


Language Modeling
Sequence Prediction
Text Classification
Text Encoding
Multimodal Fine-Tuning
Catastrophic forgetting
LoRA Adapters
QLoRA
LoRA and QLoRA with the PEFT Package
Fine-tuning a model means we continue the training on a specialized dataset for a specialized learning task. There might be many different learning tasks involved when we consider LLMs. For example:
For Language modeling
For Sentence prediction
For Text classification
For Token classification
For Text encoding
For Multimodal modeling
Language Modeling
Language modeling means that we train the model to complete the input text. The goal is mostly to train the model to learn the relationship between the different words in the texts we generate as humans. There are typically two strategies for language modeling: causal language modeling and masked language modeling.
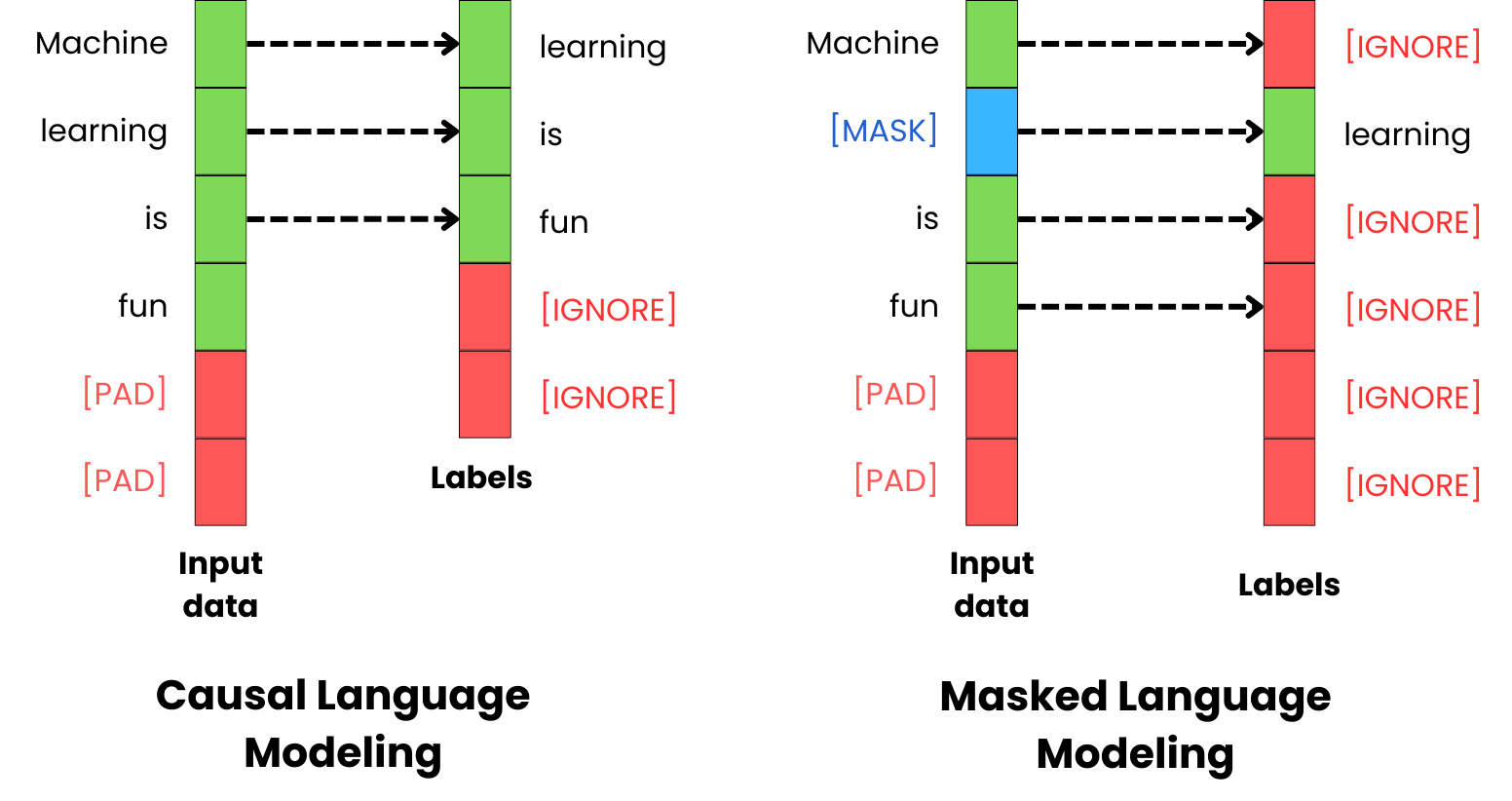
With causal language modeling, we train the model to predict the next token in a sequence based on the previous tokens. We have two strategies to achieve this. First, we use as the labels the shifted input tokens by one token.
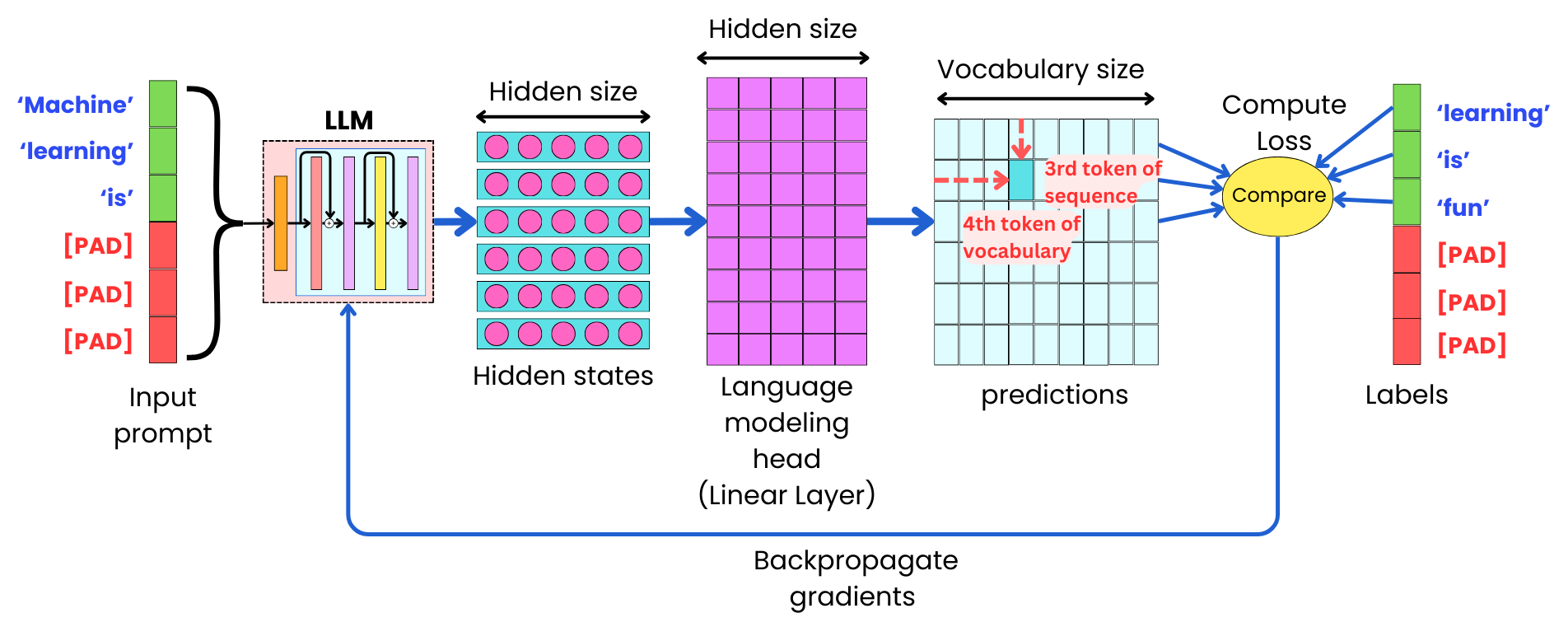
Every token, up to the current token, is used to learn to predict the following token. The loss function is computed by comparing the prediction of the next tokens with the actual values of the next tokens.
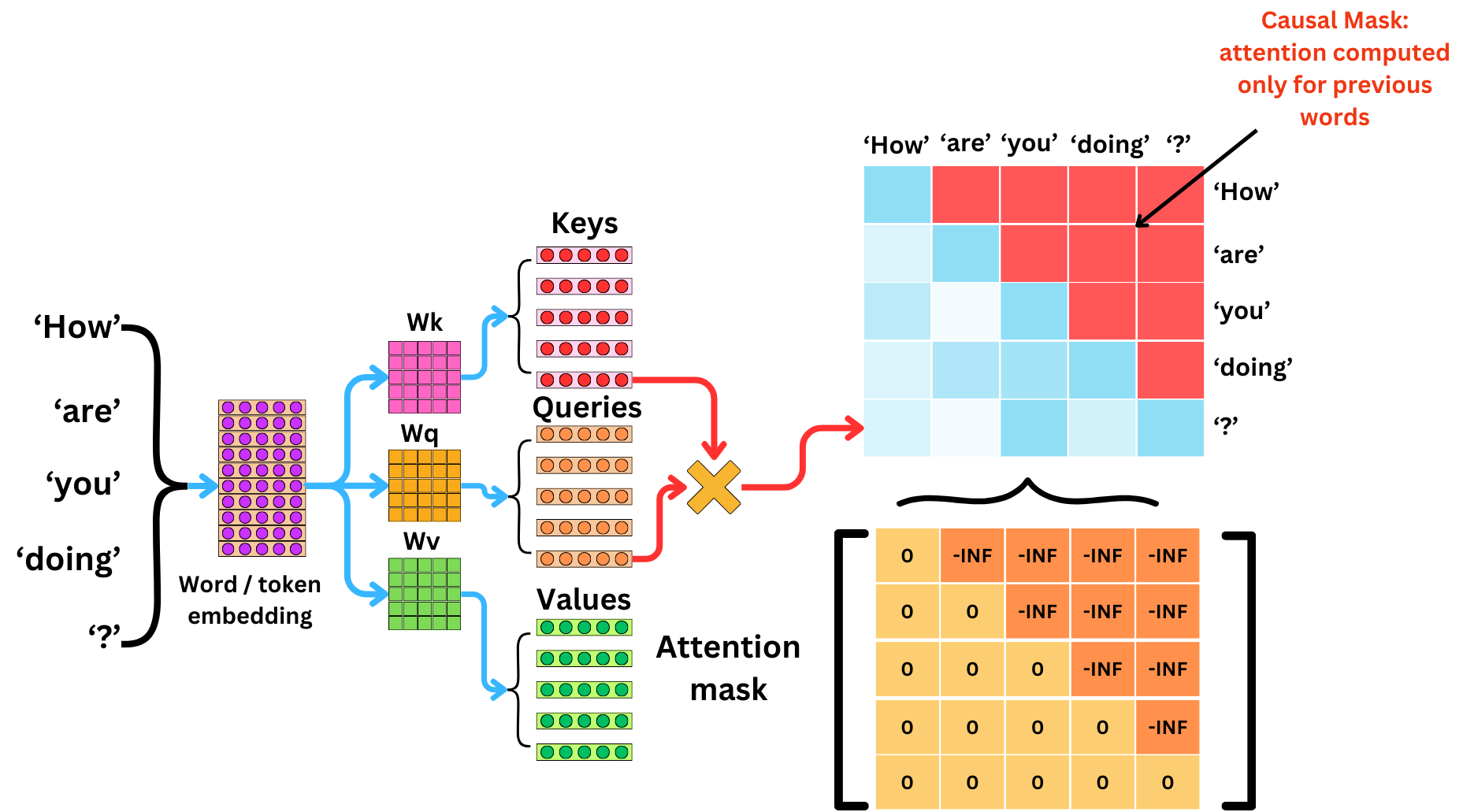
The second aspect is the causal mask that ensures that only the previous and current tokens are used to predict the following token. In the training data, all the tokens are present, and without a causal mask, the model can use the tokens that happen later in the text to predict past tokens. This would not be consistent with the fact that causal LLMs are used in an autoregressive manner to decode text one token after the next.
With masked language modeling, we remove some of the input tokens at random and use those masked tokens as label tokens. The model is trained to learn to reconstruct the masked tokens.
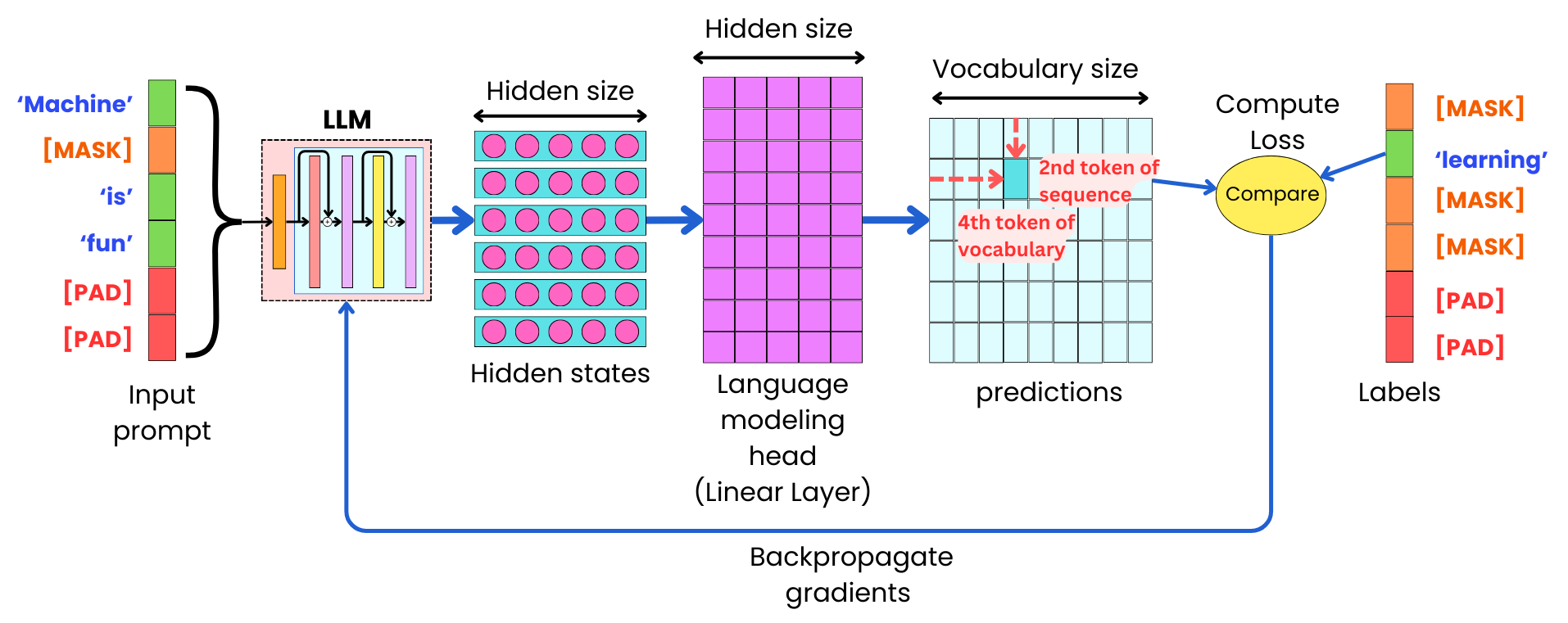
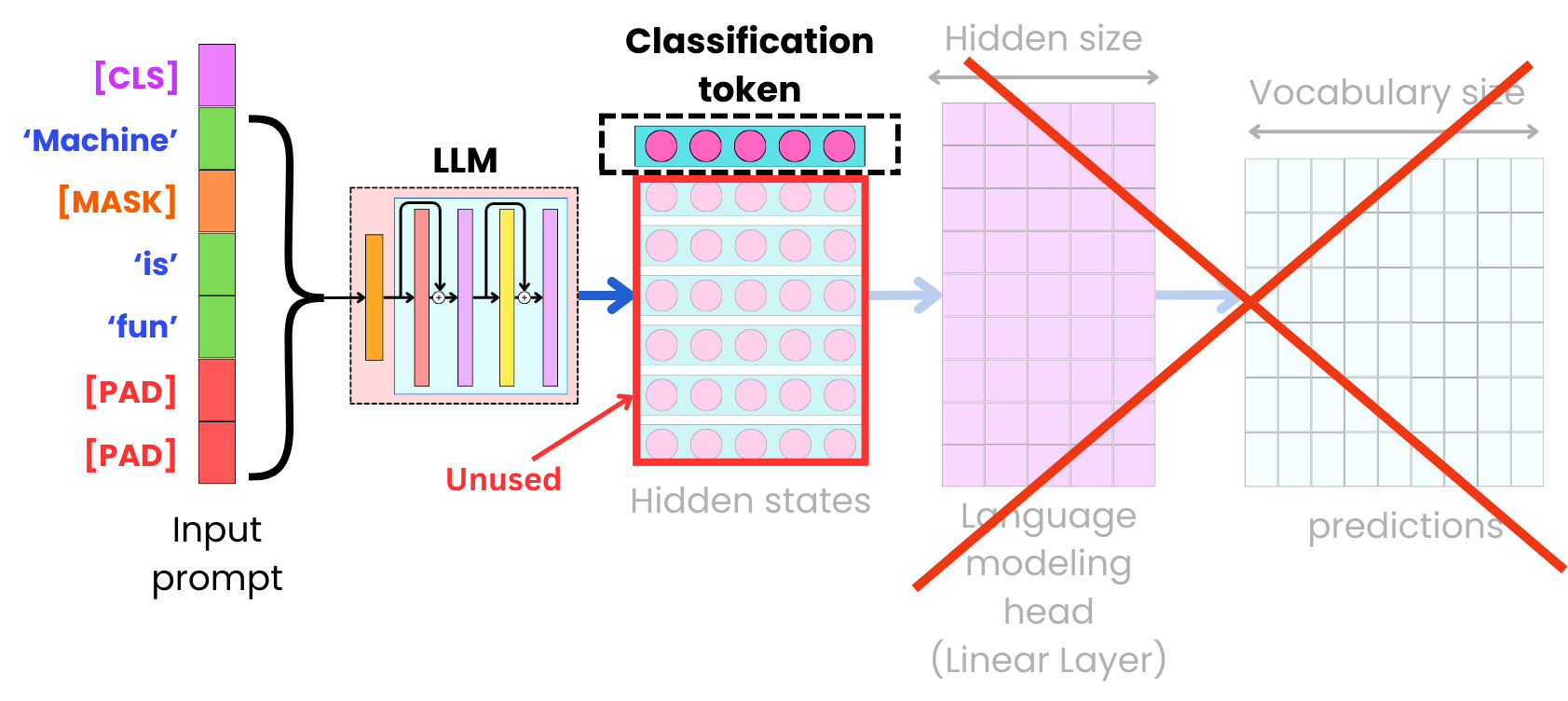
LLMs trained in a masked fashion are not as good at generating coherent texts, but they used to be used as pre-trained models for different learning tasks like text or token classification. That is why we often train them with an added classification token that has the role of capturing the vector representation of the whole input sequence to be used a input to a classifier.
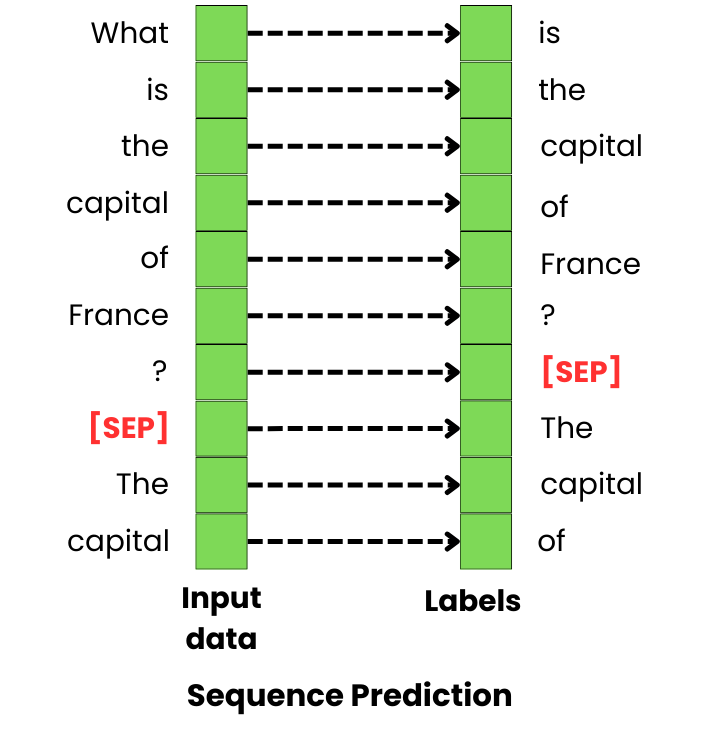
Sequence Prediction
The training process of sequence prediction can be very similar to that of language modeling, but the training data is somewhat different. It is composed of pairs [input sequence, output sequence] that capture the specific type of sequences we want the LLM to generate based on the input. For example, if we want the LLM to become good at answering questions, we are going to specifically show it pairs of [question, answer].
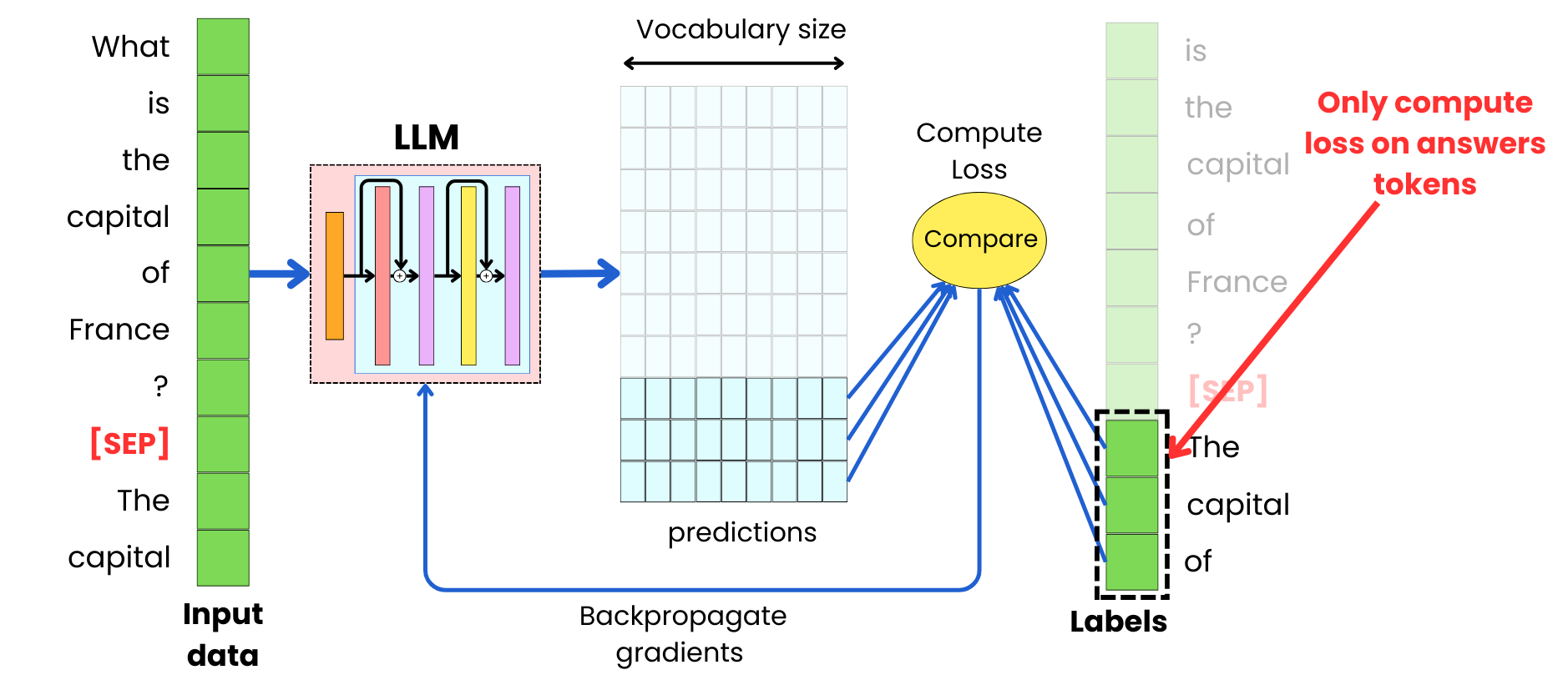
One strategy to ensure that the model's attention is focused on the answers is to compute the loss function using only the predictions and label tokens associated with the output sequences we want the LLM to generate.
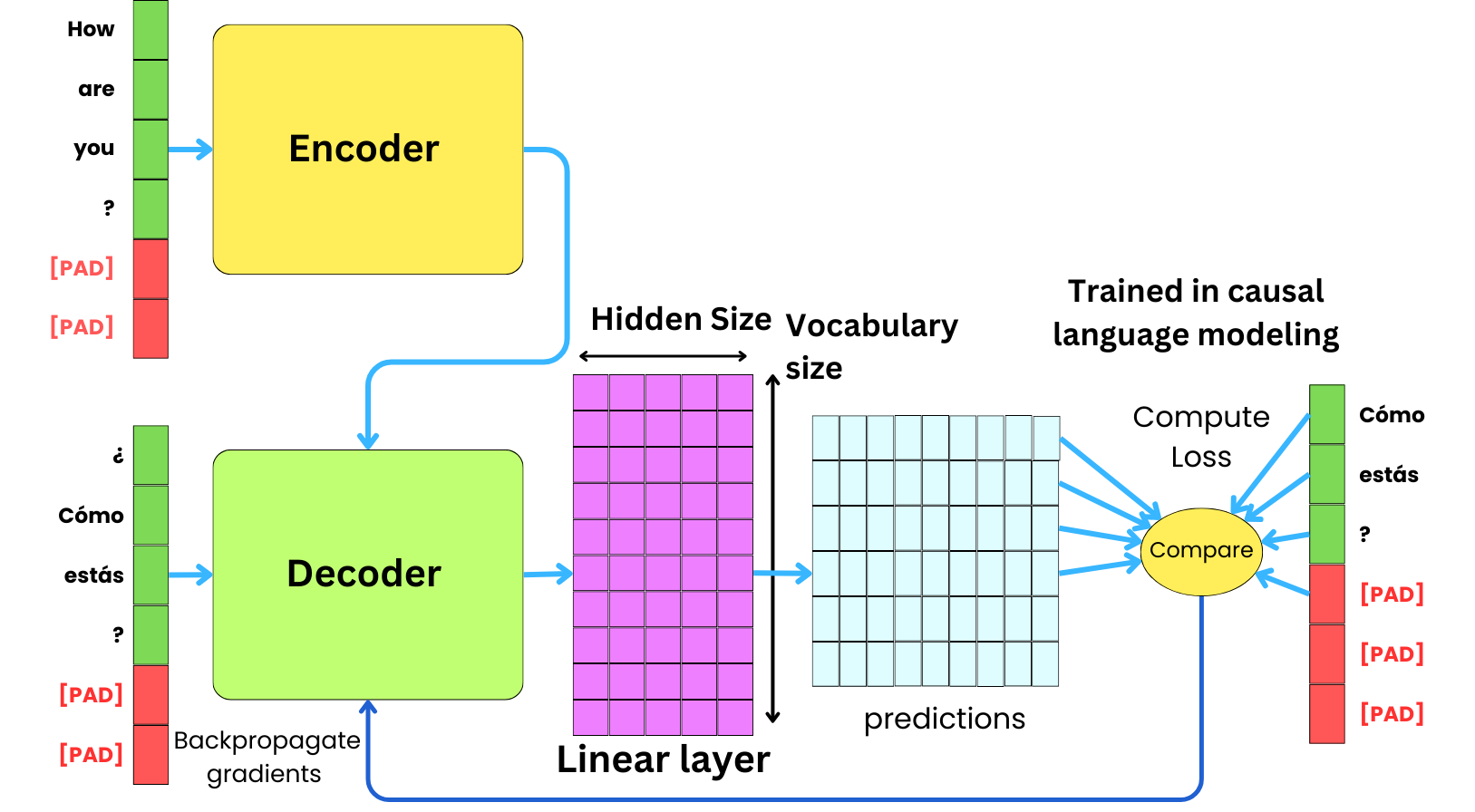
Sometimes, it is possible that the data domain in which we want to generate text is very different from the input data domain. For example, we may want the LLM to generate the Spanish translation of input English text. This is a case of machine translation, but there might be different cases when this happens:
Machine translation: the input data is in a different language than the output one.
Text summarization: the output text always needs to be a short version of the input one.
Question-answering: There might be cases where the LLMs generate answers that are very different from the instructions. For example, code generation based on text instruction
Multimodal modeling: multimodal modeling is a case where the input data can be coming from different data modes (text, images, videos, …), but the output is only in a text format.
For those cases, it could be a good strategy to rely on the encoder-decoder architecture instead of the typical decoder-only architecture. The decoder-only architecture requires mixing the input and output text during the decoding process, while the encoder-decoder architecture allows a separation between the two different data domains.
Text Classification
Listen to this episode with a 7-day free trial
Subscribe to The AiEdge Newsletter to listen to this post and get 7 days of free access to the full post archives.








