

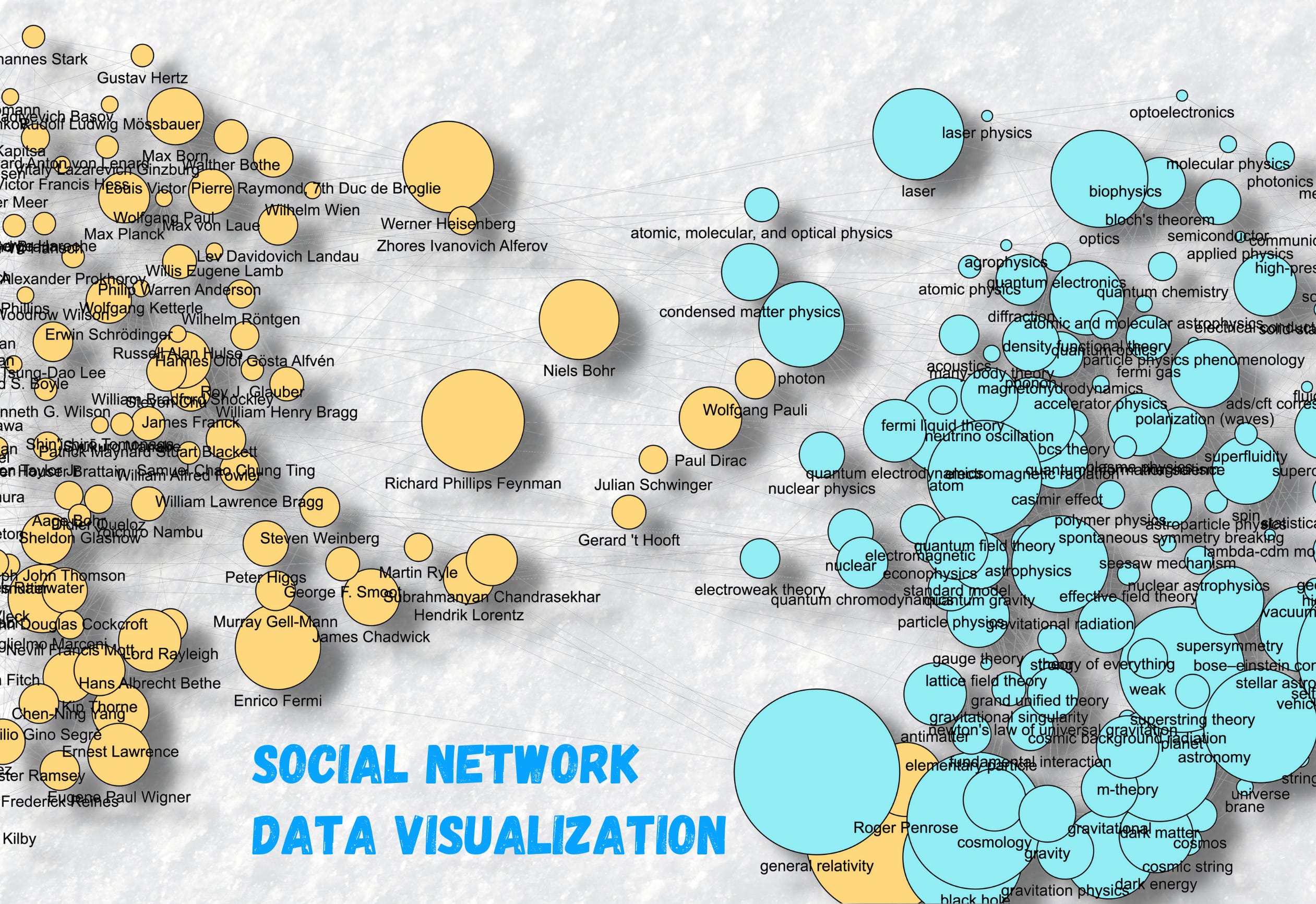
Social Network Data Visualization
Deep Dive in Data Science Fundamentals

In this Deep Dive, we are going to reuse the data set of a previous Deep Dive (see Scrapping the Web for NLP applications) to look at it from a Social Network perspective. A social network is a construct where social actors can be represented as nodes linked by edges on a graph. We are going to:
Get the data
Compute the nodes data
Compute the edges data
Plot the network
This Deep Dive is part of the Data Science Fundamentals series.
