

What are Large Language Models?

Today we welcome Etienne Bernard, CEO of NuMind, as a guest writer! Let’s learn more about Large Language Models. We cover:
Language Models
Naive Language Models
Neural-Network Based Language Models
Modern Large Language Models
Instruction-Tuned & Chatbot LLMs
What’s Next?
These past few months, thanks to ChatGPT and its siblings, we have been witnessing something historic. It seems that computers are finally able to understand our language, and are even able to speak back! These AIs are the latest iterations of large language models, also known as LLMs. But what exactly are these LLMs? How do they work? And how are they created? Let's dive into it.
Language Models
In a nutshell, a language model is something that is able to generate text in some way. Language models have plenty of applications. For example, you can use them to analyze sentiment, flag toxic content, answer questions, summarize documents, and so on. But in principle, they could go far beyond these usual tasks.
Indeed, imagine, for example, that you have a perfect language model, something that can generate any kind of text in such a way that it is impossible to distinguish whether this text is generated by a computer or not. Then, you could do plenty of things with it. For example, you could make it generate classic content such as emails, news articles, books, and movie scripts. But then you could go a step further and make it generate computer programs or even entire software. And then, if you are really ambitious, you could make it generate scientific articles. If the language model is truly "perfect", these scientific articles would be indistinguishable from real articles, which means the language model would have to conduct actual research!
Of course, such a perfect language model is out of reach at the moment, but this gives an idea of the potential power of these systems. Language models are not "just predicting text"; they are potentially much more than that.
Let's now look at what these models are in practice, starting from the first kind of naive language models to the current transformer-based large language models.
Naive Language Models
Language models are machine learning models, which means that they learn how to generate text. The way to teach them (a.k.a. the training phase) is to give them a large corpus of text, from which they figure out how to imitate the generative process that created it.
Ok, this is rather abstract, but it is actually easy to create a naive language model. You can take a corpus of text, chunk it into strings of a certain size, and measure their frequencies. Here is what I got with strings of size 2:
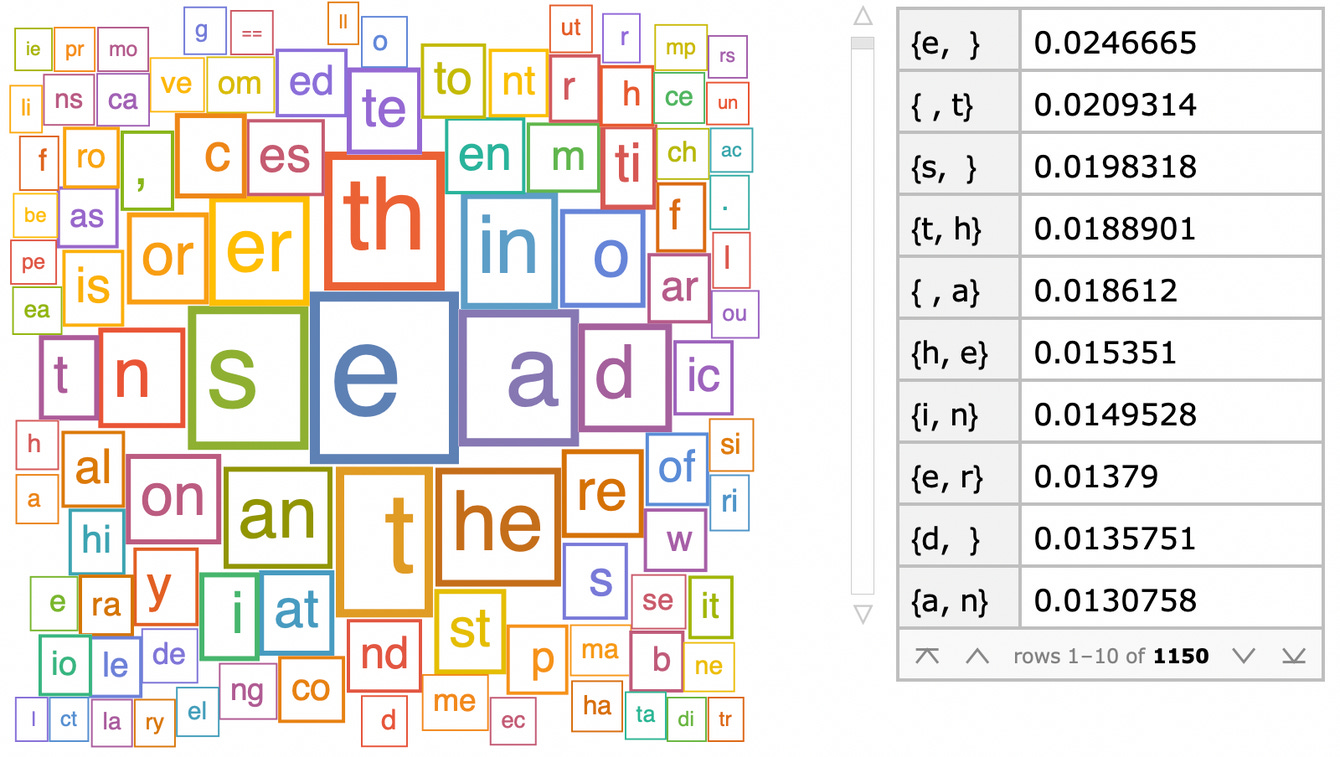
These chunks are called n-grams (where n is their size, so n=2 here). From these n-grams you can generate text by playing dominoes. You start with an initial n-gram, let’s say “th”, and then randomly select - according to the measured frequencies - one n-gram whose beginning matches the end of the initial n-gram. Here it could be “hi”, which would make “th”+”hi”= “thi”. You can then continue by attaching an n-gram starting with a “i”, and so on to generate entire text. As you probably guessed, these n-gram models do not generate the most coherent text. Here is what I got when continuing the procedure:
thint w dicofat je r aton onecl omitt amen h s askeryz8, orbexademone ttexind thof thevevifoged tc hen f maiqumexin sl be mo taicacad theanw.soly. fanitoila, al
Not great, to say the least! This makes sense because the model only takes into account the previous character to make its next-character prediction - it has a tiny memory. If we use n=4, we get something slightly better:
complaine building thing Lakers inter blous of try sure camp Fican chips always and to New Semested and the to have being severy undiscussion to can you better is early shoot on
Now there are some correctly spelled words, but this is still not great! In theory, increasing n further will make things better, but in practice, we cannot increase n much without requiring a gigantic dataset to train the model on. One last thing we could do is to use words instead of characters as the base unit (the base unit is called token in NLP jargon). It will improve things, but it won’t lead to very coherent text either since we are limited to n<6.
These naive language models always have a short memory and thus cannot generate coherent text beyond a few words. They do have some use cases, though. Until a few years ago, they were used extensively for text classification and speech recognition, and they are still used today to identify languages, for example. However, for more advanced text understanding and text generation tasks, these models are not sufficient. We need neural networks!
Neural-Network Based Language Models
Modern language models are based on (artificial) neural networks. Neural networks are brain-inspired computing machines that are able to learn how to perform a task from examples of that task. This form of machine learning is also called deep learning because the networks are composed of several computational layers (hence they are “deep”). In a neural network, learning is done by going through the examples of the task and iteratively modifying the parameters of the network to optimize the task objective. You can think of these parameters as a bunch of knobs that you can turn left and right to improve the objective, except that it is the computer turning them for you, and it knows how to turn them all at once in the correct directions to improve things (thanks to the famous backpropagation algorithm). So the network goes through the examples of the task (typically by batch of a few hundred examples) and optimizes the objective as it goes. Here is an example of an objective (called a cost function, the smaller the better) being optimized:

As the model is trained, the cost goes down, which means that the model gets better at its task.
Ok, so in our case, we want to generate text. The current standard way to do this is to train a model on the task of predicting the next word from previous words. Since there are several possible continuing words, the model learns to associate a probability with every possible continuing word. Here is a visualization of this probability distribution for what comes after "the cat sat on the":

Once we have such a predictive model, we can generate a word by sampling from its predicted probabilities, then re-inject this word into the network, sample a new word, and so on to generate text. Such a generative procedure is said to be autoregressive because the network reuses its own predictions to make new predictions. There are arguments as to why this is not the best way to do it, but it is currently how it is done, and it works surprisingly well!
Historically, the first kind of neural networks that have been used to model language is recurrent neural networks (a.k.a. RNNs), and in particular the LSTM architecture. RNNs are like little machines that read words one by one, updating a sort of mental state in the process. This mental state is like a memory, and allows them to - potentially - remember things for a while as they generate text. RNNs can obtain much better performance than n-gram models.
The RNN that impressed me the most at the time of its creation was A Neural Conversational Model, which features an LSTM trained by Google in 2015 on movie subtitles. This model is, by all means, already a large language model (maybe be the first?): it has more than 300 millions parameters, and has been trained on about 1 billion words. Since movie subtitles are conversations, you can readily use this model as a chatbot. Here are examples of answers from various human inputs:
Human: what ’s your name ?
Machine: i ’m julia .
Human: when were you born ?
Machine: july 20th .
Human: my name is david . what is my name ?
Machine: david .
Human: who is skywalker ?
Machine: he is a hero .
Human: what is the color of the sky ?
Machine: blue .
Human: what is the color of blood ?
Machine: it is the same as a black eye .
As you can see, the model is able to chit-chat, but it also knows a little bit about the world, which it learned solely from learning to predict text! I remember being fascinated by this fact: learning to predict text forces you to understand the world (which does not mean it is easy by any means). However, this model has strong limitations. It is often wrong and, like similar LSTM-based models, cannot generate long coherent texts. Indeed, in theory, RNNs can remember things for a long time, but in practice, they tend to forget things fairly quickly: past a few dozen to a hundred words, they start to derail and become incoherent.
