

Deep Dive: How to Automate Writing Newsletters with LangChain, Stable Diffusion and DiaChat
Building Machine Learning Solutions

LangChain is certainly one of the most powerful technologies I came across recently. It allows to use Large Language Models as building blocks for software applications. Today I am exploring how much I can rely on ChatGPT and other generative AI tools to automate human-like activities such as writing a newsletter about the past week's news. We cover:
A newsletter fully generated by AI
Getting the top news
The NewsAPI API
Selecting the top news with ChatGPT
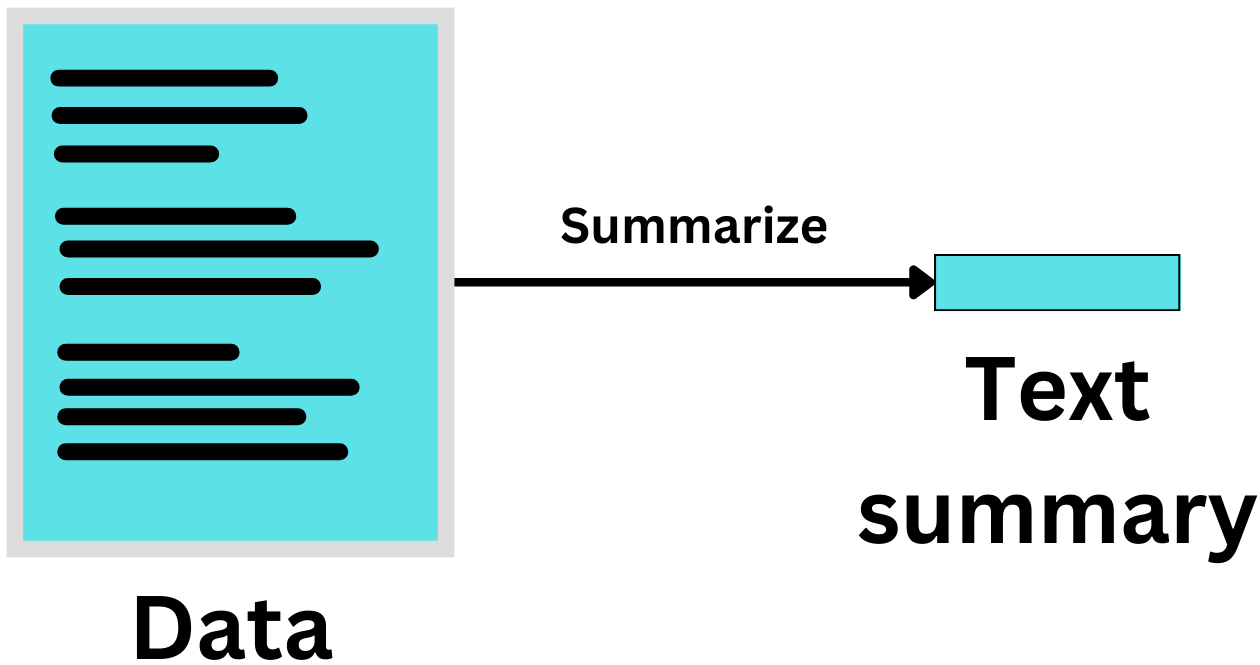
Summarizing the news
Extracting the news text
Summarizing the text with LangChain
Generating images with Stable Diffusion
The Stable Diffusion API
Generating images for the summaries
Illustrating with a diagram using DiaChat
Generating a title and abstract
The abstract
The title
A newsletter fully generated by AI

I have been thinking about writing newsletters to capture the latest news about Machine Learning for a while now, but I was having difficulties finding the time to do it. Therefore, I created a software that automates this process! Here is an example of such a newsletter:

I will refine the process over time, but I am curious, would you be interested if I sent such a newsletter every week?
Now let's get into how to build such an automation! Make sure to install the necessary libraries and set up your OpenAI API key on their platform:
pip install langchain openai newsapi-python beautifulsoup4Getting the top news
The NewsAPI API
I want to highlight the most interesting news about Machine Learning in the past week. I use NewsAPI to access the news. Login and get your API key. You can find documentation of the Python client library here:

Let’s get all the news about “Artificial Intelligence“ from the past week:
from newsapi import NewsApiClient
newsapi = NewsApiClient(api_key=NEWS_API_KEY)
everything = newsapi.get_everything(
q='artificial intelligence',
from_param='2023-05-22',
to='2023-05-29',
sort_by='relevancy',
language='en'
)
everything['articles'][0]
The free plan only provides a maximum of 100 articles but it is enough to find interesting articles. I could have sorted the results by “popularity“ as well, but I was afraid of getting too many irrelevant articles.
Selecting the top news
100 articles is too many to highlight in a newsletter, so I will select only 10 of them. Because I am lazy, I will ask ChatGPT to find the most appropriate ones for me! I use LangChain to do so.
I am creating the following prompt template so I can rerun the code multiple times with different arguments. I am asking it to extract the 10 most important news about machine learning and return it as a Python list. This is so I can directly use the results in a script:
from langchain import PromptTemplate
top_news_template = """
extract from the following list the 10 most important news about machine learning. Return the answer as a python list.
For example: ['text 1', 'text 2', 'text 3']
{list}
"""
TOP_NEWS_PROMPT = PromptTemplate(
input_variables=['list'],
template=top_news_template,
)In the above prompt, I had to show it an example (few-shot prompting) as it sometimes failed to return the result as a Python list. I can now create a simple chain with ChatGPT as the model:
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
chain = LLMChain(
llm=llm,
prompt=TOP_NEWS_PROMPT
)For the list, I will use article titles. One can argue it is not the most effective way to select relevant news but it is a first pass at getting us there
title_list = '\n'.join([
article['title']
for article in everything['articles']
])
title_list 
Let’s run that and convert the result into a Python list so we can use it later:
import ast
# We send the prompt to ChatGPT
top_str = chain.run(title_list)
# And we convert the result as a python list
top_list = ast.literal_eval(top_str)
top_list
Let’s match those titles with the related URLs:
top_news = [
{
'title': a['title'],
'url': a['url']
}
for a in everything['articles']
if a['title'] in top_list
]
top_news
Obviously I am giving a lot of confidence in ChatGPT’s ability to return the data in the right format. If it was a more formal software development, I would be less relaxed about it.
Summarizing the news
Extracting the news text
I would like to provide a summary of each of the selected articles. I will extract the text of the related articles and summarize them. We can easily extract the text using the URL using Beautiful Soup:
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = 'https://www.wired.com/story/generative-ai-podcasts-boring/'
page = urlopen(url)
html = page.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
soup.get_text()
Let’s apply that to all the URLs
def get_text(url):
page = urlopen(url)
html = page.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
return soup.get_text()
for news_dict in top_news:
try:
text = get_text(news_dict['url'])
news_dict['text'] = text
except:
news_dict['text'] = NoneSummarizing the text
To summarize text with a LLM, there are a few strategies. If the whole text fits in the context window, then you can simply feed the raw data and get the result. LangChain refers to that strategy as the “stuff“ chain type:
Often, the number of tokens contained in the text is larger than the LLM's maximum capacity. A typical strategy is to break down the data into multiple chunks, summarize each chunk, and summarize the concatenated summaries in a final "combine" step. LangChain refers to this strategy as “map-reduce“:

Another strategy is to begin the summary with the first chunk and refine it little by little with each of the following chunks:

LangChain refers to this as “refine“. For example here is the prompt template used by LangChain for the refine step:
Your job is to produce a final summary
We have provided an existing summary up to a certain point: {existing_answer}
We have the opportunity to refine the existing summary
(only if needed) with some more context below.
------------
{text}
------------
Given the new context, refine the original summary
If the context isn't useful, return the original summary.You can learn more about it here. I am using the map-reduce strategy as I found it more robust for my use case. I slightly modified the prompt template to make it work better for what I need:
combine_template = """
Your job is to produce a concise summary of a news article about Machine Learning
Provide the important points and explain why they matter
The summary is for a blog so it has to be exciting to read
Write a concise summary of the following:
{text}
CONCISE SUMMARY:
"""
combine_prompt = PromptTemplate(
template=combine_template,
input_variables=['text']
)We can now split the data and create a summary chain
from langchain.text_splitter import CharacterTextSplitter
from langchain.docstore.document import Document
from langchain.chains.summarize import load_summarize_chain
def get_summary(text):
char_text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0
)
# we need to cast the data as a Document
doc = [Document(page_content=text)]
# we split the data into multiple chunks
docs = char_text_splitter.split_documents(doc)
# we load the chain with ChatGPT
llm = ChatOpenAI()
chain = load_summarize_chain(
llm=llm,
chain_type='map_reduce',
combine_prompt=combine_prompt
)
summary = chain.run(docs)
return summaryAnd we can easily summarize each article
for news_dict in top_news:
try:
summary = get_summary(news_dict['text'])
news_dict['summary'] = summary
except Exception as e:
news_dict['summary'] = None
top_news[0]['summary']
> 'Startups are creating tools to generate AI voices, leading to the emergence of AI-generated podcasts. While some believe it could appeal to independent creators, human podcasters are skeptical and believe listeners want to connect with the people behind the microphone. The podcast industry is built on conversation and intimacy, which AI-generated podcasts may struggle to replicate.'Generating images with Stable Diffusion
The Stable Diffusion API
It is always more fun to have a newsletter with images. Let’s use Stable Diffusion to generate some with the StableDiffusion API. Register and get your API key:

We can query that API with the requests package
import requests
import json
url = 'https://stablediffusionapi.com/api/v3/text2img'
data = {
'key': API_KEY,
'width': '1024',
'height': '512',
'prompt': 'A man on the moon'
}
headers = {
'Content-Type': 'application/json'
}
response = requests.post(
url,
data=json.dumps(data),
headers=headers
)
response.json()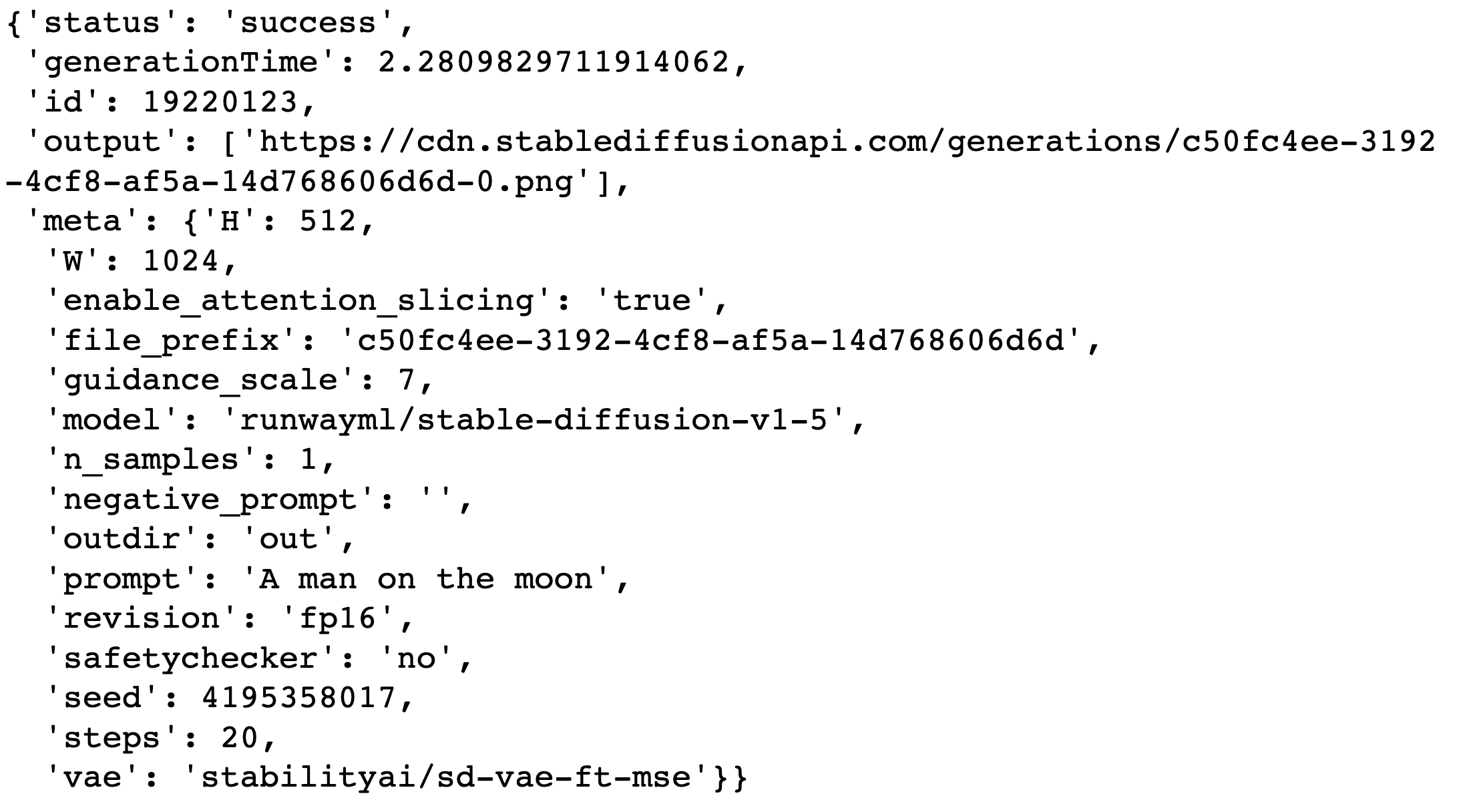
We can download the image using the following script:
image_url = response.json()['output'][0]
output_path = 'man_on_the_moon.png'
img_data = requests.get(image_url).content
with open(output_path, 'wb') as handler:
handler.write(img_data)
Generating images for the summaries
I would like to illustrate each summary with an image. Let’s wrap those API calls into functions:
def submit_post(url, data):
headers = {
'Content-Type': 'application/json'
}
return requests.post(
url,
data=json.dumps(data),
headers=headers
)
def save_image(image_url, output_path):
img_data = requests.get(image_url).content
with open(output_path, 'wb') as handler:
handler.write(img_data)And loop through our data
for news in top_news:
data['prompt'] = news['summary']
file_name = './data_news/{}.png'.format(news['title'])
try:
response = submit_post(url, data)
save_encoded_image(response.json()['output'][0], file_name)
except Exception as e:
passFor example the following prompt
Startups have introduced easy-to-use tools for generating AI voices, leading to the creation of AI-generated podcasts. However, creators are uncertain about their appeal to listeners and consider them a byproduct of experimentation. AI editing tools are frequently used by major podcasting studios, but the idea of AI-generated presenters replicating the experience of human presenters is still considered pure science fiction. AI podcasts are a tiny bubble within the larger market for generative AI products and services.leads to the following image:

Illustrating with a diagram using DiaChat
I like to have diagrams to explain the text. Looking back, I probably wouldn't use those for weekly news insights. They could be better adapted to illustrate tutorials but I am happy to introduce this feature here. Let’s use DiaChat to convert the summaries into diagrams. Unfortunately, there is no API yet so we need to navigate through the website. We manually input the summary:

And download the image:

This is definitively more manual work than I prefer, so I will need to refine this step in the future.
Generating a title and abstract
The abstract
The final steps are to present the newsletter to the reader in an exciting manner with a title and an abstract. For the abstract, we use simple chain with the following prompt template:
abstract_template = """
Use the following articles summaries to generate a 2 or 3 sentences abstract for a blog about Machine Learning.
Those articles are the most impactful news of the past week from May 22nd 2023 to May 30th 2023
{summaries}
"""
ABSTRACT_PROMPT = PromptTemplate(
input_variables=['summaries'],
template=abstract_template,
)Let’s run the chain:
llm = ChatOpenAI()
chain = LLMChain(
llm=llm,
prompt=ABSTRACT_PROMPT
)
summaries = '\n\n'.join([
news['title'] + '\n' + news['summary']
for news in top_news
])
abstract = chain.run(summaries)
abstract
> "Last week in the world of Machine Learning, there were various developments across different industries. Startups have introduced easy-to-use tools for generating AI voices leading to the creation of AI-generated podcasts. At the same time, Adobe has introduced a new AI tool called Generative Fill in Photoshop that can add or remove elements from an image instantly or extend a picture from a text prompt. AI can help fight climate change, but it must be implemented carefully to avoid exacerbating inequalities. In another development, IBM Consulting has launched a Center of Excellence for generative AI aimed at helping businesses transform their operations by providing clients with access to IBM's AI technology and expertise."The title
Foe the title, a simple chain with the following template will suffice
title_template = """
Use the following articles summaries to generate a title a blog about Machine Learning.
Those articles are the most impactful news of the past week from May 22nd 2023 to May 30th 2023.
The title needs to be appealing such that people are excited to read the blog.
{summaries}
"""
TITLE_PROMPT = PromptTemplate(
input_variables=['summaries'],
template=title_template,
)We run the chain
chain = LLMChain(
llm=llm,
prompt=TITLE_PROMPT
)
title = chain.run(summaries)
title
> "The Future of AI: From Generative Podcasts to Climate Change Solutions"Here you go! We have all the necessary pieces to automate writing a newsletter summarizing the latest Machine Learning news.
That’s all Folks!

Excellent
I'm thrilled about the in-depth content and genuinely believe that this is where your content excels. I've unsubscribed from numerous subscriptions because I wasn't gaining practical knowledge that I could apply in my work. Many newsletters simply repeated the same news or listed new AI tools, so I had to remove myself to maintain my focus on my actual profession, which is Cloud Security. However, this deep dive opportunity couldn't have come at a better time. I had been contemplating doing something similar myself, but I lacked the time to start from scratch and learn everything. Fortunately, your deep dive provides a solution, and I am truly grateful for it.