


Before Deploying
The Deployment Strategies
Multi-LoRA
The Text Generation Layer
Streaming Applications
Continuous Batching
KV-Caching
Deploying an LLM application with vLLM
Before Deploying
Model Development Lifecycle: Like any other ML model
Deploying an LLM is, in many ways, like any other Machine Learning model application. Deploying a Large Language Model should follow the same best practices and automation as typical ML models. After an ML engineer has validated the potential value of a new idea, a new resulting piece of code should be generated and pushed to the main code base repository. Like any other piece of code, the diff (or PR) is going to lead to automated unit tests. It is customary to automate the retraining of the ML model to have clean offline metrics measurements. Once the model has been retrained and the model performance validated, it is useful to have integration tests to ensure the validation of the end-to-end inference process. After all the offline tests, the model is ready to be tested on production data and can be stored in the model registry.

We can now test the model on production data in our deployment pipeline before serving it to the users if it has satisfactory performance.

Testing the model on production data
There might be many ways to test the model on production data, but here are a couple of typical tests:
Shadow deployment - The idea is to deploy the model to test if the production inferences make sense. When users request to be served model predictions, the requests are sent to both the production model and the new challenger model, but only the production model responds. This is a way to stage model requests and validate that the prediction distribution is similar to the one observed at the training stage. This helps validate part of the serving pipeline prior to releasing the model to users. We cannot really assess the model performance as we expect the production model to affect the outcome of the ground truth.

Canary deployment - one step further than shadow deployment: a full end-to-end test of the serving pipeline. We release the model inferences to a small subset of the users or even internal company users. That is like an integration test in production! But it doesn't tell us anything about model performance.

A/B testing - one step further: we now test the model performance! Typically, we use business metrics that are hard to measure during offline experiments, like revenue or user experience. You route a small percentage of the user base to the challenger model, and you assess its performance against the champion model. Test statistics and p-values are a good statistical framework to have rigorous validation, but I have seen cruder approaches.




The difference between Training and Serving GPU Machines
When working with large language models (LLMs), the requirements for GPU machines used in training versus deployment are quite different.
For training GPU Machines, we typically need:
High Computational Power: Requires high-performance GPUs like NVIDIA A100, V100, or H100, which are optimized for deep learning with extensive tensor core capabilities. Often uses multiple GPUs (e.g., 4, 8, or even more) working in parallel. In distributed training, this can scale to hundreds or thousands of GPUs.
Large Memory Bandwidth: Needs significant GPU memory (at least 32 GB per GPU, often more) to handle large batch sizes and complex model architectures.
Fast Interconnects: Utilizes high-speed interconnects like NVLink or NVSwitch for communication between GPUs, which is essential for synchronizing gradients and parameters in multi-GPU setups.
High Storage Throughput: Requires fast and large storage solutions, like NVMe SSDs, for handling large datasets and checkpoints. Efficient data loading pipelines to keep the GPUs fed with data continuously.
Cooling and Power: Enhanced cooling solutions are necessary due to the heat generated by multiple high-performance GPUs. Higher power requirements to support the intense computational workload.
Software and Tools: Uses frameworks like PyTorch, TensorFlow, or JAX with support for distributed training. Involves tuning hyperparameters, performing mixed precision training, and using advanced optimizers to improve training efficiency.

For serving GPU Machines, we typically need:
Efficiency over Raw Power: Can use less powerful GPUs compared to training, such as NVIDIA T4, A10, or L4, which are optimized for inference workloads. Often, a single GPU or a small number of GPUs can suffice, depending on the deployment scale and requirements.
Memory Utilization: Needs enough memory to load the model and handle input data. While high memory is beneficial, it's not as critical as in training. Models are often optimized and pruned for deployment to reduce memory footprint.
Networking: Less emphasis on high-speed GPU interconnects, but network latency to the deployment machine can be a concern if serving real-time applications.
Storage: Typically, the model size and required data for inference are smaller, reducing the need for extensive storage. Fast read access is still important for loading models quickly.
Cooling and Power: Standard cooling solutions are often adequate unless the deployment involves high inference loads. Lower power requirements compared to training machines.
Software and Tools: Uses inference-optimized frameworks like TensorRT, ONNX Runtime, or specific deployment platforms that support model serving. Models are often quantized or pruned to improve inference speed and reduce resource usage.

Reducing the memory footprint
Not too long ago, the largest Machine Learning models most people would deal with merely reached a few GB in memory size. Because of the massive scale increase, there has been quite a bit of research to reduce the model size while keeping performance up. That is quite important if we want to minimize the serving costs.
Model pruning is about removing unimportant weights from the network. The game is to understand what "important" means in that context. A typical approach is to measure the impact on the loss function of each weight. This can be done easily by looking at the gradient and second-order derivative of the loss. Another way to do it is to use L1 or L2 regularization and get rid of the low-magnitude weights. Removing whole neurons, layers, or filters is called "structured pruning" and is more efficient when it comes to inference speed.

Model quantization is about decreasing parameter precision. There are typically two ways to go about it. When we train or fine-tune the in its quantized form (by dequantizing during the forward and backward pass ), we call this "Quantization-aware training". When we simply quantize the model after training, it is called "Post training quantization", and additional heuristic modifications to the weights can be performed to help performance.

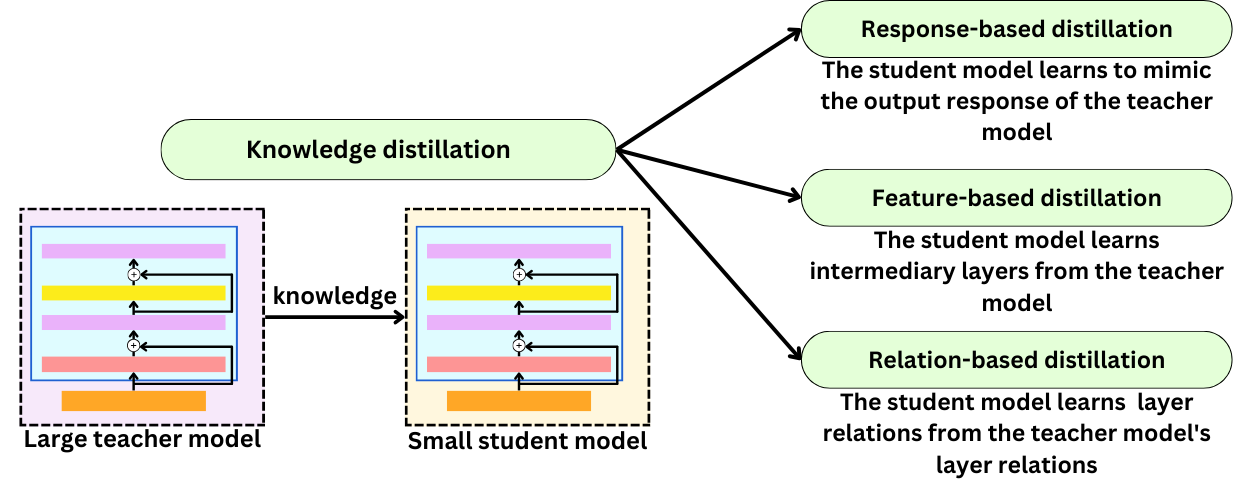
Knowledge distillation is about transferring knowledge from one model to another, typically from a large model to a smaller one. When the student model learns to produce similar output responses, that is response-based distillation. When the student model learns to reproduce similar intermediate layers, it is called feature-based distillation. When the student model learns to reproduce the interaction between layers, it is called relation-based distillation.



The Deployment Strategies
The most common ways to deploy LLMs are as follows:
With a dedicated GPU machine
With a dedicated CPU machine
Serverless deployment
On the Edge
Here are a couple of tools that can help us deploy LLM applications:

