


More than ever, we need efficient hardware to accelerate the training process. So, we are going to look at the differences between CPU, GPU, and TPUs. We are going to look at the typical GPU architecture. We also need to explore the strategy to distribute training computations across multiple GPUs for different parallelism strategies. In the end, I am going to show you how we can use the accelerate package by Hugging face to train a model with data parallelism on AWS Sagemaker.
CPU vs GPU vs TPU
The GPU Architecture
Distributed Training
Data Parallelism
Model Parallelism
Zero Redundancy Optimizer Strategy
Distributing Training with the Accelerate Package on AWS Sagemaker
CPU vs GPU vs TPU
There used to be a time when TPUs were much faster than GPUs (“Benchmarking TPU, GPU, and CPU Platforms for Deep Learning”), but the gap is closing with the latest GPUs. TPUs are only effective for large Deep Learning models and long model training time (weeks or months) that require ONLY matrix multiplications (Matrix multiplication means highly parallelizable).
So why do we prefer GPUs or TPUs for deep learning training? A CPU processes instructions on scalar data in an iterative fashion with minimal parallelizable capabilities.

GPU is very good at dealing with vector data structures and can fully parallelize the computation of a dot product between 2 vectors. Matrix multiplication can be expressed as a series of vector dot products, so a GPU is much faster than a CPU at computing matrix multiplication.

A TPU uses a Matrix-Multiply Unit (MMU) that, as opposed to a GPU, reuses vectors that go through dot-products multiple times in matrix multiplication, effectively parallelizing matrix multiplications much more efficiently than a GPU. More recent GPUs are also using matrix multiply-accumulate units but to a lesser extent than TPUs.
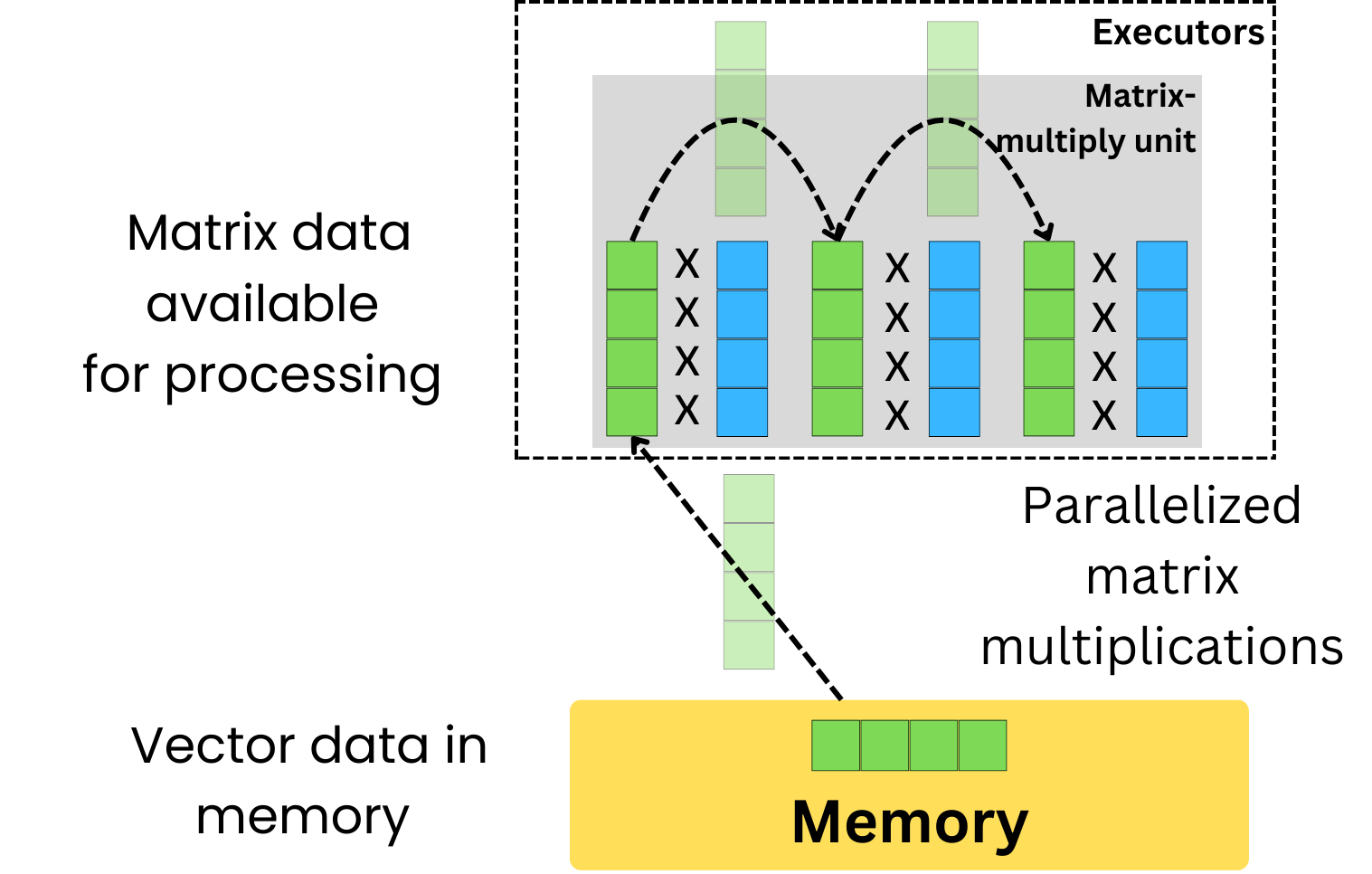
Only deep learning models can really utilize the parallelizable power of TPUs as most ML models are not using matrix multiplications as the underlying algorithmic implementation (Random Forest, GBM, KNN, …).
The GPU Architecture
Here, we are going to grossly simplify the description of the GPU architecture to focus on what tends to matter most for deep learning. In a GPU, the smallest unit of processing is called a “thread“. It can perform simple arithmetic operations like addition, subtraction, multiplication, and division.