One solution to this short-term memory issue came in 2017 from a new kind of neural network called transformers, which is based on the attention operation (which is essentially a selection operation). As an eye candy, here is how the transformers are depicted in their introductory paper for the task of translation:

There are plenty of interesting things to say about this architecture, but the bottom line is that transformers works very well for modeling text, and it is well adapted to be run by graphics cards (GPUs) in order to process (and learn from) large amounts of data. It is this transformer architecture that led to (or at least strongly contributed to) the emergence of modern large language models.
Modern Large Language Models
The invention of transformers marked the beginning of the era of modern large language models. Since 2018, AI labs have started to train increasingly larger models. To the surprise of many, the quality of these models kept improving! Here is a visualization of these models, from which we will highlight the notable ones:
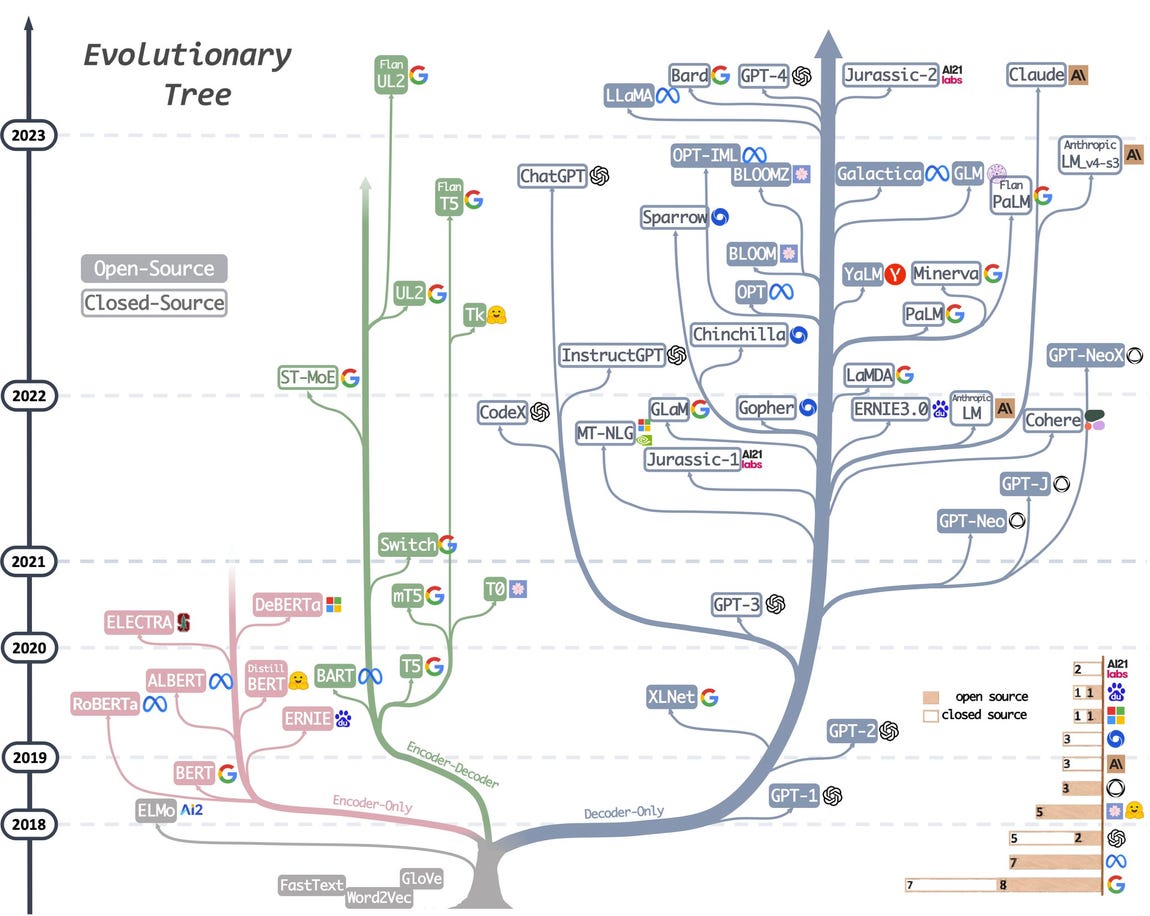
There are three main flavors for these language models. One type (shown in pink on the picture, the "encoder-only" group) includes LLMs that are good at text understanding because they allow information to flow in both directions of the text. Another type (shown in blue in the picture, the "decoder-only" group) includes LLMs that are good at text generation because information only flows from left to right of the text in order to generate new words efficiently in an autoregressive fashion. Then there is an encoder-decoder type (shown in green) which combines both aspects and is used for tasks that require understanding an input and generating an output, such as translation.
It mostly started with the text understanding kind. First with ELMo (still using RNNs) and then the famous BERT from Google, and its descendants like RoBERTa, which are all transformers. These models typically have around a few hundred million parameters (corresponding to around 1GB of computer memory), are trained on around 10GB to 100GB of text (so typically a few billion words), and can process a paragraph of text in about 0.1s on a modern laptop. These models have drastically improved the performance of text-understanding tasks such as text classification, entity detection, and question answering. This was already a revolution in the field of NLP, but it was just the beginning...
In parallel with the development of text-understanding LLMs, OpenAI began creating text-generating LLMs based on transformers. First, there was GPT-1 in 2018, which had 100 million parameters, and then GPT-2 in 2019, which has up to 1.5 billion parameters and is trained on 40GB of text. The creation of GPT-2 was, at least to me, a pivotal moment. Here is the kind of text it can generate, starting from a human-written paragraph:

This is excellent English, and the text is coherent. For example, the name of the scientist does not change, which would be a classic issue with RNN-based models. GPT-2 was such a leap in generation quality that OpenAI originally decided not to release it to the public for fear of harmful use. GPT-2 was a sign that LLMs were on the right track. Note that the way to use such a language model is to give it a starting text to be completed. This initial text is called a prompt.
One year later (2020), OpenAI created GPT-3, a model with 175 billion parameters (700GB of computer memory to store the model!). This was a significant increase in size, and it represented another significant improvement in terms of text generation quality. In addition to its improved performance, GPT-3 has been eye-opening in terms of how we might use LLMs in the future.
First, GPT-3 is capable of writing code. For example, you can use it to generate (very) simple websites by describing what the website should look like in the prompt. Here is an example where we ask GPT-3 to create a button in HTML:

These basic coding abilities were not so useful at the time, but they hinted that software development could be radically transformed in the future.
Another eye-opening insight from GPT-3 is that it can perform in-context learning, which means it has the ability to learn how to perform a task by only being shown examples in a prompt. This means that you can customize these LLMs without having to change their weights, just by writing a good prompt. This has opened up a new kind of NLP, purely based on prompting, which is now very popular.
Overall, GPT-3 revealed the potential of prompting as a new way to make machines do what we want them to do through natural language.
Note that GPT-3 is much larger than GPT-2. Since 2018, we have witnessed an extreme increase in model sizes. Here are some notable LLMs, along with their sizes:

In two years, the number of parameters has been multiplied by 1000, and the current largest models (like GPT-4) are close to 1 trillion parameters. This increase was driven by the fact that performance kept on improving with model size, with no plateau in sight. These models are so big that we might be tempted to compare them with our brain, which has around 100 billion neurons, each connected to around 1,000 other neurons on average, so about 100 trillion connections in total. In a sense, the largest LLMs are still 100 times smaller than our brain. Of course, this is a very loose comparison since our brain and current LLMs use very different architectures and learning procedures.
Another interesting metric about these models is the number of words that they "read" during their training phase:

As you can see, it is a lot. These models see more than 100 billion words during their training, which is more than 100 times what a human will ever hear or read in their lifetime! This shows how different these neural networks are from our brain. They learn much more slowly than us, but have access to much (much!) more data.
Note that the number of words that LLMs encounter during their training did not increase as much as the parameter count (only a factor of 3 between GPT-1 and GPT-3). This is because model size was prioritized instead, and it turned out to be a bit of a mistake. The latest models are not much larger than GPT-3, but they are trained by processing much more words than GPT-3.
The issue with this hunger for data is that there is a hard limit on the total amount of useful text available - a few trillion words - and models are getting close to it. There is still the possibility to loop over all this text, but this results in diminishing returns in terms of model performance. Overall, we can consider that there is an effective limit of a few tens of trillions of words to be processed by the network during its training phase - about 10 times more than GPT-4 experienced.
The other issue, which arises from training larger models on more data, is that the cost of computing is increasing. Here are the estimated computation costs for training the models mentioned above:

To significantly outperform current models, the next generation of models should require hundreds of millions of dollars in computation, which still makes sense given the benefits these models provide, but is an issue nonetheless.
Scaling models up is becoming increasingly difficult. Fortunately, scaling up is not the only way to improve LLMs. At the end of 2022, an innovation unlocked yet another revolution, with an impact far beyond the world of NLP this time.
Instruction-Tuned & Chatbot LLMs
GPT-3 revealed the potential of prompting, but writing prompts is difficult. Indeed, classic LLMs are trained to imitate what they see on the web, so to create a good prompt you have to figure out what would be, on the web, the initial text that would lead to your desired output. This is a weird game and kind of an art to find the right formulation. You need to change the wording, pretend that you are an expert, show examples of how to think step by step, and so on. This called prompt engineering, and it makes using these LLMs difficult.
To address this, researchers have been exploring how to modify these base LLMs to better follow human instructions. There are two main ways to do this. The first is to use instruction-answer pairs that are written by humans and then fine-tune (i.e., continue training) the base LLM on this dataset. The second way is to have the LLM generate several possible answers, have humans rate these answers, and then fine-tune the LLM on this dataset using reinforcement learning. This is known as the famous Reinforcement Learning from Human Feedback (RLHF) procedure. It is also possible to combine both approaches, which is what OpenAI did with InstructGPT and then with ChatGPT.

Using both techniques together results in an instruction-tuned LLM that is much better at following human instructions than the base model, and therefore much easier to use.
Instruction-tuned LLMs were already great, but there was one last step to turn these LLMs into something that could truly be used by everyone: making a chatbot version of them. OpenAI achieved this by releasing ChatGPT in December 2022, a chatbot based on GPT-3.5. It has been created in the same way as InstructGPT, but this time using entire conversations instead of just instruction-answer pairs.
After the release of ChatGPT, we witnessed a number of new LLM-based chatbots. OpenAI improved ChatGPT by using GPT-4 instead of GPT-3.5, Anthropic released Claude, Google released Bard, Meta released LLaMA, and several open-source LLMs are currently being released. This is a real explosion, and I believe it will lead to many exciting applications - something that we, at NuMind, will help with.
Two months after its release, ChatGPT already had 100 million users, the fastest product growth ever. People use it to write emails from bullet points, to reformulate text, to summarize text, to write code, or just to learn something - a task that search engines had the monopoly of until then. The release of ChatGPT was a turning point in the history of LLMs. Everyone realized the potential of these LLMs, and an "AI race" started, involving the main AI labs in the world and several startups.
Note that the sudden widespread accessibility of LLMs also comes with the concern that they will be used to do harmful things. This is why a big part of creating these open-ended LLM-based chatbots is about making them "safe" (or "aligning them with human values"), which means that they should not help you build a bomb, for example. At the moment, there are often ways to trick the chatbots and bypass their safeguards, but these safeguards are getting better over time. I believe that it will become very hard to trick them eventually.
What’s Next?
LLMs have improved a lot these last years, and there is more effort than ever directed at improving them further. So, what should we expect for the next few years? It is hard to predict the future, but here are some thoughts.
One obvious direction is to continue scaling up model sizes and the amount of training data. This has worked extremely well in the past and should still allow for some improvements. The issue is that training costs are becoming prohibitive (>$100M). Better GPUs and new specialized hardware will help, but they take time to be developed and produced. Also, the biggest models already iterate over all books and about the entire web, which means we are reaching the limits in terms of available training data (the so-called “token crisis”). So, for sure, there will not be an explosion of parameter numbers in the next few years like we saw in the last few years. The largest models should settle below 1 trillion parameters this year, and then experience something like a 50% annual growth at most.
Another obvious direction is to go beyond pure language models and incorporate images or even videos into the training data - that is, to train multimodal models. Learning from such data might help these models understand the world better. GPT-4 has been trained on images as well as text, and it improved performance a bit (but not so much). Training on videos might change the game, but it requires a lot of computation. I would expect us to have to wait 2+ years before seeing the first real large "language" model trained on videos.
Scaling up or going multimodal will require a lot of computation. A solution to mitigate this issue is to use better neural architectures and training procedures that are either less computationally intensive or that can learn with less data (and our brain is proof that it is possible). Most likely, RNN-like memory will make a comeback because it is so efficient at runtime (see for example the recent RWKV architecture). But we could also see a more drastic change, such as LLMs that do not generate in an auto-regressive fashion but in a top-down fashion - basically making (random) decisions prior to generating words - which seems like a more logical thing to do when you think about it (and is how neural networks generate images at the moment). It is hard to know when such new architectures/methods will be developed, but I would not be surprised if it happens in the next few years and leads to greatly improved LLMs.
One other direction for improvement is to follow up on the instruction-tuning route and involve many more humans in "educating" the LLM (a.k.a. aligning the AI). This could be done by private AI labs, but it could also be a more crowd-sourced Wikipedia-like project to improve and align LLM capabilities of open models. On that topic, we might also want to deviate from the traditional RLHF and have people just discuss with the model to teach it, as we would do with children. I'm not sure about the timeline for such a project, but I have been thinking about this for a while and would love to see it happen!
Ok, we only talked about improving the actual model, but there are ways to improve LLMs without even changing the model. One such way is to give LLMs access to tools. Such a tool can be a search engine to find accurate information, or a calculator to do basic math. It can also be a knowledge base coupled with an inference engine (a classic component of symbolic AI) such as Wolfram Alpha to find facts and perform logical reasoning or other kinds of computations that neural networks are not great at. And of course, this tool can be a full-on programming environment to write and run code. LLMs can use these tools by generating special tokens (words) which trigger API calls and then inserting the API output in the generated text:

This tooling trend has already started (see e.g. ChatGPT plugins, the LangChain library, and the Toolformer paper) and I believe it will become central to LLMs.
Another direction is to use the LLMs in a smarter way so that they become better at completing tasks. This can be achieved through clever prompting or a more advanced procedure. One simple example of this is to ask the LLM to think step by step. This is called chain-of-thoughts prompting and improves the performance of LLMs on tasks that require logic. Here is an example of how to prompt an LLM to think step by step:

Similarly, you can ask the LLM to reflect on its output, criticize it, and modify it in an iterative fashion. These kinds of iterative procedures can improve performance significantly, especially for generating code. Then, you can go even further and create fully autonomous agents that can manage a list of tasks and iterate over these tasks until the main goal is reached (see AutoGPT and BabyAGI). These autonomous agents are not working well at the moment, but they will improve, and it is difficult to overstate how impactful they may become.
By the way, since an LLM can improve its answers through these procedures (chain-of-thoughts, iterative critiques, etc.), we can create instruction-answer pairs using these procedures and then fine-tune the LLM on these pairs in order to improve its performance. This kind of self-improvement is possible (see, for example, here) and I believe it has a lot of potential. We could, for example, imagine the model discussing with itself in order to become more self-consistent, a sort of self-reflection procedure. This direction will probably give another boost to LLM performance.
Ok, I probably missed other directions for improvements, but let's stop here. Overall, we can't know for sure what the future holds, but it is clear that LLMs are here to stay. Their ability to understand and generate text makes them a fundamental piece of technology. Even in their current form, LLMs will unlock plenty of applications - the most obvious one being digital assistants that actually work - and in the craziest scenario, they might even lead us to the creation of some kind of super-intelligence - which is a topic for another time!
About the author

Etienne Bernard is an expert in AI & machine learning, author of Introduction to Machine Learning, founder and CEO of NuMind - a startup developing a tool to create custom NLP models. Previously, Etienne was head of machine learning at Wolfram Research for 7 years, where he led the development of machine learning tools and applications. He holds a PhD in statistical physics from ENS and did a postdoc at MIT.
 | A guest post by
|