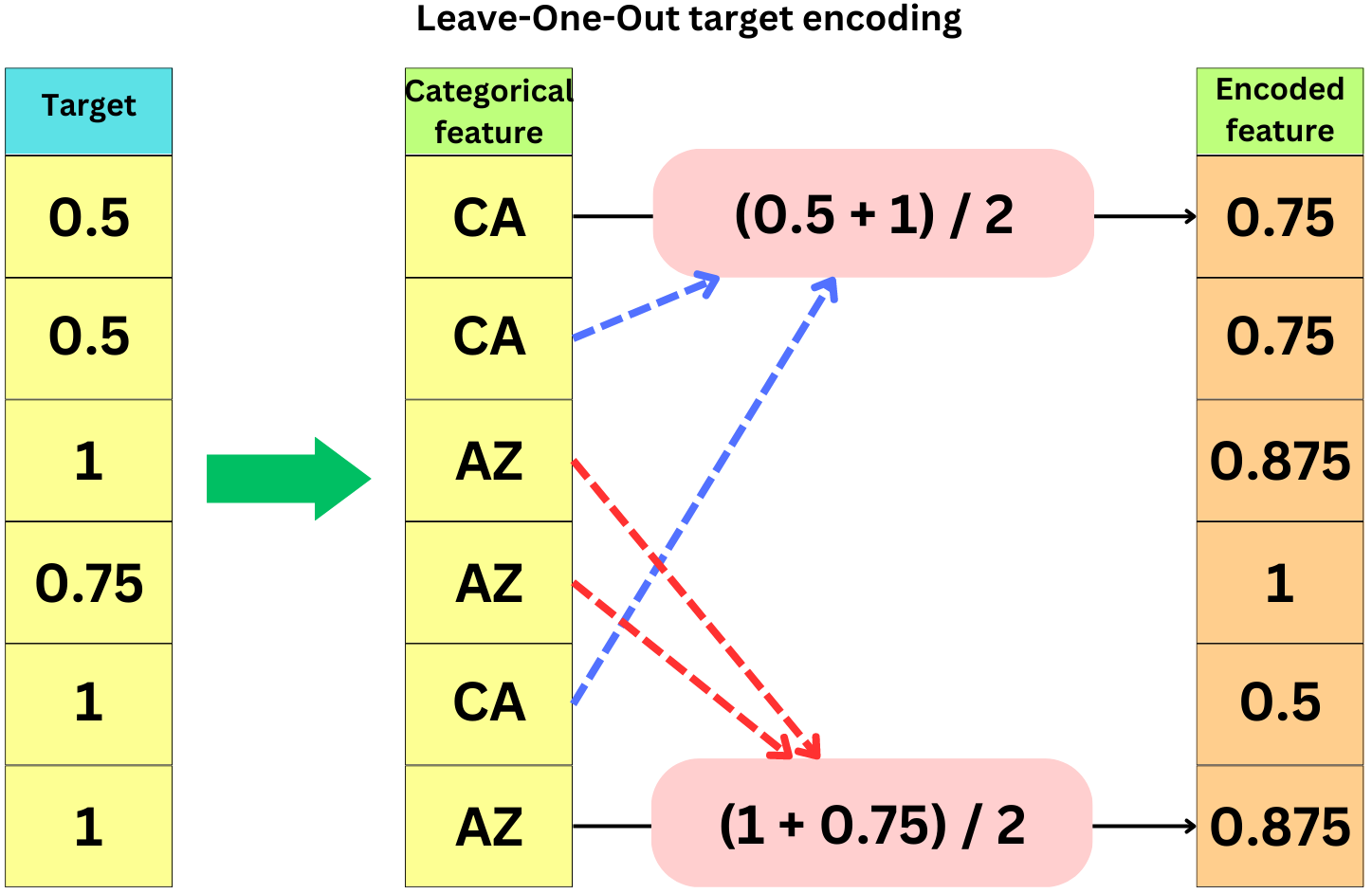
Another powerful technique is Expending Mean Target Encoding. The idea is very similar to LOO. Instead of considering all the values, we perform a cumulative average of the target while omitting the target itself from the average. When predicting on unseen data, we just use the full mean encoding of the categorical value.

It is the method used by Catboost. In the category encoder package, they call it the "Catboost encoder". It doesn't overfit (not as much), requires no hyperparameters to cross-validate, and takes three lines of code. Such a simple method!
cumsum = df.groupby(cal)['target'].cumsum() - df['target']
cumcount = df.groupby(cal)['target'].cumcount()
df[col + '_encoded'] = cumsum / cumcountEach tree is trained with a different permutation of the training data.

The target encoding is performed by considering the rows appearing before the current row in the specific permutation of the data. This means that each permutation will generate a different encoding, minimizing the overfitting effect.
When we learn the trees, we need to compute the gradients and Hessians by using the samples in each tree node.

The ordered boosting is meant to avoid computing the residuals (gradients and Hessians) using the current sample itself, but only samples that appear earlier in the specific permutation of the training data.

This means that each sample will yield a different computed gradient and Hessian for the different permutations of the training, leading to trees that are more robust to overfitting.
SPONSOR US
Get your product in front of more than 63,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - tens of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
To ensure your ad reaches this influential audience, reserve your space now by emailing damienb@theaiedge.io.