

Deep Dive: Modeling Customers Loan Default with Markov Chains
Deep Dive in Data Science Fundamentals

Sometimes machine learning is not the answer. More often than not actually! Knowing the mechanisms of a system, we can construct models that answer certain quantitative questions more effectively. In this letter, we look at the customer loan payment process and model it with Markov Chains. We look at:
Customer credit mechanisms
We create synthetic data to study the mechanisms
The Markov Chain probability transition matrix
The expected number of steps from state i to state j
Estimating the probability transition matrix for a specific customer with Laplace smoothing

This Deep Dive is part of the Data Science Fundamentals series.
Previous: Social Network Data Visualization
Customer credit mechanisms
I once worked in a company that allowed to buy products with a credit. For example, if you wanted to buy a $1,000 couch, you could get it right away, but you would need to repay it with monthly payments, let’s say $100 per month. If you were behind on your payments, you would transition to a “warning” state. If you were late 7 times in a row, the case would be sent to a collection agency to collect the debt, and the customer’s account would be closed. If you think about the number of times the customer is late as a state, the 7th state is a state you cannot return to. In Markov Chain jargon, this is called an absorbing state.
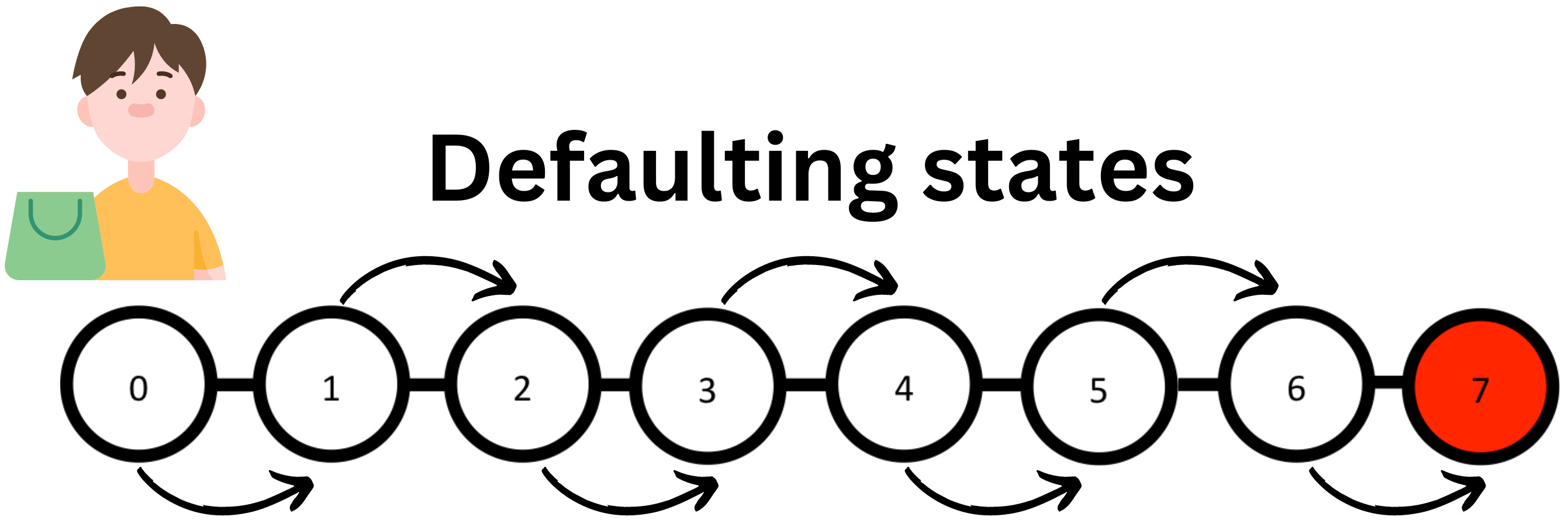
The process rules are as follows:
As a starting point, every user is in state 0.
For simplicity, we assume that the user can only move down or up one state or remain in the same state each month. If the user is late twice in a row, he moves to the next state. If he pays the current monthly installment, he remains in the same state. If he pays the current and the previous amount, he returns to the previous state.
Once state 7 is reached, the user cannot move again. It is an absorbing state. All other states are transient states.
A question you may ask:
If the customer is a state i today and knowing the payment history of that user, what is the probability that this customer will default 6 months from now?
Answering those types of questions may help understand the credit loan cost. We will try to answer those questions using the Markov Chain formulation. If we have data, we could be tempted to solve those questions using a Machine Learning approach. However, knowing the mechanisms behind the process allows us to build a more accurate model.
Let’s create some synthetic data
As we do not have access to such processes, let's create some synthetic data instead. We start by creating 1000 customers' unique identifiers
customers = ["UID" + str(i) for i in range(1000)]
customers
We now create a range of date between January 2019 and January 2023.
import pandas as pd
dates = pd.date_range('2019-01', '2023-01', freq='M')
dates
Let’s make sure that range is the same for every customer
from itertools import product
customer_df = pd.DataFrame(
product(customers, dates),
columns=['CustomerID', 'Date']
).sort_values(by=['CustomerID', 'Date'])
customer_df
We now write a function that takes the current state as an argument, and returns the next state. The next state is chosen randomly to mimic the customer's behavior
import numpy as np
def get_next_state(current_state):
# if the current state is 7, the customer
# cannot go to any other state
if current_state == 7:
return 7
# the only accessible states are the lower one,
# the current one and the one above
if current_state == 0:
possible_states = [
current_state,
current_state + 1
]
else:
possible_states = [
current_state - 1,
current_state,
current_state + 1
]
# we draw probabilities at random and we normalize them to 1
probas = np.random.uniform(size=len(possible_states))
probas /= sum(probas)
# we draw the next state at random using those probabilities
next_state = np.random.choice(possible_states, p=probas)
return next_stateWe now write a function that returns the path of states for all the dates
def get_states_path(dates):
num = dates.shape[0]
# each user starts at the state 0
current_state = 0
# we initiate the states path
states = [current_state]
for i in range(num-1):
# we get the next state from the current one
next_state = get_next_state(current_state)
# we append it to the states path
states.append(next_state)
# the next state becomes the current
# one for the next iteration of the loop
current_state = next_state
return statesWe can now append a new “State“ column to the customer_df data frame
customer_df['State'] = customer_df
.groupby('CustomerID')['Date']
.transform(get_states_path)
customer_df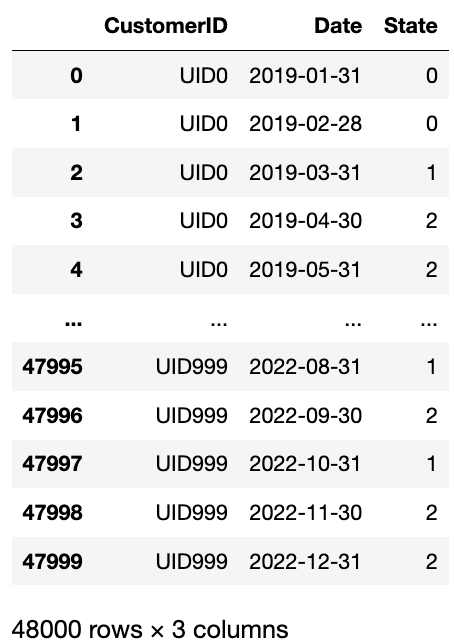
This works because we ordered the data frame by dates. Let’s visualize a few customer paths
customer_df.pivot(
index='Date',
columns='CustomerID',
values='State'
).sample(10, axis=1).plot()
The Markov Chain probability transition matrix
We have enough data to study the system. Let’s look at the probability of transitioning from one state to another. For each date, we get the state of the next date
customer_df['Next_State'] = customer_df
.groupby(['CustomerID'])['State']
.shift(-1)
Again, this works because we ordered the data frame by dates. We then compute the transition matrix
P_avg = pd.crosstab(
customer_df['State'],
customer_df['Next_State'],
normalize=0 # probabilities sum to 1
)
P_avg
The probability transition matrix has the following form
Where
Q is a matrix of the probabilities of moving from a transient state to another transient state.
Ir is the identity matrix, which holds the probabilities of transitioning between absorbing states (which is impossible as we just get stuck in the same absorbing state).
R is the matrix which holds the probabilities of moving from a transient state to an absorbing state.
0 represents the matrix of probabilities of moving from an absorbing state to a transient state (which is impossible).
