


Interested in understanding how models powering ChatGPT are actually trained from scratch? Let’s dive into it!
The Causal Language Modeling Pretraining Step
The Supervised Learning Fine-Tuning Step
The Reinforcement Learning Fine-Tuning Step
Implementing those Steps with HuggingFace
Overview
To train a Large Language Model to follow instructions, there are 3 steps:
Pretraining (language modeling)
Supervised Fine-tuning (to follow instructions)
Reinforcement Learning (to understand the difference between a good and bad answer)
Those were presented for the first time in the InstructGPT paper in 2022 by OpenAI, a few months before ChatGPT. Let’s look at the differences you would see if the same model were to generate text after the 3 different training steps.

Let’s imagine we have a prompt, "How to be productive". A pre-trained model would generate something like:
"In order to be productive, it's important to stay focused on your goals. Being productive involves managing your time efficiently, prioritizing tasks, and avoiding distractions. It's also helpful to take regular breaks to recharge and maintain a healthy work-life balance."
The pre-trained model learned the structure of language and general knowledge by predicting the next word in a sequence of words. It has the following characteristics:
General advice based on common knowledge.
Broad and not tailored to any specific context or detailed strategies.
The model regurgitates information it has seen during pre-training, which is generic.
The supervised fine-tuned model would generate something like:
"To maximize productivity, start by setting clear, achievable goals. Break down your goals into daily tasks, and use a digital tool or planner to track your progress. Implement the Pomodoro Technique: work for 25 minutes, then take a 5-minute break. Avoid multitasking, as it can reduce the quality of your work and lead to burnout. Stay hydrated and ensure you get 7-9 hours of sleep each night."
The supervised learning step adapts the model to generate text that is more specific or tailored to particular styles or types of tasks based on labeled datasets. We have:
More specific strategies, possibly reflecting the content and style of the dataset used for fine-tuning.
It includes actionable steps that might cater to a particular audience's preferences or needs.
The advice is more structured and could align with expert opinions or best practices.
The Reinforcement Learning model would generate something like:
"To stay productive, first, ensure you're setting realistic goals that align with your long-term objectives. Prioritize tasks that move you closer to these goals and delegate or postpone less critical tasks. Consider using productivity apps to minimize distractions and keep track of deadlines. Remember, productivity isn't about being busy; it's about making meaningful progress on what matters most to you. Finally, make sure to balance hard work with adequate rest to maintain long-term productivity without burnout."
The reinforcement learning fine-tuning step refined the model's outputs to align with desired behaviors, ethical guidelines, or qualitative criteria, often based on feedback loops with human evaluators. Depending on the data we used to train the model, we could have:
Ethically aligned and considers the well-being of the user.
Tailored advice that emphasizes sustainability and personal values.
Could reflect nuanced human feedback aimed at promoting healthy habits and avoiding overwork.
The Causal Language Modeling Pretraining Step
The idea of the causal language modeling pretraining step is to train the model to predict the next word or token in a sequence.

That step requires the most data. For example, Llama 3 was trained using a 15 trillion token. At the time when ChatGPT came out, they used GPT-3 as the pre-trained model, and they used 500 billion tokens with open-source data that captured a large chunk of the internet data. For example, here is the distribution of the data used to train GPT-3:

The way the model is trained is by shifting the input data by one token and by using it as the label to predict. Each input token corresponds to the prediction vector to predict the next token in the sequence.
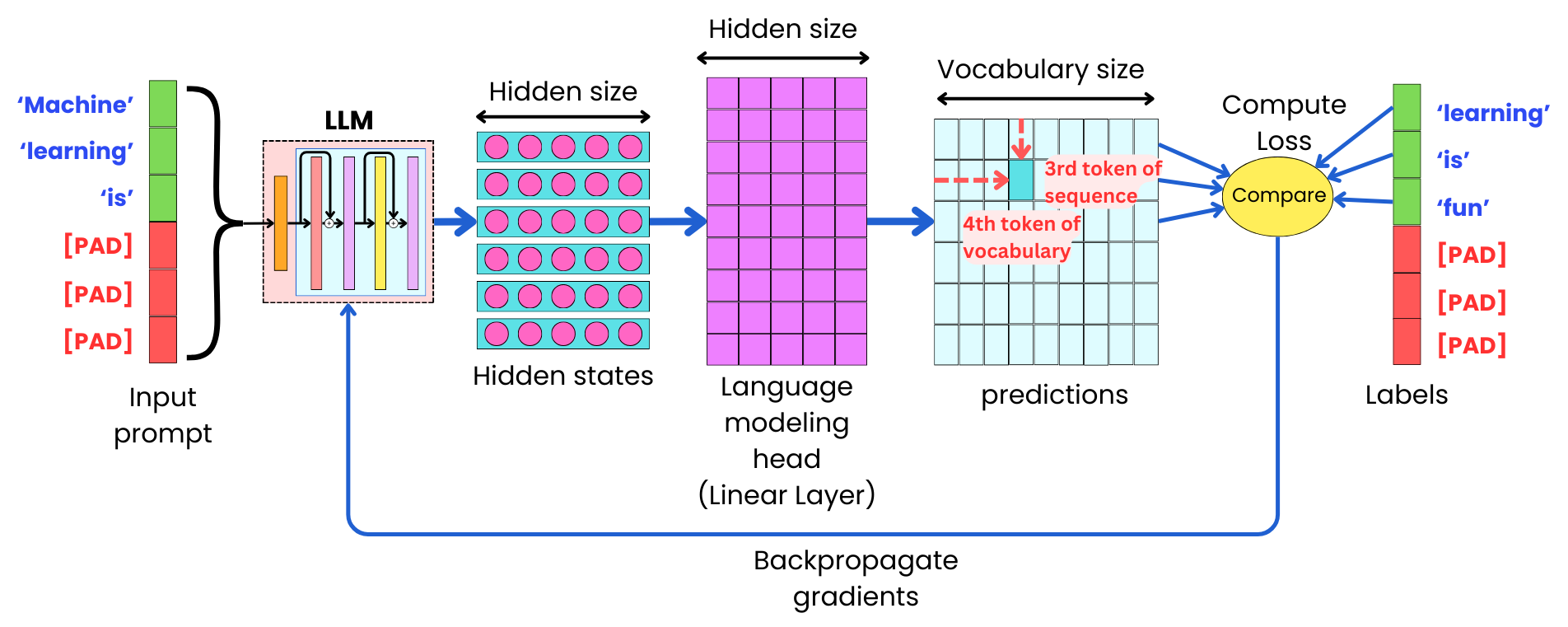
The model is trained in a supervised learning manner as a classifier to predict the next token as one category among all the possible categories represented by the vocabulary.

