

XGBoost MAY be all you need!
Well, it is true until it is not!

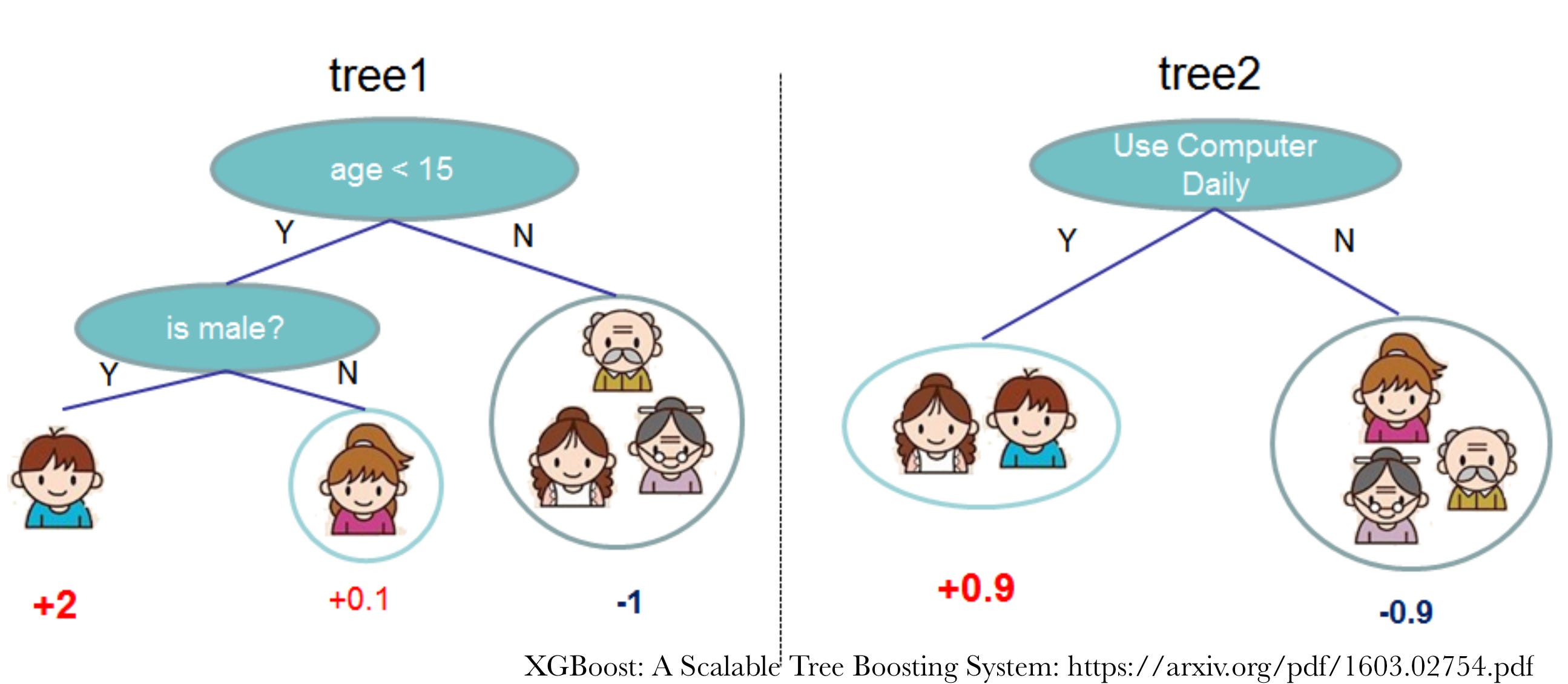
I never use Linear Regression! I am not saying you shouldn’t, I personally just never do. Actually there are many algorithms I never use: Logistic Regression, Naive Bayes, SVM, LDA, KNN, Feed Forward Neural Network,… I just don’t find value in those for my work.
I always say you should start any Machine Learning model development with a simple algorithm, but for me Logistic Regression (LogReg) or Linear Regression (LR) are not simple! The amount of feature engineering needed to get a performant model out of those algorithms is just too high to me. The simple use of those algorithms does not provide me with a useful minimum baseline I could work from. If I observe low predictive performance on a LR or LogReg with zero feature engineering, that is not informative enough for me to make a predictive power assessment of the underlying data.

For me the “simplest” model to use is XGBoost (this includes LightGBM or CatBoost of course). Well at least for tabular data. XGBoost natively handles missing values, categorical variables (to some extend!), it is parallelizable (so fast…enough), it trains on any loss function I may need, it tends to be robust to overfitting on a large number of features, and it is highly non-linear which makes it a very low bias algorithm. Its API is pretty complete, and you can achieve a lot by just changing a couple of arguments. I can easily throw any data into XGBoost without any work and that gives me a useful baseline that can drive my development from there.
Algorithms like Linear Regression have their number of degrees of freedom (d.o.f. - complexity) scaling with the number of features O(M). In practice, this means that their ability to learn from the data will plateau in the regime N >> M where N is the number of samples (typically large data sets). They have a high bias but a low variance and as such they are well adapted to the N > M regime. In the N < M regime, L1 regularization becomes necessary to learn the relevant features and zero-out the noise (think about having more unknowns than equations to solve a set of linear equations). Naive Bayes d.o.f. scales as O(C x M) (or O(M) depending on the implementation) where C is the number categories the features are discretized into. O(C) = O(N) in theory but not really in practice. This makes it a lower bias algorithm than LR but it is a product ensemble of univariate models and ignores the feature interactions (as LR does) preventing it from further improvements.
