

Understanding The Self-Attention Mechanism

The self-attentions are used to replace the recurring units to capture the interactions between words within the input sequence and within the output sequence.
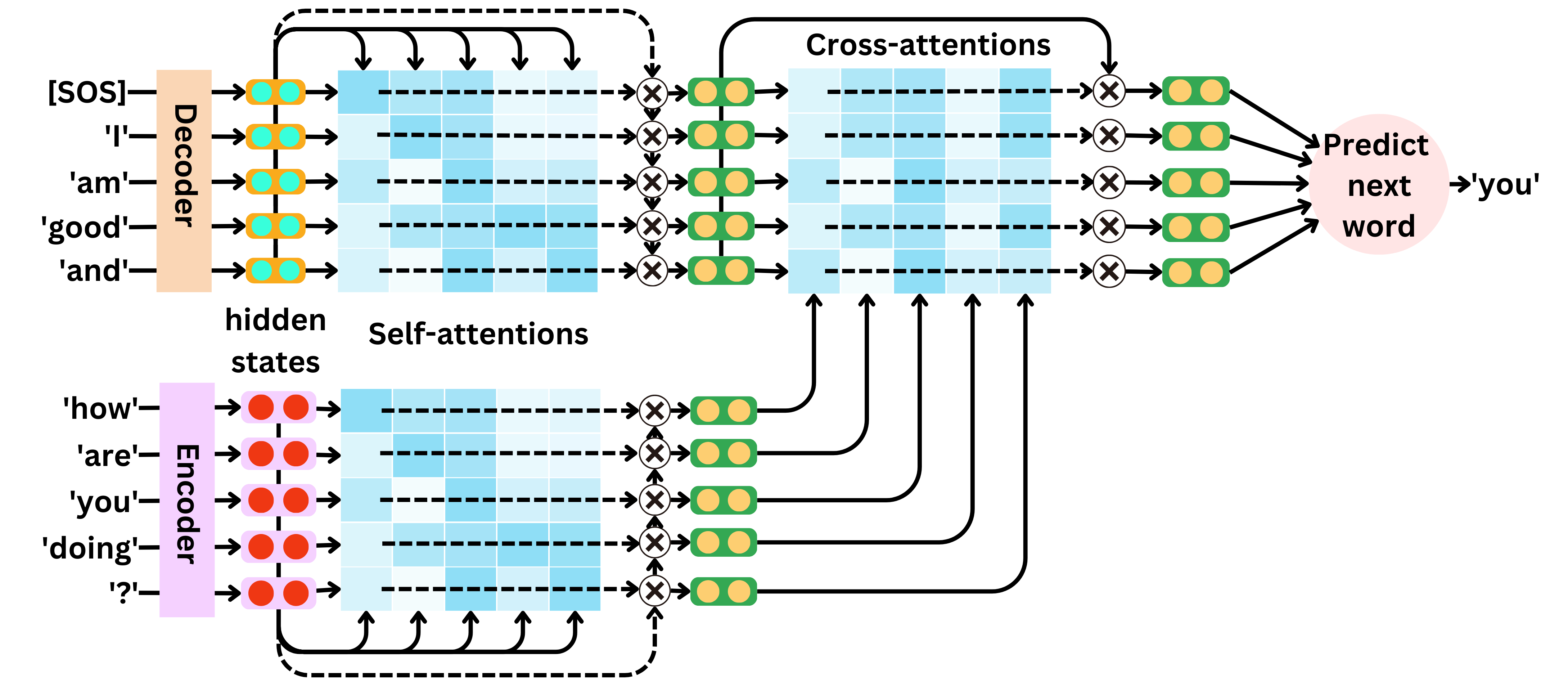
In the self-attention layer, we first compute the keys, queries, and values vectors.

We then compute the matrix multiplication between the keys and queries.

After a softmax transformation, this matrix of interactions is called the attention matrix. The resulting output hidden states of the attention layer are the matrix multiplication of the attention matrix and the values vectors.

Each of the resulting hidden states coming from the attention layer can be understood as a weighted average of the values, with the attentions being the weights.