In common GPU cards, we have thousands of Cuda cores that can each run multiple threads.

The threads are grouped into thread blocks where each of the threads executes the same operation.

For example, the common NVidia GPU cards tend to have up to 1024 threads per thread block.

Each of the thread blocks has access to a fast shared memory (SRAM).

That memory is small but fast! Most high-end GPUs have between 10 MB to 40 MB.

All the thread blocks can also share a large global memory. In most of the latest GPUs, they have access to faster high-bandwidth memories (HBM).

HBM can be more than a thousand times larger than the SRAM.

The data access to HBM is fast but slower than the SRAM’s:
HBM Bandwidth: 1.5-2.0TB/s
SRAM Bandwidth: 19TB/s ~ 10x HBM
Understanding the way the data gets moved from and to the memories is critical to writing better algorithms. For example, in the attention layer, we need to compute the tensor multiplication between the queries and the keys. The computation gets distributed across thread blocks.
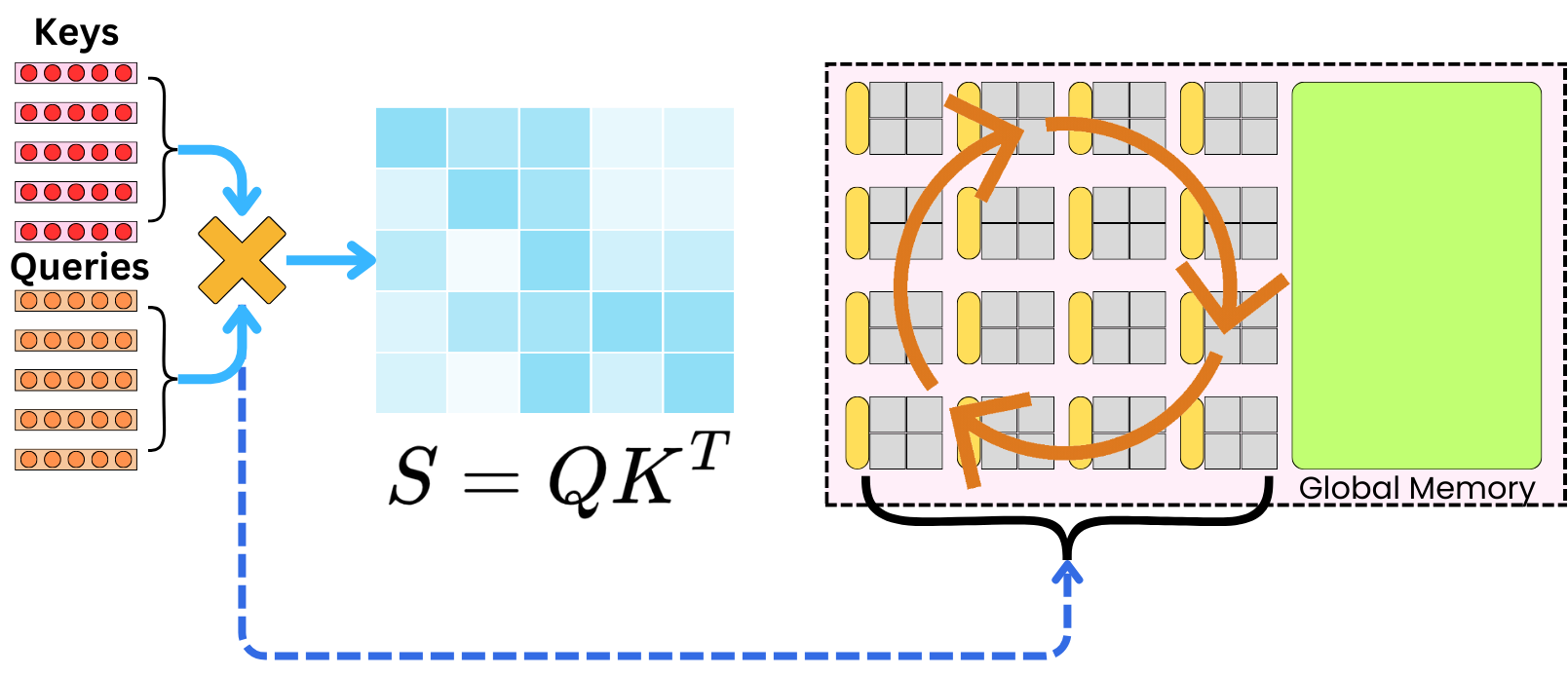
And the resulting variable S gets written into the global memory (or HBM is available).

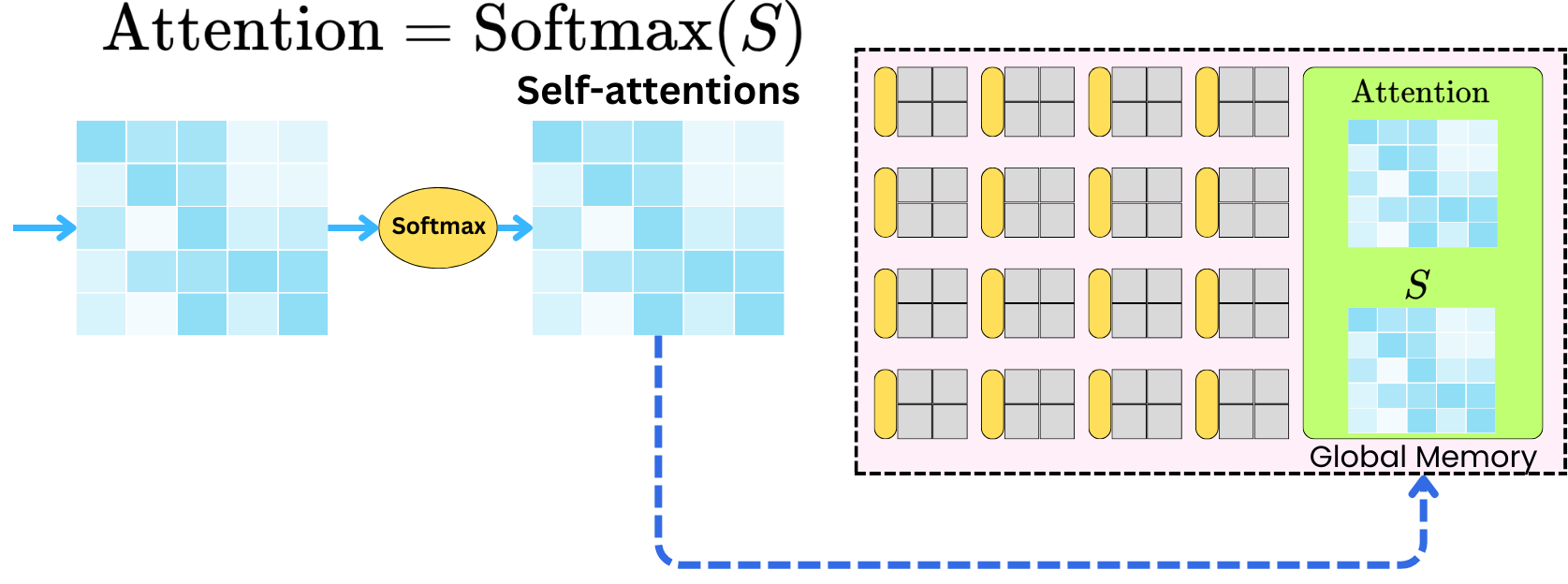
Once this is done, we need to pull the S matrix back onto the threads to compute the softmax transformation.

And again, we need to move the resulting matrix back to the global memory.
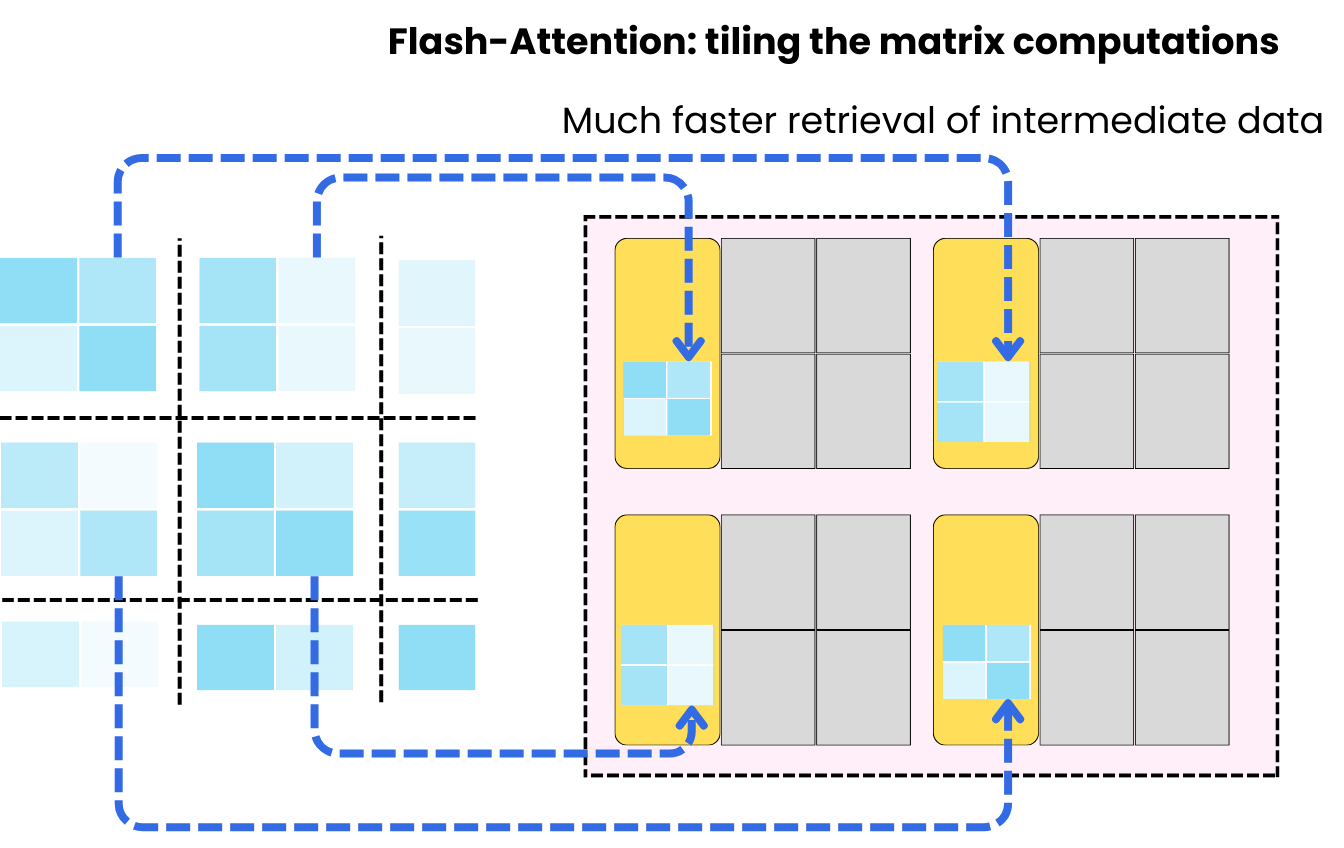
The matrices get moved back and forth between the threads and the global memory because there is no logical way to isolate computations to a thread block and, therefore, utilize the SRAMs to cache intermediary matrices. One strategy that is becoming common now is to tile the computation of the S matrix into smaller matrices such that each small operation can be isolated on a thread block.


This strategy is used in what we call the flash-attention, where we can make more efficient use of the fast access to the SRAM.
Distributed Training
So far, we have talked about how to accelerate computations within one machine, but when we have large models or large data, we need to rely on distributed training. There are mostly 2 approaches to distributed training:
Data Parallelism (significantly speed up training)
Model parallelism (fit very large models onto limited hardware)