A tree in its unregularized form, is a low bias algorithm (you can overfit the data to death), with d.o.f scaling as O(N), but high variance (deep trees don’t generalize well). But because a tree can reduce its complexity as much as needed, it can work in the regime N < M by simply selecting the necessary features. A Random Forest is therefore a low bias algorithm but the ensemble averages away the variance (but deeper trees call for more trees) and it doesn’t overfit on the number of trees (Theorem 1.2 in the classic paper by Leo Breiman), so it is a lower variance algorithm. The homogenous learning (the trees tend to be similar) tends to limit its ability to learn on too much data.
XGBoost is the first (to my knowledge) tree algorithm to mathematically formalize regularization in a tree (eq. 2 in the XGBoost paper). It is a low bias and high variance (due to the boosting mechanism) and is therefore adapted to large data scales. The GBM Boosting mechanism ensures a more heterogenous learning than Random Forest and therefore adapts better to larger scales. The optimal regularization ensures higher quality trees as weak learners than in Random Forest and tends to be more robust to overfitting than Random Forest.
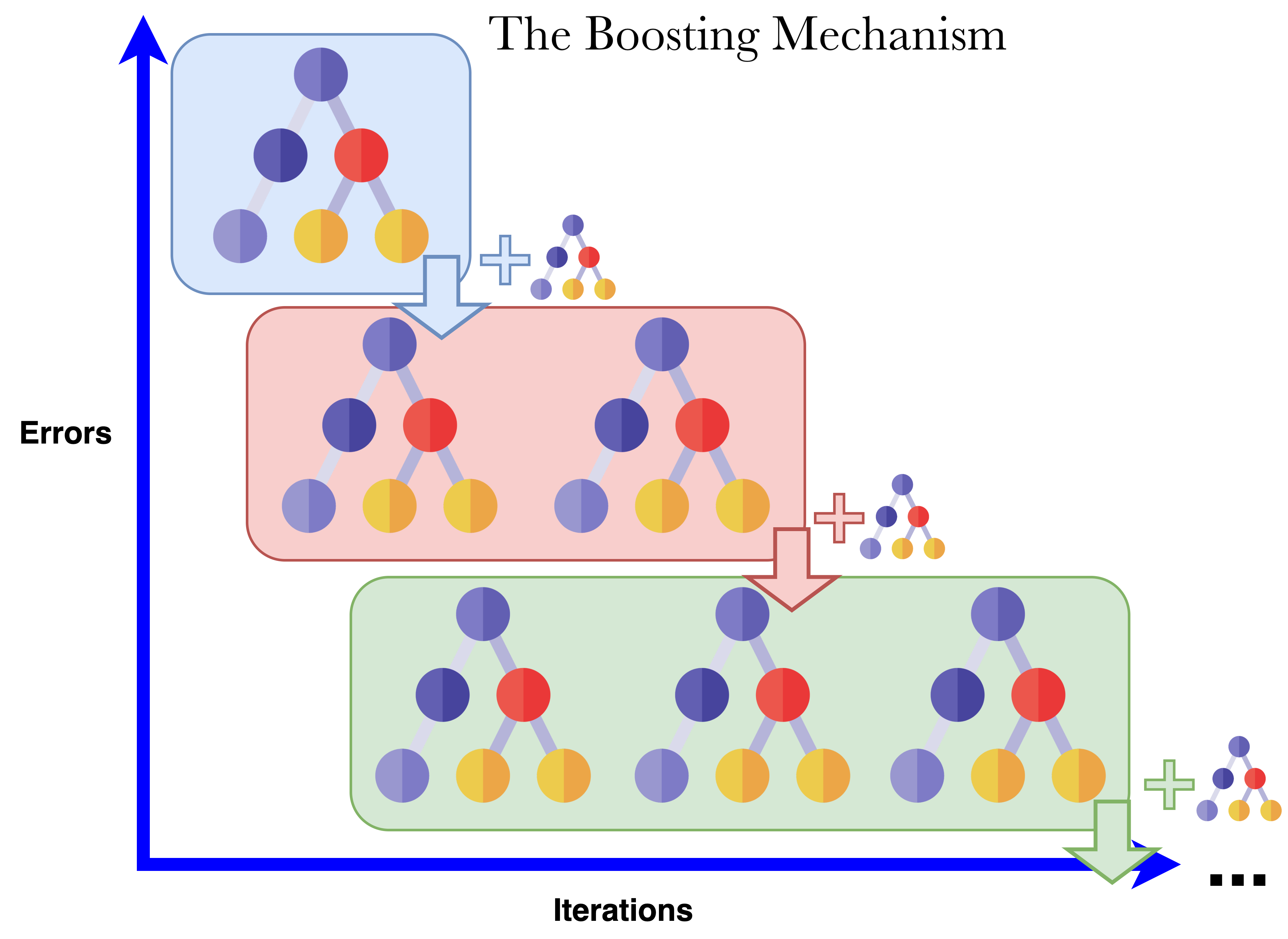
In the regime N >> M, only low bias algorithms make sense with d.o.f. scaling as O(N). That includes algorithms like GBM, RF, Neural Networks, SVM (gaussian), KNN,… SVM has a training time complexity of O(N^3) (unmanageable!) and KNN is bad at understanding what is an important feature and has dimensionality errors scaling as O(M). Neural Networks are known to underperform compared to XGBoost on tabular data ("Deep Learning is not all you need").
So, if you are working on large tabular data, XGBoost MAY be all you need! But make sure to prove it to yourself. The no Free-Lunch Theorem doesn’t mean we cannot understand our algorithms and build an intuition on what are the best use cases to use them!
XGBoost documentation: https://xgboost.readthedocs.io/en/stable/
LightGBM documentation: https://lightgbm.readthedocs.io/en/v3.3.2/
Catboost documentation: https://catboost.ai/
Random Forest by Leo Breiman: https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf
XGBoost: A Scalable Tree Boosting System by Tianqi Chen et al: https://arxiv.org/pdf/1603.02754.pdf
Tabular Data: Deep Learning is not all you need by Ravid Shwartz-Ziv et al: https://arxiv.org/pdf/2106.03253.pdf