Introduction
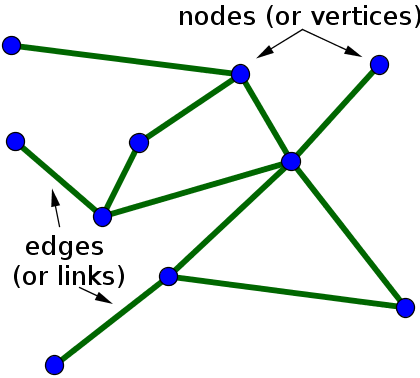
A social network can be represented as a graph with a set of nodes and a set of links between those nodes:
In a previous post (see Scrapping the Web for NLP applications), we scrapped a Physics Nobel prize laureate dataset from Wikipedia. If we consider each physicist and each physics domain as a possible node on a network, the problem becomes building edges between those. Here is an example of how to represent graphs with Python data structures using the Python package Gravis:
import gravis as gv
small_network = {
'graph':{
'directed': False,
'metadata': {
'edge_size': 3,
'node_size': 30,
'node_color': 'blue',
},
'nodes': [
{'id': 0, 'label': 'Albert Einstein'},
{'id': 1, 'label': 'Paul Dirac'},
{'id': 2, 'label': 'Niels Bohr'}
],
'edges': [
{'source': 0, 'target': 1},
{'source': 0, 'target': 2},
{'source': 1, 'target': 2}
],
}
}
# plot a d3 Force-directed graph
gv.d3(small_network, node_label_data_source='label')
Obviously, that is not a very interesting network and we are going to build a more substantial one! Gravis expects the data in a specific format as shown above and we are going to shape our data to follow those requirements. For each node, we need an “id” tag and a label, and we can add other attributes if we desire. For the edges, we need a “source” and a “target” to connect nodes and we can add other attributes as well. See the final result in the following video (only visible on the web app):
Getting and cleaning the Data
We are first going to gather the data needed for this project. We are going to get the data of all the Nobel price laureates in Physics from Wikipedia. We follow the same steps shown in the previous post Scrapping the Web for NLP applications. Go back to that previous post for a refresher on the code.
Getting the Nobel prize laureate data
First we write the functions we need
import pandas as pd
from httplib2 import Http
from bs4 import BeautifulSoup, SoupStrainer
import nltk
from nltk.corpus import stopwords
import re
nltk.download('stopwords')
stopwords.words('english')
# we create a special string for a regex matching
to_remove = '|'.join(stopwords.words('english'))
# wordnet is necessary to use lemmatization
nltk.download('wordnet')
# Will Extract the text associated to every link
def get_text(link, root_website = 'https://en.wikipedia.org'):
http = Http()
status, response = http.request(root_website + link)
body = BeautifulSoup(
response,
'lxml',
parse_only=SoupStrainer('div', {'id':'mw-content-text'})
)
return BeautifulSoup.get_text(body.contents[1])
# this will break the sentences into word tokens
w_tokenizer = nltk.tokenize.WhitespaceTokenizer()
lemmatizer = nltk.stem.WordNetLemmatizer()
# we lemmatize and convert to lower case
def lemmatize_text(text):
return [
lemmatizer.lemmatize(w).lower()
for w in w_tokenizer.tokenize(text)
]We get the Nobel prize laureates
url = "https://en.wikipedia.org/wiki/List_of_Nobel_laureates_in_Physics"
nobel_tables = pd.read_html(url)
nobel_df = nobel_tables[0]
# drop uncessecary columns
nobel_df.drop(['Image', 'Ref'], axis=1, inplace=True)
# Clean the columns names
nobel_df.columns = ['Year', 'Laureate', 'Country', 'Rationale']
# drop all the rows where the nobel price was not awarded
nobel_df = nobel_df.loc[
~nobel_df['Laureate'].str.startswith('Not awarded')
]
# we remove anything within parenthesis using regex
nobel_df['Laureate'] = nobel_df['Laureate'].str.replace(
'\(.+?\)', '', regex=True
)
# we remove the unnecessary white spaces
nobel_df['Laureate'] = nobel_df['Laureate'].str.strip()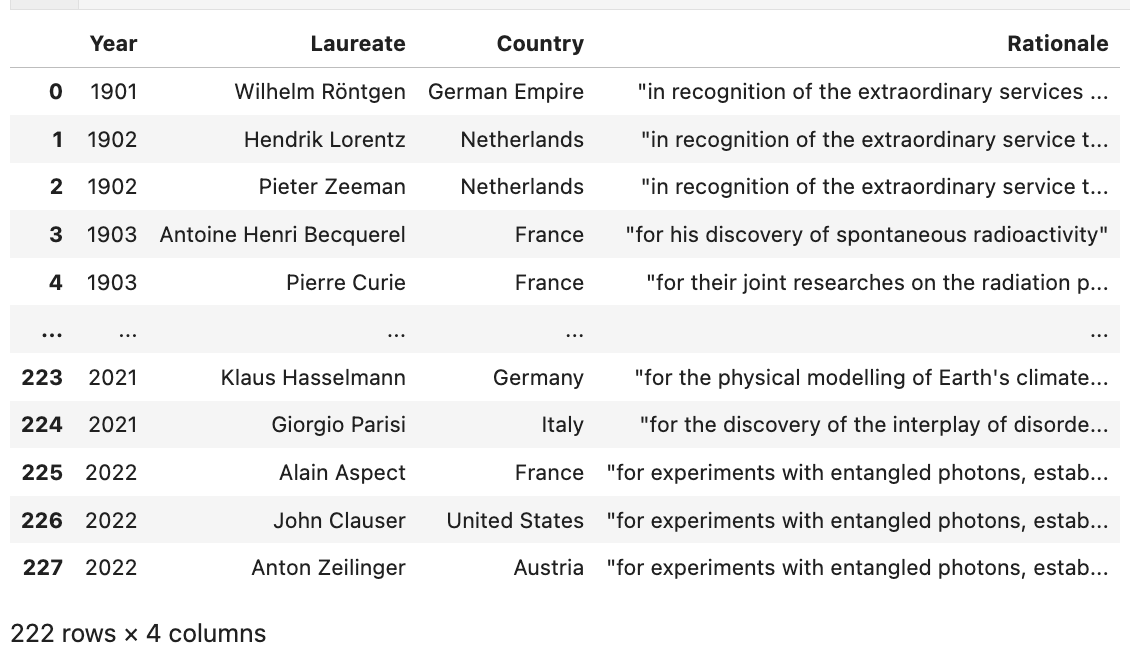
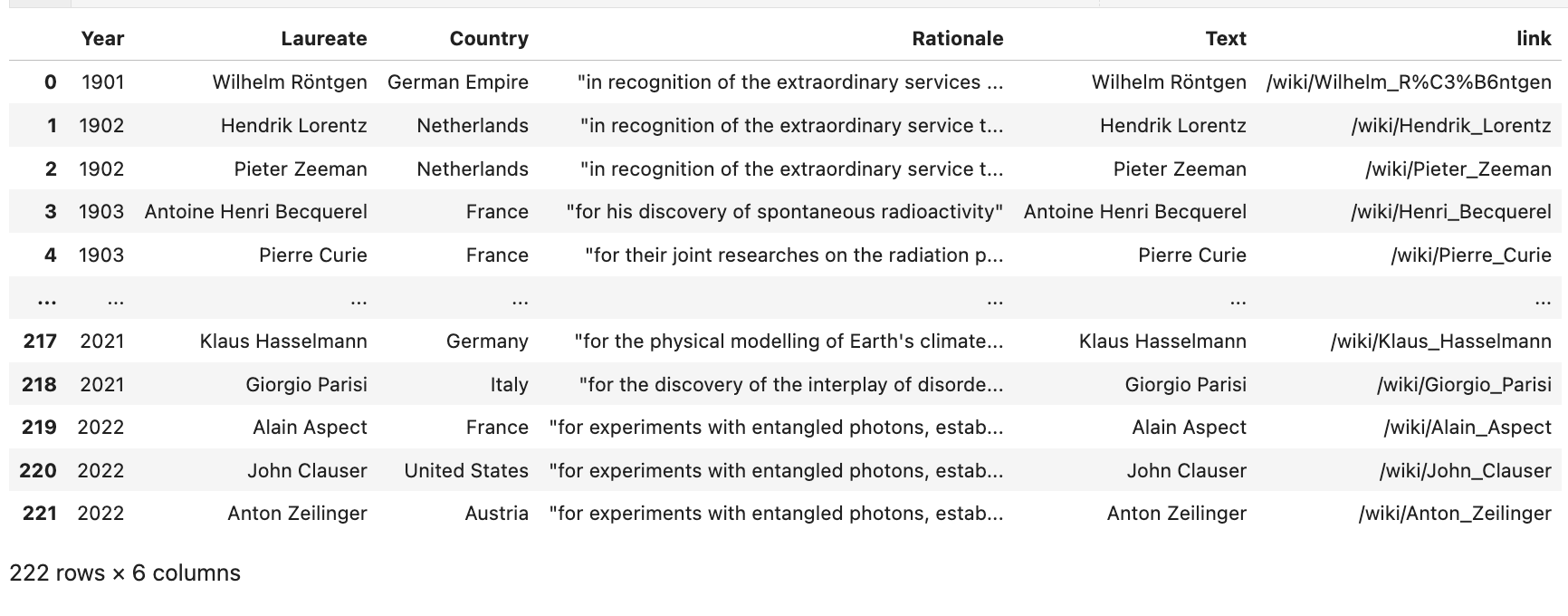
We get the links
# we pull the html code from the url
http = Http()
status, response = http.request(url)
# and extract only the tables
table = BeautifulSoup(
response,
'lxml',
parse_only=SoupStrainer('table')
)
link_df = pd.DataFrame([
[x.string, x['href']] for x in table.contents[1].find_all('a')],
columns=['Text', 'link']
).drop_duplicates()
# merge nobel_df and link_df into nobel_merged_df
nobel_merged_df = nobel_df.merge(
link_df,
left_on='Laureate',
right_on='Text',
how='left'
)
We now pull the bios and clean them into a bag of words
# extract the text of the wikipedia page associated to each physicist
nobel_merged_df.set_index('Laureate', inplace=True)
nobel_merged_df['bio_data'] = nobel_merged_df.apply(
lambda x: get_text(x['link']), 1
).str.replace(
'[^\w\s]', ' ', regex=True
).str.replace(
'[0-9]', ' ', regex=True
).str.replace(
'\s+', ' ', regex=True
).str.replace(
r'\b({})\b'.format(to_remove), ' ',
regex=True,
flags=re.IGNORECASE
).str.replace(
'\s+', ' ', regex=True
).str.strip().apply(
lemmatize_text
)
nobel_merged_df['bio_data']
Getting the physics domain data
We now get the physics domains data
# We get the physics links
url = 'https://en.wikipedia.org/wiki/Physics'
http = Http()
status, response = http.request(url)
table = BeautifulSoup(
response,
'lxml',
parse_only=SoupStrainer('table')
)
physics_df = pd.DataFrame(
[[x.string.lower(), x['href'].lower()] for x in table.contents[3].find_all('a')],
columns=['Physics_domain', 'link']
).drop_duplicates()
physics_df = physics_df.groupby('Physics_domain').first()
physics_df
And we create the bag of words for the physics domains:
# we apply all the functions previously used
physics_df['text_data'] = physics_df.apply(
lambda x: get_text(x['link']), 1
).str.replace(
'[^\w\s]', ' ', regex=True
).str.replace(
'[0-9]', ' ', regex=True
).str.replace(
'\s+', ' ', regex=True
).str.replace(
r'\b({})\b'.format(to_remove), ' ',
regex=True,
flags=re.IGNORECASE
).str.replace(
'\s+', ' ', regex=True
).str.strip().apply(
lemmatize_text
)
physics_df['text_data']
Filter the data
To improve the analysis, we are remove words that may be less relevant to physics by building a physics corpus and removing words from the physicists’ biographies that don’t belong to that corpus.
To build a physics corpus, we just find all the words that belong in the physics domain bags of words and all the words that belong to physicist biographies bags of words.
We take the intersection of those 2 sets
# find all the words in nobel_merged_df['bio_data']
all_nobel_words = set(nobel_merged_df['bio_data'].sum())
# find all the words in physics_df['text_data']
all_physics_words = set(physics_df['text_data'].sum())
# get intersection of all_nobel_words and all_physics_words
physics_corpus = all_nobel_words.intersection(all_physics_words)
physics_corpus
We filter the text data using that corpus:
# function that keep only specific words from a list
def keep_only(list_to_clean, corpus=physics_corpus):
return [e for e in list_to_clean if e in corpus]
# filter physicists' bags of words
nobel_merged_df['bio_data_clean'] = nobel_merged_df['bio_data'].apply(
keep_only
)
# filter physics domains' bags of words
physics_df['text_data_clean'] = physics_df['text_data'].apply(
keep_only
)
nobel_merged_df
Compute the nodes data
Each physicist and physics domain is going to represent a node in the social network. Recall that we need an “id“ and “label“ attribute. The “id“ attribute will simply be the row number, and the “label“ will be the name of the physicist or physics domain. Additionally, we are going to compute an attribute “length“ to represent the size of the node, and an attribute “group“ to represent the color of the node.
For the “length”, we can simply count the number of words in the bag of words. The number of words in a Wikipedia page can be a proxy to capture how important is the physicist or physics domain. For the “group“, we are going to put the physicists in the group 1 and the physics domains in the group 0
# compute the length of each list
nobel_merged_df['length'] = nobel_merged_df['bio_data_clean'].apply(len)
physics_df['length'] = physics_df['text_data_clean'].apply(len)
# Set this column to 1
nobel_merged_df['group'] = 1
# Set this column to 0
physics_df['group'] = 0
nobel_merged_df[['length', 'group']]
