

Why is GraphRAG Possibly One of the Best RAG Systems!

Why GraphRAG?
The Indexing Pipeline
The Query Pipeline
Implementing GraphRAG
Why GraphRAG?
RAG is about providing additional context from a database to an LLM to generate fact-based answers. The typical way to achieve that is to perform a database search by using the user’s query and retrieving the most similar documents based on textual similarity metrics. The documents are typically small chunks of the original large dataset.

There are many shortcomings to that approach! First, we assume that the user query would be semantically similar to the text needed in the database to answer it, but this might be quite unlikely in some cases. And second, we assume that the entirety of the information necessary to answer a user query will be contained in small local chunks of text. However, it is quite possible that the logical connections between the different elements of text documents may spread across multiple chunks of data and that we may need a lot more than a few text chunks to address some user queries. For example, if you index a book, you cannot request the summary of the book with a typical RAG process because it requires all the document chunks to answer that query.
That is where GraphRAG can provide a solution. GraphRAG is a RAG project by Microsoft. Here, you can find the paper. There are two important aspects to GraphRAG:
Summaries at different scales as context - We are going to create summaries of the different documents at different scales. This way, we are going to be able to understand, overall, what global information is contained in the full documents, as well as the local information contained in smaller chunks of text. It is a bit like being able to provide as context to the LLM summaries of a whole book as well as summaries of paragraphs of that book. The LLM will be able to consider the low-level context and understand how this context relates to a higher-level structure of information.

Graphical representation of the information - We are going to reduce the textual information to its graphical form. The assumption is that the information contained in the text can be represented as a set of nodes and edges. The nodes represent the entities in the text and the edges of their relationships. For example, the following sentence:
"John Smith teaches Mathematics at the University of Oxford and has 15 years of experience."
could be represented by the following graph:

This allows the representation of the full information contained in the text as a knowledge base that can be stored in a graph database.


Let’s see how we can move from a graphical representation of knowledge to summaries at different scales.
The Indexing Pipeline
From Documents to Text Chunks
The first step is to chunk all the documents into small text chunks. For GraphRAG, it is very important to consider documents that could related to each other. If we lump together documents that are unrelated to each other, the graphical interpretation will tend to build relationships where none exist, and we will be left with meaningless summaries.

The default chunk size in the GraphRAG software made available by Microsoft is 1200 tokens. A good rule of thumb for most LLMs is ~4 characters per token on average. Larger chunks allow the LLM, during the knowledge graph step, to discover more interesting relationships between the different entities but also lead to more potential errors as more text will confuse it.
For example, for small chunks, a specific paragraph may refer to “he“ when it comes to an entity “Billy“ described in a previous chunk, and it will not be a useful label to capture the information related to the entity “Billy“.
Chunk 1: "Billy went to the store yesterday afternoon.”
Chunk 2: “He bought some groceries and milk."
Which would lead to two disconnected subgraphs:
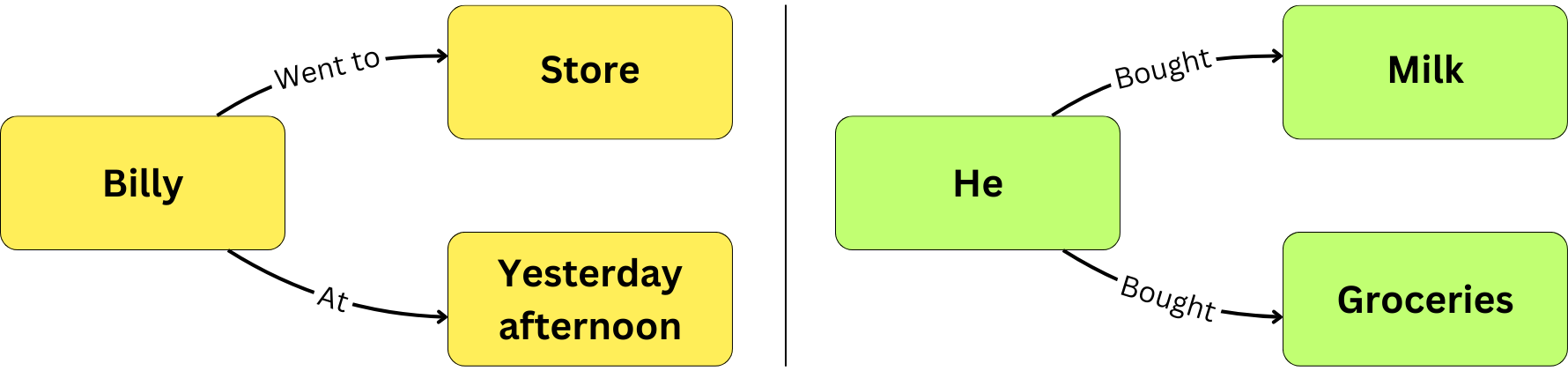
Whereas, in fact, the more accurate graphical representation of the information would be:
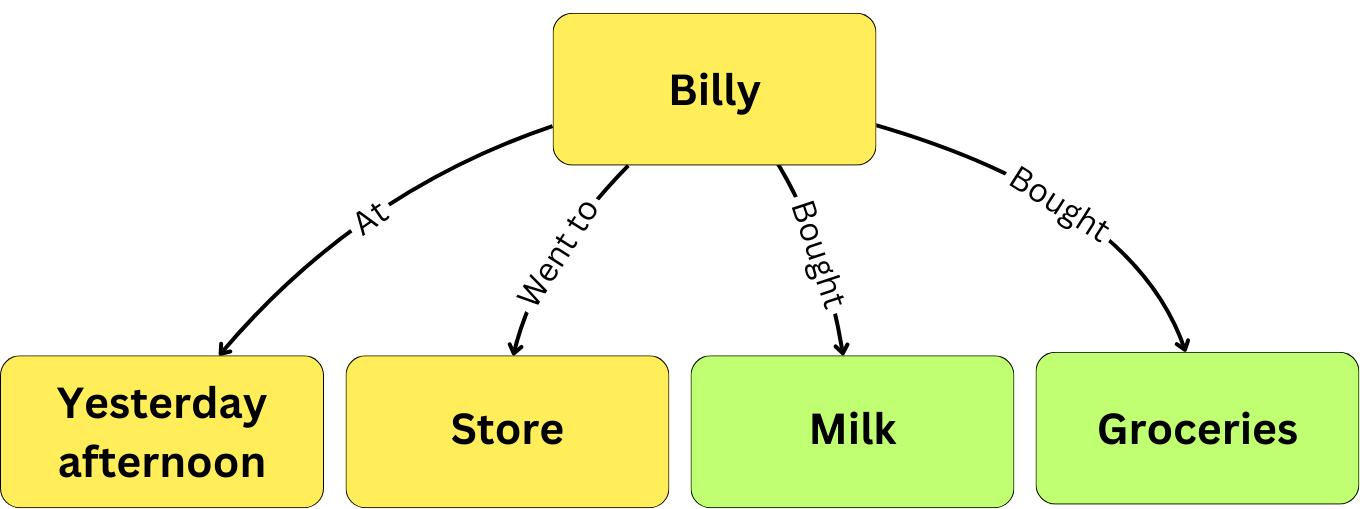
So, larger chunks are important to ensure that we can connect the different bits of information from one chunk to the next.
From Text Chunks to Element Instances
The next step is to extract the different entities and their relationships from the text chunks. From each chunk, we extract a list of entities with their description, and for each pair of entities, we extract their relationships. The result of this process is a list of triplets [Entity 1, Entity 2, relationship]. For example, here is the prompt used in GraphRAG (I removed most of the few-shot examples for space purposes):
-Goal- Given a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities. -Steps- 1. Identify all entities. For each identified entity, extract the following information: - entity_name: Name of the entity, capitalized - entity_type: One of the following types: [{entity_types}] - entity_description: Comprehensive description of the entity's attributes and activities Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>) 2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other. For each pair of related entities, extract the following information: - source_entity: name of the source entity, as identified in step 1 - target_entity: name of the target entity, as identified in step 1 - relationship_description: explanation as to why you think the source entity and the target entity are related to each other - relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>) 3. Return output in English as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter. 4. When finished, output {completion_delimiter} ###################### -Examples- ###################### Example 1: Entity_types: ORGANIZATION,PERSON Text: The Verdantis's Central Institution is scheduled to meet on Monday and Thursday, with the institution planning to release its latest policy decision on Thursday at 1:30 p.m. PDT, followed by a press conference where Central Institution Chair Martin Smith will take questions. Investors expect the Market Strategy Committee to hold its benchmark interest rate steady in a range of 3.5%-3.75%. ###################### Output: ("entity"{tuple_delimiter}CENTRAL INSTITUTION{tuple_delimiter}ORGANIZATION{tuple_delimiter}The Central Institution is the Federal Reserve of Verdantis, which is setting interest rates on Monday and Thursday) {record_delimiter} ("entity"{tuple_delimiter}MARTIN SMITH{tuple_delimiter}PERSON{tuple_delimiter}Martin Smith is the chair of the Central Institution) {record_delimiter} ("entity"{tuple_delimiter}MARKET STRATEGY COMMITTEE{tuple_delimiter}ORGANIZATION{tuple_delimiter}The Central Institution committee makes key decisions about interest rates and the growth of Verdantis's money supply) {record_delimiter} ("relationship"{tuple_delimiter}MARTIN SMITH{tuple_delimiter}CENTRAL INSTITUTION{tuple_delimiter}Martin Smith is the Chair of the Central Institution and will answer questions at a press conference{tuple_delimiter}9) {completion_delimiter} ###################### -Real Data- ###################### Entity_types: {entity_types} Text: {input_text} ###################### Output:
We can iterate through all the chunks available in our dataset and, little by little, extract the triplets from the text:

The descriptions will be used to construct more coherent summaries once we cluster the different nodes into communities.
This process is by far the costliest of the whole indexing pipeline. It is also prone to errors as the LLM extracts different nodes for the same entity due to the different lexical variations for one entity.
From Element Instances to Element Summaries
So far, we have extracted triplets from different text chunks. Because we want to be able to use the descriptions in an actionable manner, we need to merge together the different descriptions we captured for the same entities. By merging descriptions coming from different text chunks, we are going to be able to construct a more holistic view of each entity. To merge them, we can simply ask an LLM to summarize the concatenated descriptions.

Here is the prompt used in GraphRAG to merge the different descriptions together:
