


What is Reinforcement Learning
The Bellman Equation
Deep Q-Networks
The Gymnasium Package
Implementing a Deep Q-Network to play Pong
Training on AWS
What is Reinforcement Learning
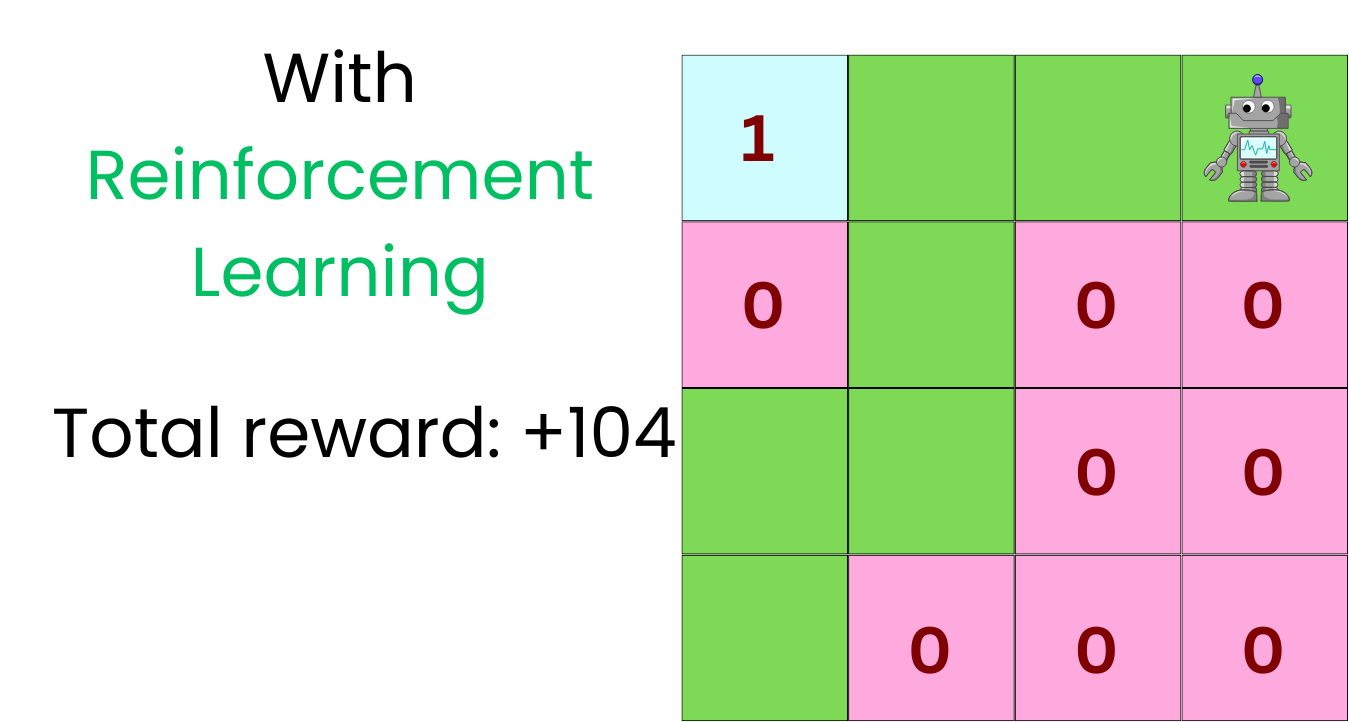
Reinforcement Learning considers all the possible paths and tries to find the path that maximizes the total reward. In the case of the following grid where the points are rewards:

Supervised Learning only considers the next step and would follow the path where each next step is maximized:

However, Reinforcement Learning considers the paths instead of just the next step:
The Bellman Equation
In an environment, we have states, actions, and rewards. From a state, we take an action, we end up in a new state, and we get a reward. We can value each state by following the recurring formula. The value of a state S is the maximum value that I can get by taking an action from the state, moving to a new state S’, getting the corresponding reward ra, and the value V(S’) of that next state:

